kdb Insights
Make intelligent decisions with all your data, no matter the speed of change.
Additional features
Enhance your kdb Insights experience with Dashboards.
Dashboards
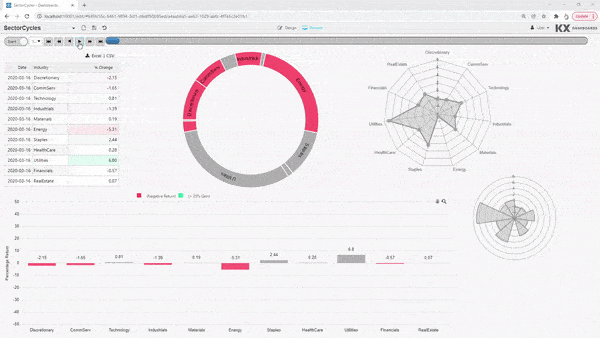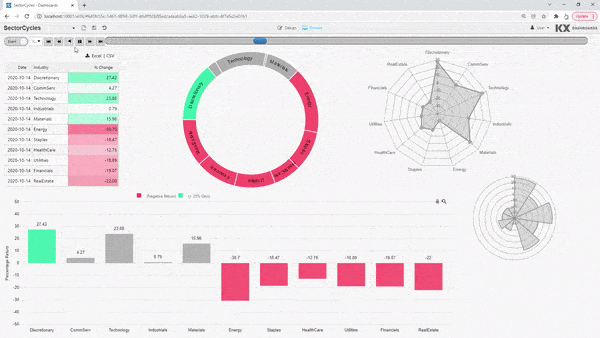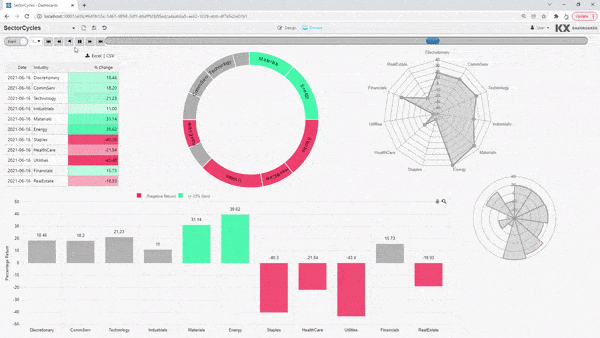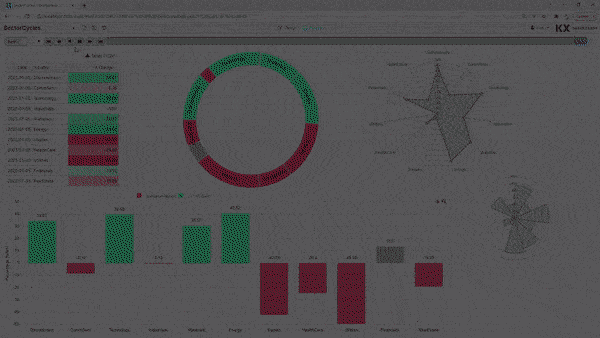
KX Dashboards is an interactive data visualization tool that enables non-technical and power users to query, transform, share, and present live data insights.
Support collaboration and communication throughout your organization with out-of-the-box templates, or choose from over 40 drag and drop widgets to fully customize your visualizations.