“…ascertain the best market for the subject security, and buy or sell in such a market so that the resultant price to the customer is as favorable as possible…” – FINRA Rule 5310
The days of shouting across a packed trading floor are long gone, but while modern financial dealing may be quieter, executing effectively is now vastly more complex and challenging. Amid the gentle hum of servers, your traders face a high-pressure environment where milliseconds can mean millions of dollars.
In today’s fragmented and highly competitive markets, achieving best execution demands more than a laser focus on price; you must weigh varied factors from order size to venue selection.
Capital market firms are stepping up to this challenge—not just because best execution is vital to proprietary alpha generation but also because it’s critical to delivering good customer outcomes. Yet, while gaining a competitive advantage and attracting more loyal clients are strong calls to action, you must also beware of tightening regulations that make best execution essential, not optional.
Like Odysseus sailing between the monster Scylla and the whirlpool Charybdis, your firm needs to chart the right course for profitability and customer value while avoiding regulatory wrath or the danger of being sucked down by the complexity and costs of compliance.
Whether your focus is equities, derivatives, bonds, forex, or any other type of instrument, read on as we explore what it takes to successfully navigate the challenges of best execution amidst the complexities and pace of today’s capital markets.
Best execution goes beyond price
Markets and trading strategies continuously evolve, as do the standards for best execution. As manual trading gave way to electronic systems in the 1980s, real-time algorithmic approaches in the 2000s, and the modern era of AI and machine learning, any tolerance for errors or delays vanished.
Today’s constant connectivity, combined with automated execution at the speed of thought, means that precision and efficiency are now not exceptional, but expected.
Firms have a vast range of trading venues at their fingertips and a torrent of streaming information, commonly 100,000 ticks per second or more, to leverage for optimal outcomes. Harnessing this data has enabled firms to broaden their view of best execution far beyond price—assessing complex factors like transaction costs and market liquidity in real-time to achieve the best possible results.
Meanwhile, tightening regulatory scrutiny is also raising the bar for execution. Whether it’s MiFID II in the EU or the Dodd-Frank Act and Regulation NMS in the US, financial firms are obliged to act in customers’ best interest when executing orders. Updated rules again define best execution as more than just securing an optimal price—demanding that firms consider a range of factors like transaction cost, speed, and the likelihood of settlement. To demonstrate compliance, firms are also expected to monitor and analyze trading outcomes compared to the market and report on the results.
Best execution: A high-stakes pursuit
For capital market firms engaged in proprietary high-frequency trading, best execution is primarily about accelerating alpha generation, minimizing costs and mitigating risk.
For example, let’s say you’re executing a pairs trading strategy for gold and silver. Suddenly, an exploitable price gap emerges, but you execute at a sub-optimal venue or 100 milliseconds too late—leading to increased slippage, higher fees, and reduced or negated profits.
High-quality execution is similarly important on the risk management side of the equation to minimize losses from sudden and unexpected market movements, like the infamous GameStop short squeeze.
For financial firms that deal with client orders, demonstrating best execution is also vital to attracting and retaining customers. Failure means losing trust, a damaged reputation, and the potential for significant regulatory penalties.
We’ve seen high-profile examples over the past few years, including the SEC fining online brokerage Robinhood $65 million in 2020 for offering customers inferior execution prices. Even more recently, in 2022, FINRA fined Deutsche Bank Securities $2 million for failing to meet best execution obligations after routing orders in a way that created inherent delays and potentially lower fill rates.
Powering best execution
With milliseconds now making the difference between success and failure in the markets, firms need to leverage a wide range of data, technology, and processes to act quickly and confidently, drive better customer outcomes, and ensure regulatory compliance.
Optimizing execution is a multifaceted challenge that must balance trade characteristics, like order size and asset type, with wider market conditions. For instance, firms need to consider factors like:
- Volatility: In turbulent markets with rapid price movements, like cryptocurrencies, firms must be able to monitor and react to changes in real time to achieve best execution
- Liquidity: In more illiquid markets, like fixed-income investments, or when executing large orders, firms must minimize price slippage
- Venue selection: In today’s fragmented markets, the choice of where to execute a trade is crucial, as each venue involves different fees, execution speeds, and liquidity levels
Best execution has evolved from a regulatory obligation to a competitive opportunity. Firms are increasingly leveraging the power of data to deliver and demonstrate optimal outcomes while improving operational efficiency. Key solutions include:
- Real-time data analytics: The ability to ingest, process, and analyze high-frequency data streams gives traders an accurate and up-to-date view of market conditions—letting them keep pace with price, volume, and liquidity indicators across multiple venues and execute with optimal timing. Constant surveillance for sudden market movements or anomalies and the ability to optimize orders on-the-fly can also reduce risk in proprietary trading
- Smart order routing: Based on factors like price, liquidity, and fees, smart order routing can automatically direct trades to the best choice of venue at any given time. It’s also possible to spread orders across multiple venues to minimize the impact on market prices and further optimize execution
- Algorithmic trading: Along with enabling sub-second execution speeds and precise timing, algorithmic trading can also break down large orders into smaller batches to minimize market impact. Additionally, algorithmic trading models enable more advanced strategies that can adapt in real time to changing market conditions
Crucially, these data-driven strategies also support the human side of the best execution equation, giving teams the granular insights needed to monitor performance, review issues, and test controls as per established policies and procedures.
The analytics advantage
When it comes to best execution, your engine room is data analytics. Advanced analytics power the informed choices and agile technologies you need to optimize alpha generation and maximize customer value, especially when leveraging high-frequency trading strategies. Two areas are especially relevant to best execution:
- Pre-trade analytics: Analyzing petabyte-scale datasets with microsecond latency, pre-trade analytics focus on optimizing future order performance by determining the best execution and risk management strategy. This might include complex simulations to assess the market impact of trades, improved transaction cost analysis to minimize fees or slippage, and leveraging real-time data feeds to optimize smart routing decisions. By fully documenting trading decisions, pre-trade analytics also strengthens compliance and operational efficiency
- Post-trade analytics: Best execution is a continuous challenge that demands constant effort. By calculating metrics like effective spread and implementation shortfall, post-trade analytics can benchmark performance against various indices and highlight areas for improvement. Evaluating past trades at a granular level produces vital insights that can help fine-tune strategies for optimal customer value, as well as improve internal risk management
Together, pre- and post-trade analytics offer a powerful solution for achieving best execution—enabling firms to optimize and refine trading strategies and enhance operational efficiency despite increasing compliance demands.
Stacking up for best execution success
By integrating real-time feeds from exchanges, financial institutions, and other data providers, trading desks can execute faster than competitors and deliver better outcomes. However, extracting actionable insights from petabyte-level data fast enough to power moment-to-moment algorithmic or high-frequency trading is no easy task.
A high-performance analytics stack is crucial to capitalize on streaming data by making it fast and easy to load, transform, query, or visualize enormous datasets to find patterns or anomalies. With the ability to ingest large volumes of information, process it in milliseconds, and offer very low-latency response times, a highly performant solution enables your traders to react rapidly to market movements or predict likely outcomes, continuously adjusting orders to ensure best execution.
Such high-speed analytics can also help maintain the real-time records demanded by industry regulations and provide an auditable trail that proves best execution, minimizing the cost of compliance and maintaining operational efficiency. Additionally, streaming analytics can drive continuous trade surveillance, detecting major violations like front-running or churning in real time for even greater peace of mind.
How can KX support with best execution
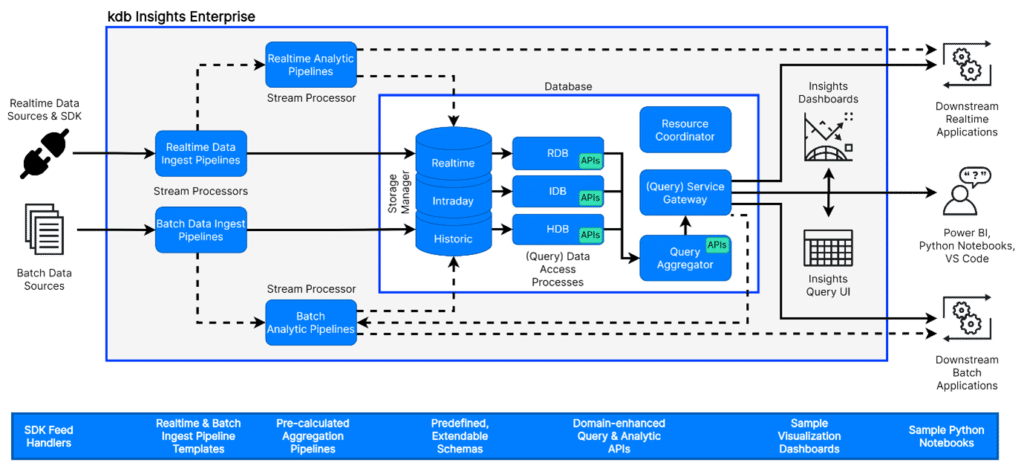
KX helps you meet best execution requirements while turning regulatory obligations into opportunities. Our high-performance database, kdb+, enables real-time analytics and smarter trading decisions. With kdb Insights Enterprise, gain fast query speeds, intuitive tools, and robust reporting for data-driven compliance.
Learn more by watching our webinar with ICE and ExeQution Analytics and learn ‘Six best practices for optimizing trade execution.’
We are here to support you as market complexity and best execution requirements grow, arming you with the advanced technology you need to stay in compliance and ahead of competitors. Learn more about how our solutions enhance pre- and post-trade analytics, or book a demo to see our capabilities in action.