

Key Takeaways
- Improved responsiveness: Allows kdb+ servers to serve multiple client queries, boosting responsiveness.
- Eliminates bottlenecks: Enables the gateway to process other requests while waiting for RDB/HDB responses.
- Mitigates errors: Automatically captures and returns errors from worker processes during result aggregation.
- Broad applicability: Enhances performance in trading, risk reporting, market replay, and real-time alerting.
In data-intensive environments such as finance and trading, where responsiveness and speed are vital, KX’s deferred response in kdb+ plays a crucial role. Managing long-running or resource-heavy client requests allows the server to deliver results later, bypassing traditional bottlenecks in which processes must wait for all functions to respond sequentially.
In this blog post, I will break down the concept of deferred response, how it works, and where it is used in real-world scenarios.
What is a deferred response in kdb+?
In a typical client-server interaction with kdb+, the client sends a request, and the server processes and returns the result immediately. This works fine for small or fast queries, but becomes a bottleneck when:
- The request involves a lot of data.
- Processing is computationally heavy.
- The server is managing many simultaneous client connections.
Deferred response allows the server to acknowledge the client’s request immediately and send the result later, once the processing is complete. This ensures server responsiveness and prevents client connections from getting blocked.
To help you understand, let’s revisit the fundamentals of IPC and introduce the synchronous and asynchronous message handling functions .z.pg and .z.ps.
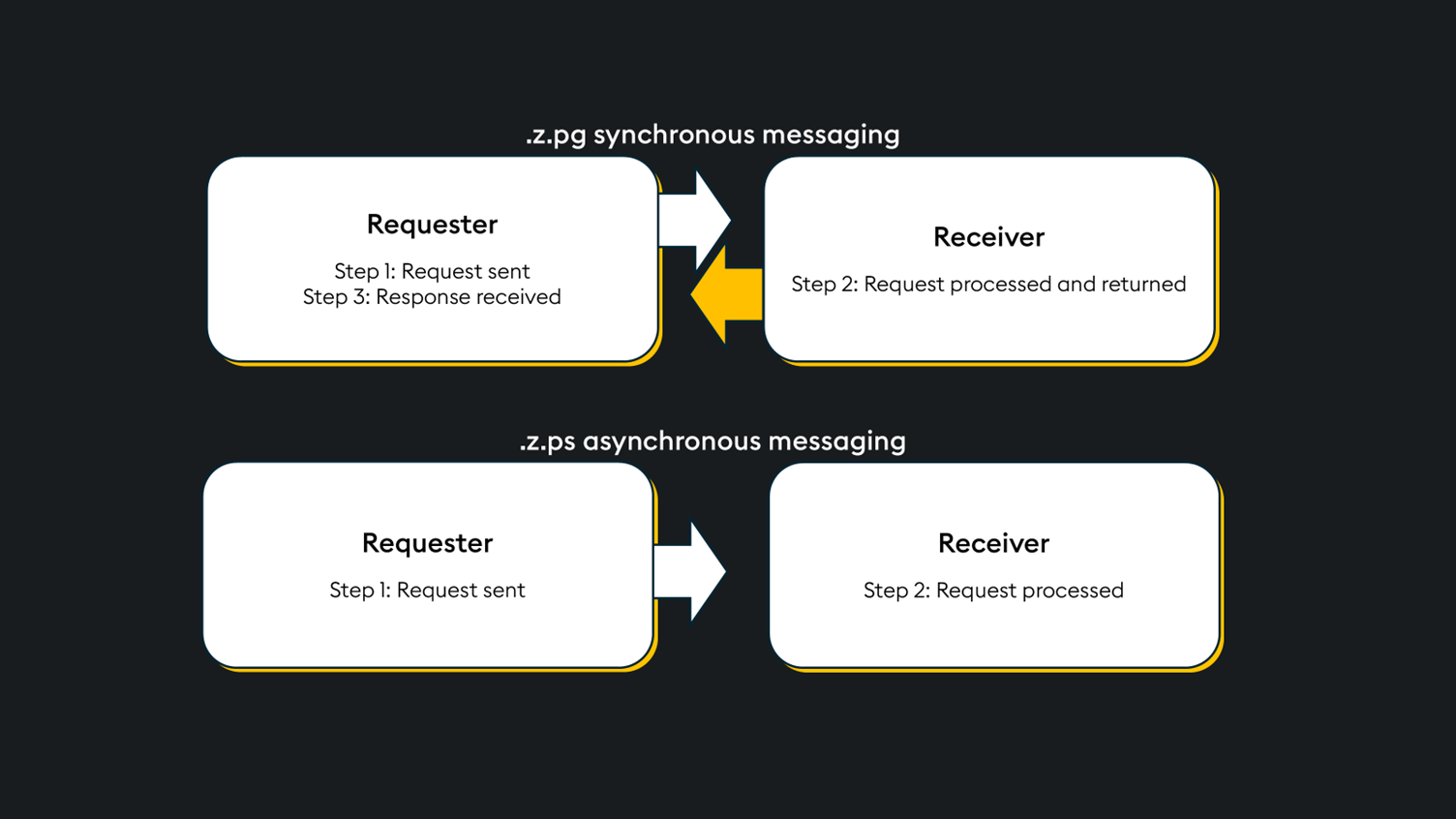
Synchronous messaging uses the .z.pg function to accept the inbound query, process it, and return the results. In contrast, asynchronous message processing occurs on the receiver via the .z.ps function, leaving the requester free to proceed with other tasks.
Consider a simple client-gateway-worker architecture (pictured below). Each process communicates using synchronous messaging to serve data to the client. For simplicity, a set of stored procedures on all processes is defined: A client, a gateway, a real-time database (RDB), and a historical database (HDB).
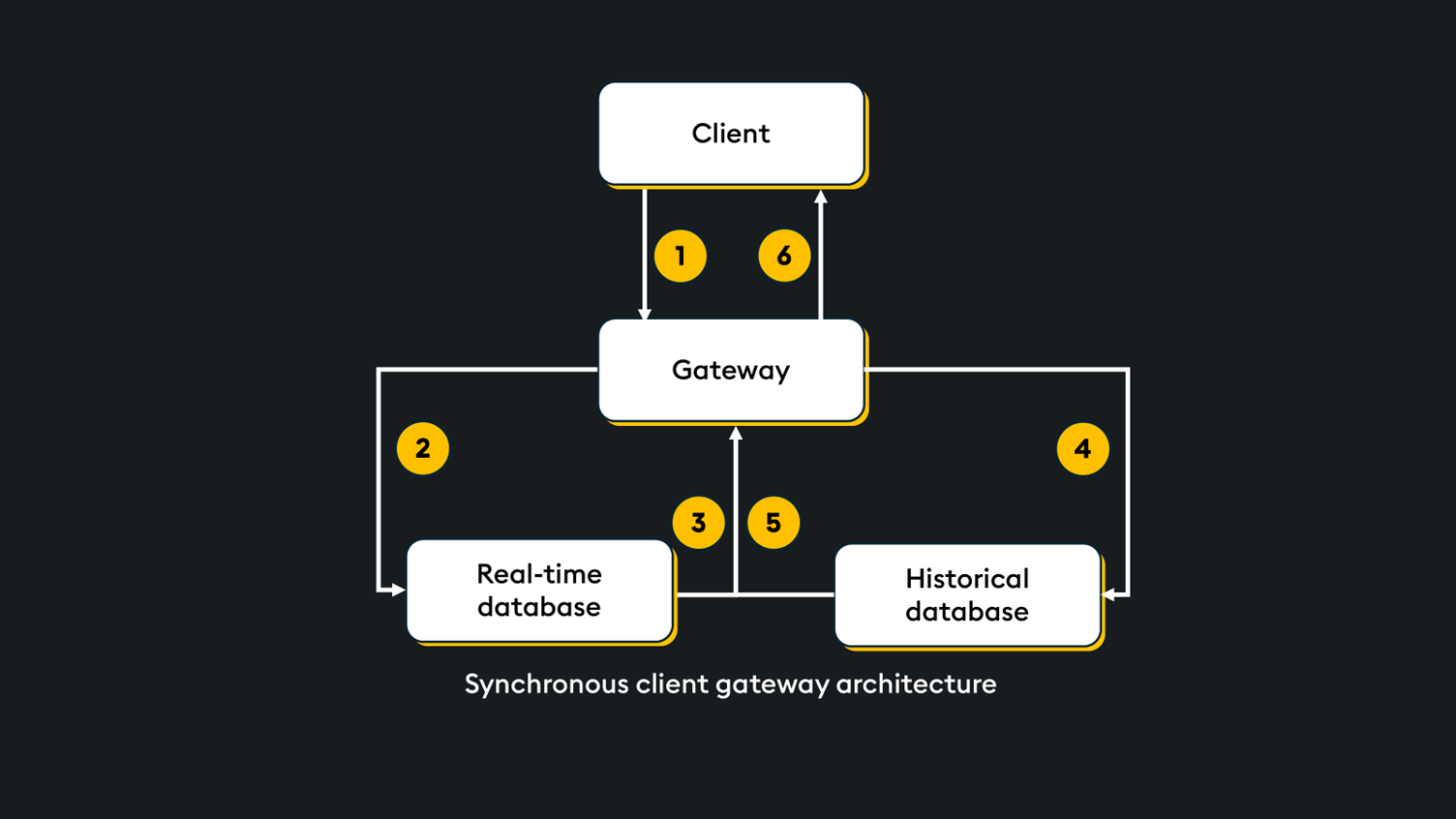
- The client calls a synchronous stored procedure on the gateway.
- The gateway calls for a synchronous response from the RDB.
- The RDB processes and returns a response.
- The gateway calls for a synchronous response from the HDB.
- The HDB processes and returns a response.
- Results are aggregated and returned to the client.
The beauty of this framework is its simplicity; function calls flow in sequence with minimal code needed. However, using synchronous messaging exclusively imposes delays. The gateway process must wait for the stored procedure to finish on the RDB before executing the next instruction on the HDB. As an application scales, with more client processes requesting data, the gateway process becomes the bottleneck.
Synchronous example
//client
hsim:hopen `::5000;
res0:hsim("proc0";`IBM;10);
//gateway
hrdb:hopen `::5001;
hhdb:hopen `::5002;
/return all trades for stock s in the last h hours
/sample usage: proc0[`IBM;10]
proc0:{[s;h]
st:.z.P;
res_rdb:hrdb("proc0";s;h);
res_hdb:hhdb("proc0";s;h);
res:res_rdb upsert res_hdb;
(res;.z.P-st)
};
//sample code on RDB
/return all trades for stock s in the last h hours, need a date column to match with HDB result
proc0:{[s;h]
st:.z.P-`long$h*60*60*(10 xexp 9);
res:`date xcols update date:.z.D from select from trade where sym=s,time>=st;
res
}
//sample code on HDB
/return all trades for stock s in the last h hours
proc0:{[s;h]
st:.z.P-`long$h*60*60*(10 xexp 9);
res:select from trade where date>=`date$st,sym=s,time>=st;
res
}Implementing a deferred response
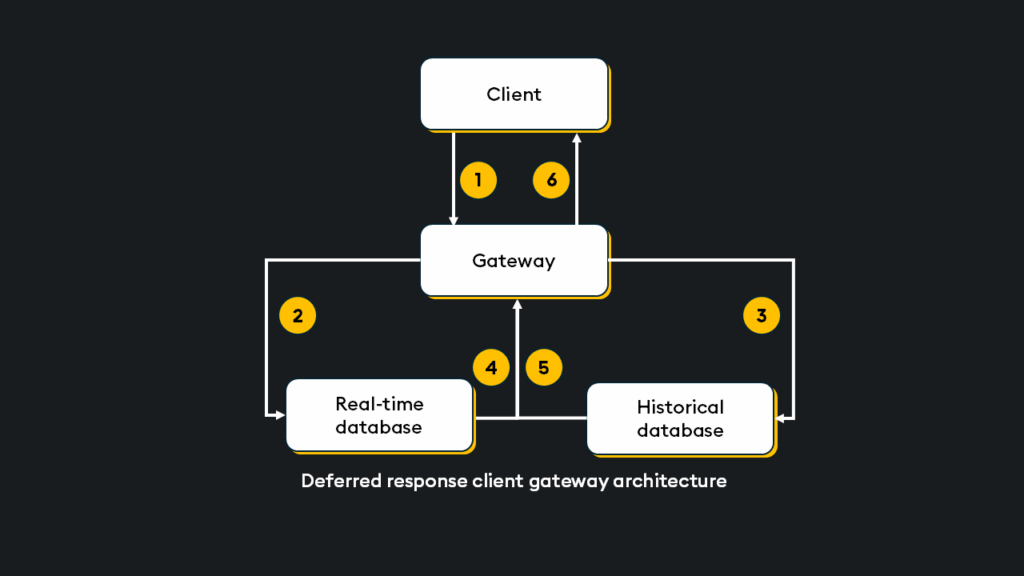
- The client calls a synchronous stored procedure on the gateway.
- The gateway calls for an asynchronous response from the RDB.
- The gateway calls for an asynchronous response from the RDB.
- The RDB processes and asynchronously returns a response.
- The HDB processes and asynchronously returns a response.
- Results are aggregated and returned to the client.
In this instance, the gateway dispatches orders to the RDB/HDB without waiting for a response. This is the “deferred” part of deferred response, meaning that the gateway executes a query but does not return a result immediately.
If you modify.z.pg to include the internal function -30!, .z.pg will not return a result at the end of executing the code.
-30! is added to .z.pg in two steps:
- -30!(::) //terminates the function without returning a value
- -30!(handle;isError;msg) //used to publish the message at given opportunity
//Default Definition
.z.pg:{[query]value query} //argument x has been replaced with query for clarity
//Deferred Response Definition
.z.pg:{[query]
st:.z.P;
sp:query[0];
remoteFunction:{[clntHandle;query;st;sp]
neg[.z.w](`callback;clntHandle;@[(0b;)value@;query;{[errorString](1b;errorString)}];st;sp)
};
neg[workerHandles]@\:(remoteFunction;.z.w;query;st;sp); / send the query to each worker
-30!(::); / defer sending a response message - return value of .z.pg is ignored
}The default behavior of .z.pg is to return the query result. In a simple set-up, the stored procedure is defined outside of .z.pg and executed as part of the argument passed to the function. By contrast, the deferred response example .z.pg has been significantly modified.
.z.pg defines remoteFunction, which will execute on each worker and call the respective stored procedure. Each remoteFunction call passes asynchronously before the message handler terminates with -30!(::).
RemoteFunction is a proxy for the default .z.pg definition by calling the value on the stored procedure (query). Additionally, the stored procedures are no longer required to be defined on the gateway. Once remoteFunction finishes, the result return to the function callback via the preserved handle stored in .z.w.
Adding -30!(::) stops .z.pg from returning, leaving the gateway free to receive further synchronous queries. However, once the RDB/HDB worker processes have results to publish, they must call back to the gateway as per the definition of .z.pg.
The function callback, defined on the gateway, collects results, aggregates them, and returns them to the client, generalizing the work originally carried out by the stored procedures.
Once the results are returned and aggregated, the -30!(handle;isError;msg), is called to return the result. With error handling built into the response mechanism, if either worker error, it’s propagated to the client.
In addition, the handle argument must be defined in .z.W and will wait for a response or generate an error.
callback:{[clientHandle;result;st;sp]
pending[clientHandle],:enlist result;
if[count[workerHandles]=count pending clientHandle;
isError:0<sum pending[clientHandle][;0];
result:pending[clientHandle][;1];
reduceFunction:reduceFunctionDict[sp];
r:$[isError;{first x where 10h=type each x};reduceFunction]result;
-30!(clientHandle;isError;(r;.z.P-st));
pending[clientHandle]:()
]
}Once the workers return all results for a client handle, the message is explicitly sent via 30!(handle;isError;msg). Until the client handle receives a response via -30! it will not unblock, which can be validated by trying to asynchronously flush the handle from the gateway side using neg[h]””.
The response is then embedded at the end of the callback function; however, it can be placed inside any function and called at will with the appropriate arguments.
A trivial example would be to have it always return 1.
//gateway
callback:{[clientHandle;result;st] pending[clientHandle],:enlist result}
pending:()!()
flushRes:{[clientHandle]-30!(clientHandle;0b;1)}
//client
h(“proc1”;`IBM)
//gateway
pending
8| 0b +`sym`MAX!(,`IBM;,99.99993) 0b +`sym`MAX!(,`IBM;,99.99996)
flushRes[8i]
//client
1Including -30! unlocks a deferred response and ensures the gateway is no longer the bottleneck when receiving and publishing requests.
Typical use cases
- High-frequency trading (Real-time + historical data aggregation): A HFT service requests real-time (RDB) and historical (HDB) trade data for analytics. Without deferred response, the gateway has to query the RDB and wait for a response before querying the HDB. If either database is slow or under load, the entire request blocks the gateway and delays additional client requests. By using deferred response, the gateway can send HDB and RDB queries asynchronously, accepting other requests while processing occurs.
- Period-end risk reporting (Batch request from many clients): Dozens of risk analysts submit heavy queries for complex risk calculations at the end of the day. Each request consumes a synchronous thread without deferred response, potentially leading to a gateway bottleneck and slow or failed responses. With deferred response, however, the gateway can distribute the workload to multiple workers, with each risk calculation proceeding independently.
- Market replay (Large data retrieval by strategy developers): Strategy developers replay tick data across multiple days for backtesting. Without a deferred response, the queries could span multiple partitions or storage locations, delaying users’ queries of unrelated symbols or dates. With a deferred response, the gateway dispatches replay queries to HDB nodes asynchronously before aggregating results to clients. This enables parallel processing of computationally expensive operations while maintaining an interactive environment.
- IoT or sensor monitoring (High write volume + analytics): IoT applications can write millions of sensor updates per minute while simultaneously serving analytical queries to users. Without deferred response, analytical queries may fail alongside heavy inserts. Similarly, latency-sensitive writes can degrade when the server is busy with queries. With deferred response, writes continue in real-time with analytical queries handed off to worker processes, balancing real-time ingestion with responsive analytics, even under load.
- Real-time alerting (Event matching + notification): A system monitors live market telemetry, notifying users when defined conditions are flagged. Without deferred response, alerts require synchronous evaluation and the joining of real-time and historical data. Each alert evaluation runs asynchronously with deferred response, ensuring timely alert delivery without dropping or delaying incoming evaluations.
The concept of deferred response in kdb+ represents a significant evolution in handling high-load, high-latency data environments typical of financial systems, sensor networks, and analytics platforms. Systems gain flexibility, throughput, and resilience by decoupling query dispatch from result return. Offloading processing to worker nodes and reassembling results via a structured callback mechanism avoids synchronous bottlenecks. This approach ensures that critical server components like gateways remain responsive and scalable under stress.
Real-world use cases demonstrate the practical benefits, from ensuring responsive trading dashboards to balancing live sensor ingestion with complex analytical queries. Ultimately, deferred response enables kdb+ systems to meet the demands of modern data-intensive workloads without compromising performance or reliability.
To learn more, visit kx.com or sign up for a free personal edition. You can also read our independent benchmarking report and see how we compare against other TSDBs.


