Key Takeaways
- Columnar storage reduces memory bandwidth and CPU cycles.
- Minimal codebase reduces instruction latency and fits entirely in CPU cache.
- In-memory processing enables sub-millisecond analytics, directly querying real-time data in RAM.
- Tiered intelligent storage balances performance and cost by dynamically managing data between memory and disk.
- Memory-mapped files eliminate I/O overhead by enabling direct access to on-disk data.
- In database query execution avoids export latency.
- Vector processing replaces slow row-by-row operations with efficient SIMD data handling.
- Functional programming in q simplifies parallelization and boosts multicore performance.
- Optimized time-series functions like temporal joins and windowing deliver fast, native support for time-based analytics.
Modern data-intensive applications require extreme performance when handling large-scale datasets. Whether analyzing financial transactions, processing IoT telemetry, or massive real-time datasets, speed is everything.
kdb+ has long been recognized as the world’s fastest time series databases, but what makes it so fast? This blog will discuss the key architectural and computational reasons behind its performance advantage.
Columnar storage boosts query speed
Traditional databases store data in rows, which is often inefficient for advanced analytical workloads. This method requires scanning complete rows during querying, creating unnecessary overhead and slow performance. kdb+, in contrast, uses a columnar storage model, ignoring unrelated fields. This leads to faster queries, reduced memory bandwidth usage, and improved CPU cache performance. It is also highly optimized for bulk writes, allowing kdb+ to handle massive datasets with minimal infrastructure efficiently.
For example, consider a dataset with time, temperature, and humidity readings. A columnar database would store all time values in one column, temperature values in another, and humidity values in another. This layout allows for more efficient storage and retrieval, especially when you frequently query specific columns rather than the entire dataset.
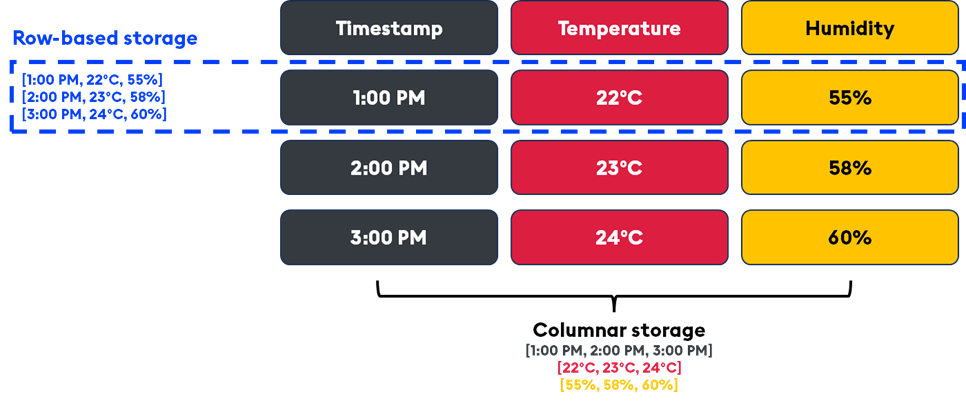
In time-series analysis, most queries target specific columns (e.g. “Show me the temperature readings for the past hour”). In a columnar database, only the relevant column (temperature) needs to be read, which reduces I/O operations and increases query speed. It also allows for faster aggregations and filtering because the data is stored sequentially within each column, enabling highly efficient scan operations.
A small codebase reduces latency
kdb+ is remarkably compact, with a binary of just ~800 KB. This ensures it can fit entirely within the CPU’s cache, significantly reducing latency and eliminating the need to fetch instructions from slower layers such as RAM or disk. This lightweight design contributes to faster startup times and ultra-responsive execution, especially compared to bloated software stacks that carry unnecessary overhead.
The q programming language further amplifies the power of kdb+. It is purpose-built for data processing, with a terse, expressive syntax that minimizes the amount of code that needs to be interpreted and executed. Fewer characters mean less parsing time, which leads directly to faster execution. The compact binary and minimalist language make kdb+ efficient and elegant when interacting with hardware.
In-memory processing ensures sub-millisecond time to insight
kdb+ is designed to ingest and query real-time data directly in RAM, bypassing disk access latency altogether. This ensures sub-millisecond performance for high-speed analytics, making it ideal for time-sensitive use cases like trading systems, fraud detection, and IoT monitoring. kdb+ immediately makes real-time data available for analysis without complex transformation or loading. This enables users to query live data with minimal delay, reducing time to actionable insight.
Performance of complex queries in milliseconds
| Benchmark | kdb+ in-mem | kdb+ on-disk | InfluxDB | TimescaleDB | ClickHouse |
| Mid quote returns | 64 | 113 | 99 | 1614 | 401 |
| Execution volatility | 41 | 51 | 2009 | 324 | 190 |
| Mid quote returns (vol) | 61 | 96 | 94 | 1591 | 407 |
Intelligent storage keeps performance high and costs low
As data ages out of memory, kdb+ seamlessly transitions it to disk-based tiers without interrupting performance or access. This tiered structure balances the need for low latency and long-term scalability, while keeping query performance high.
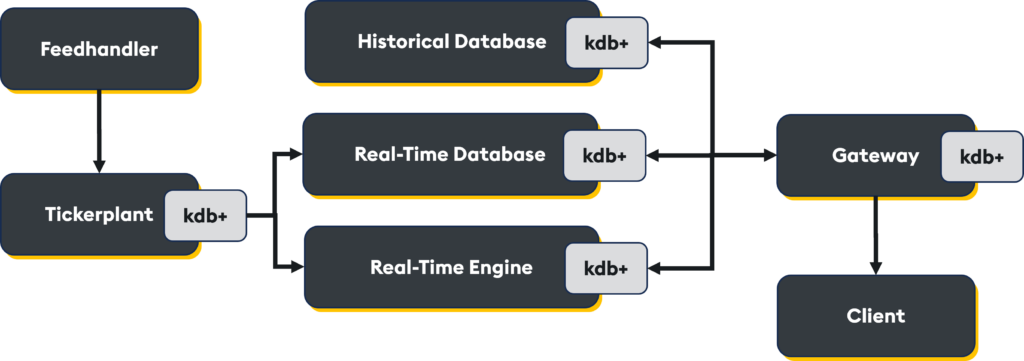
- The real-time database (RDB) is an in-memory data store for ultra-fast querying with sub-millisecond latency. This layer is ideal for the most recent and high-frequency data
- The intraday database (IDB) is used when memory thresholds are reached and comprises a set of disk-based tables optimized for fast querying. The IDB is typically partitioned by small time windows (e.g. 5–60 minutes) to reduce memory pressure and ensure efficient query performance
- The historical database (HDB) is an on-disk, end-of-day, long-term storage solution. It can span petabytes of data and is often used for backtesting, compliance, and batch analytics.
kdb+ is compatible with various storage types, including SSDs, HDDs, NAS, and SANs. It also has advanced disk tiering, ensuring hot data resides on faster SSDs and cooler data on cheaper disks. This helps enterprises balance query performance and storage TCO.
Memory-mapped files reduce I/O overhead
kdb+ uses memory-mapped files to eliminate the overhead of traditional on-disk read/write operations. Instead of copying data from disk into memory and translating it into a usable format, kdb+ maps disk files directly into the process address space to remove deserialization, buffer copying, and translation. This dramatically reduces CPU cycles during read operations and enables efficient OS caching and paging.
In database queries, avoid performance penalties
Unlike traditional architectures that ship data across the network to external tools for processing, kdb+ executes queries within the database using its built-in q language. This minimizes latency and avoids the performance penalty of moving large datasets between systems. By keeping the data and logic in the same process, kdb+ enables real-time analytics at speed and scale, whether scanning tick-by-tick financial data or aggregating IoT signals on the fly.
Example:
// Calculate average trade size over 5 minutes for a real-time feed
q)select time, avg size by 5 xbar time.minute from trades where sym=`AAPL What it shows:
- We’re querying time-series data
- We’re performing a bucketed average, a lightweight analytics operation
- Queries are computed inside the database, with no exporting to Python or Spark.
Why it matters: Moving data is expensive, especially at scale. kdb+ removes that bottleneck entirely, enabling sub-millisecond response times for complex queries on large datasets.
Vector processing reduces looping inefficiencies
In many traditional databases, data is processed row by row. This can be slow and inefficient, especially with large volumes. kdb+, in contrast, performs operations on entire vectors (arrays) using a single instruction, multiple data (SIMD) approach. By doing so, kdb+ can leverage modern CPU architectures optimized for parallel execution. Vectorized processing reduces the need for looping over individual rows, leading to faster execution times by enabling multiple data points to be processed simultaneously. This is particularly beneficial when dealing with large-scale data in real-time analytics.
q) a: 1 2 3 4 5 // Array (vector)
q) a * 2 // Vectorized multiplication
2 4 6 8 10
In kdb+, iterators, which are central to vectorized operations, allow for efficient processing of data collections without the need for explicit loops. This is one of the key reasons kdb+ can handle massive datasets at high speeds: it processes operations on entire blocks of data in memory.
q) L:(1 2 3;10 20;30 40 50;60) // Array of 4 items
q) avg each L
2 15 40 60 Here, the avg each operation is applied to each sublist within the array L, using kdb+’s iterator-based processing.
Functional programming simplifies parallelization
q is a functional programming language that simplifies parallelization by treating functions as first-class citizens and allowing data to be processed without explicit loops. This enables efficient distribution of tasks across multiple CPU cores. When a task can be parallelized, q automatically splits it into smaller tasks that run concurrently on different cores, speeding up execution. You can control the number of worker processes (CPU cores) in q with the \s command.
Here’s how you can test the speed difference by running a task on 1 core vs. 4 cores:
q)v:10000000?1.0 // vector of 10 million floats
q)\s 0 // Set to run on 1 core
q)\t sum v xexp 1.7
150
q)\s 4 // Set to run on 4 cores
q)\t sum v xexp 1.7
49
In this example, running on multiple cores (four cores in this case) significantly reduces the execution time.
Optimized operations for time-series & temporal arithmetic
kdb+ excels in time-series data management, with native support for time-based operations like moving window functions, fuzzy temporal joins, and temporal arithmetic. Temporal joins are complex in traditional databases, often requiring multiple indexing and sorting steps, which can lead to performance bottlenecks. kdb+ leverages its in-memory, columnar architecture and optimized storage structure to perform temporal joins quickly and efficiently.
For example, you can join two tables of time-series data (e.g. trades and quotes) based on timestamps using the aj asof join:
q) quote:([]time:09:29 09:29 09:32 09:33;sym:`JPM`AAPL`JPM`AAPL;ask:30.23 40.20 30.35 40.35;bid:30.20 40.19 30.33 40.32)
q) trade:([]time:09:30 09:31 09:32 09:33 09:34 09:35;sym:`JPM`AAPL`AAPL`JPM`AAPL`JPM;price:30.43 30.45 40.45 30.55 41.00 31.00;size:100 200 200 300 300 600)
q) aj[`sym`time;trade;quote]
time sym price size ask bid
---------------------------------
09:30 JPM 30.43 100 30.23 30.2
09:31 AAPL 30.45 200 40.2 40.19
09:32 AAPL 40.45 200 40.2 40.19
09:33 JPM 30.55 300 30.35 30.33
09:34 AAPL 41 300 40.35 40.32
09:35 JPM 31 600 30.35 30.33
In this example, the aj function ensures that only the trades corresponding to the same sym (stock symbol) are joined, and the most recent available quote is used for each trade.
In conclusion, kdb+ achieves its unmatched speed by combining smart storage techniques, in-memory processing, vectorized execution, and hardware-aware optimizations. Whether handling real-time financial transactions or massive IoT workloads, kdb+ delivers the performance needed for today’s most demanding data applications.
To learn more, visit kx.com or sign up for a free personal edition. You can also read our independent benchmarking report to see how we compare.