Most technologists view using unstructured data (conversations, text, images, video) and LLMs as a surging wave of technology capabilities. But the truth is, it’s more than that: unstructured data adds an element of surprise and serendipity to using data. It decouples left—and right-brain thinking to improve insight generation and decision-making.
A recent MIT study points to the possibility of elevating analytics in this way. It observed 444 participants performing complex tasks associated with communicating key decisions like an analysis plan by a data scientist about how they plan to explore a dataset. The study found that using GenAI increased speed by 44% and improved quality by 20%. The study shows that analysts, data scientists, and decision-makers of all kinds can use unstructured data and GenAI to elevate decision-making when they use unstructured and structured data.
This form of data-fueled decision-making combines the unstructured data required to power right-brain, creative, intuitive, big-picture thinking—with structured data for left-brain analytical, logical, and fact-based insight to inform balanced decision-making.
Here’s how it works.
Unstructured data: A creative, intuitive, big-picture data copilot
Unstructured data powers creative, intuitive, big-picture thinking. Documents and videos are used to tell stories on a stream of consciousness. In contrast to structured data, it’s designed to unfold ideas in a serendipitous flow – a journey from point A to point B, with arcs, turns, and shifts in context.
Navigating unstructured data is similarly serendipitous. It matches how the brain processes fuzzy logic, relationships among ideas, and pattern-matching. The rise of LLMs and generative AI is largely because prompt-based exploration matches how our brains think about the world – you ask questions via prompts, and neural networks predict what might resolve your quandary. Like your brain, neural networks help analyze the big picture, generate new ideas, and connect previously unconnected concepts.
This creative, right-brain computing style is modeled after how our brains work. Warren Mcculloch and Walter Pitts published the seminal paper in 1943 that theorized how computers might mimic our creative brains in A Logical Calculus of the Ideas Immanent in Nervous Activity. In it, they described computing that casts a “net” around data that forms a pattern and sparks creative insight in the human brain. They wrote:
“…Neural events and their relations can be treated using propositional logic. It is found that the behavior of every net can be described in these terms, with the addition of more complicated logical means for nets containing circles, and that for any logical expression satisfying certain conditions, one can find a net behaving in the fashion it describes.”
Eighty years later, neural networks are the foundation of generative AI and machine learning. They create “nets” around data, similar to how humans pose questions. Like the neural pathways in our brain, GenAI uses unstructured data to match patterns.
So, unstructured data provides a new frontier of data exploration, one that complements the creative “nets” that our brains cast naturally over data. But, alone, unstructured data is fuel for our creativity, and it, too, can benefit from some right-brain capabilities. From a data point of view, the right brain is informed by structured data.
Structured data: An analytical, logical, fact-based copilot
Structured data is digested, curated, and correct. The single source of the truth. Structured data is our human attempt to place the world in order and forms the foundation of analytical, logical, fact-based decision-making.
Above all, it must be high-fidelity, clean, secure, and aligned carefully to corporate data structures. Born from the desire to track revenue, costs, and assets, structured data exists to provide an accurate view of physical objects (products, buildings, geography), transactions (purchases, customer interactions, conversations), and companies (employees, reporting hierarchy, distribution networks) and concepts (codes, regulations, and processes). For analytics, structured data is truth serum.
But digested data loses its original fidelity, structure, and serendipity. Yes, structured data shows us that we sold 1,000 units of Widget X last week, but it can’t tell us why customers made those purchasing decisions. It’s not intended to speculate or predict what might happen next. Interpretation is entirely left to the human operator.
By combining access to unstructured and structured data in one place, we gain a new way to combine both the left and right sides brain as we explore data.
This demo explains how our vector database, KDB.AI, works with structured and unstructured data to find similar data across time and meaning, and extend the knowledge of Large Language Models.
Where unstructured exploration meets structured certainty, by example
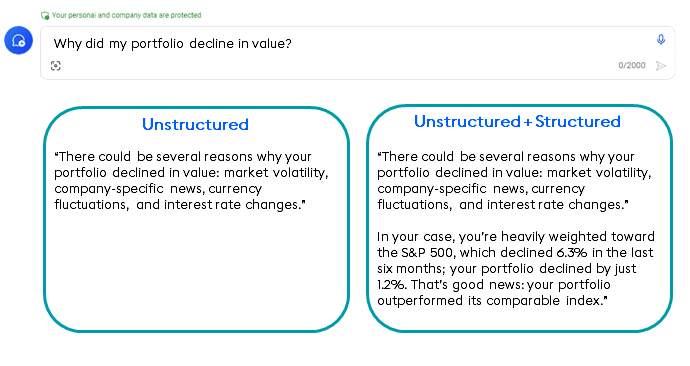
Combining structured and unstructured data marries accuracy with serendipitous discovery for daily judgments. For example, every investor wants to understand why they made or lost money. Generative AI can help answer that data in a generic way (below, left). When we ask unstructured data why our portfolio declined in value, AI uses unstructured data to provide a remarkably good human-based response: general market volatility, company-specific news, and currency fluctuations provide an expansive view of what might have made your portfolio decline in value.
But the problem with unstructured-data-only answers is that they’re generic. Trained on a massive corpus of public data, they supply the most least-common-denominator, generic answers. What we really want to know is why our portfolio declined in value, not an expansive exploration of all the options.
Fusing unstructured data from GenAI with structured data about our portfolios provides the ultimate answer. GenAI, with prompt engineering, interjects the specifics of how your portfolio performed, why your performance varied, and how your choice compared to its comparable index.
The combination of expansive and specific insight is shown in the right column, below:
Bringing left-and-right brain thinking together in one technology backplane is a new, ideal analytical computing model. Creative, yet logical, questions can be asked and answered.
But all of this is harder than it may sound for five reasons.
How to build a bridge between unstructured and structured data
Unstructured and structured data live on different technology islands: unstructured data on Document Island and structured data on Table Island. Until now, different algorithms, databases, and programming interfaces have been used to process each. Hybrid search builds a bridge between Document and Table Island to make left-and-right brain queries possible.
Hybrid search requires five technical elements:
- Hybrid data indexing
- Hybrid query processing
- High-frequency streaming data
- Hybrid time series organization
- Vector embedding-free storage optimization
In our next post, we’ll explore these elements and how they build a bridge between creative and logical data-driven insights. Together, they form a new way of constructing an enterprise data backplane with an AI Factory approach to combine both data types in one hybrid context.
The business possibilities of combining left-and-right brain analytics are as fundamental as the shift in how decision-making works in the context of AI. So, introduce new thinking methods based on new hybrid data technology capabilities for elevated data exploration and decision-making.
Learn how to integrate unstructured and structured data to build scalable Generative AI applications with contextual search at our KDB.AI Learning Hub.