

Key Takeaways
- Hybrid data computing combines structured and unstructured data to guide Generative AI models, significantly improving accuracy and reliability.
- Research shows that using a semantic data layer with Generative AI makes answers three times more accurate than relying solely on an LLM with SQL.
- Hybrid query processing fuses structured data, similarity search, and LLM capabilities to provide precise, context-aware responses to natural language queries.
- Hybrid data indexing integrates traditional structured data indexing with vector embeddings to efficiently search and retrieve vast amounts of unstructured data.
- A well-optimized hybrid computing system can drastically reduce costs, improve efficiency, and scale AI-driven insights across industries.
New research shows that using semantically structured data with generative AI makes answers three times more accurate than a Large Language Model (LLM) with SQL. Unfortunately, traditional databases and LLMs aren’t designed to work together, and building a bridge over that divide is hard.
Vector databases have emerged to fill that gap. But bolt-on vector search isn’t enough to improve query accuracy, simplify prompt engineering, or make building GenAI applications more cost-effective. A better solution is a hybrid approach that uses data as guide rails for accuracy.
Here’s a fresh look at how hybrid data computing helps deliver more accurate GenAI applications.
What is hybrid data, and why does it matter?
Hybrid computing is a style of building applications that fuses unstructured and structured data to capture, organize, and process data. Sounds simple, right?
It’s not.
Structured and unstructured data have different characteristics: structured data is carefully curated, accurate, and secure. Unstructured data and LLMs are used for serendipitous exploration. Combining them is an exercise left to the developer.
A recent MIT study showed that using Generative AI with unstructured data increased speed-to-insight by 44% and quality by 20%. The study studied nontrivial critical thinking tasks like planning and exploring a data set by data scientists. It revealed that unstructured data helps analysts, data scientists, HR leaders, and executives make and communicate better decisions.
However, the study also showed that those LLM-generated answers were often wrong, and 68% of participants didn’t bother to check the answers. For GenAI, inaccuracies are partly by design: neural networks mimic how our brains work. Like humans, they make mistakes, hallucinate, and interpret questions incorrectly.
For most enterprise applications, such inaccuracies are unacceptable. Hybrid computing can help guide LLMs to accurate, secure, reliable, creative, and serendipitous responses. But how do you create these hybrid computing systems that leverage the best of both worlds?
Three elements of hybrid data computing
A hybrid computing system has three elements:
1. Hybrid query processing
2. Semantic data layer
3. Hybrid data indexing
Let’s explore each.
Hybrid query processing
Hybrid data computing aims to use structured and unstructured data as a single organism to provide accurate responses to natural language queries. Using structured data to guide LLM responses is the first element of a hybrid model.
This demo explains how our vector database, KDB.AI, works with structured and unstructured data to find similar data across time and meaning, and extend the knowledge of Large Language Models.
For example, imagine our application answers prompts like “Why did my portfolio decline in value?” Using an LLM by itself yields a generic answer (on the left in the diagram below): market volatility, company news, currency fluctuations, or interest rate changes might be the source of a dip in your portfolio’s value.
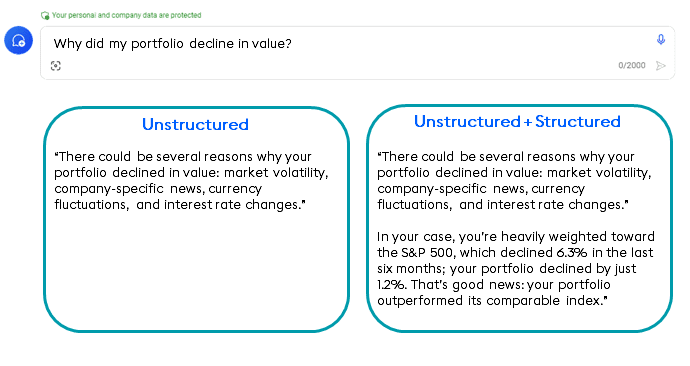
But we don’t want a generic LLM-generated answer – any public LLM can give us that. We want to know why MY portfolio declined and how MY performance relates to similar portfolios. That answer (on the right) is born by fusing structured data, similarity search, and LLM data in one hybrid system.
The first stage of answering this query is to examine the portfolio we’re interested in and compare it to similar portfolios. We find the account ID with a standard relational database lookup to do this. Then, we use vector embeddings to find portfolios similar to our own. This structured data query stage is shown at the top:
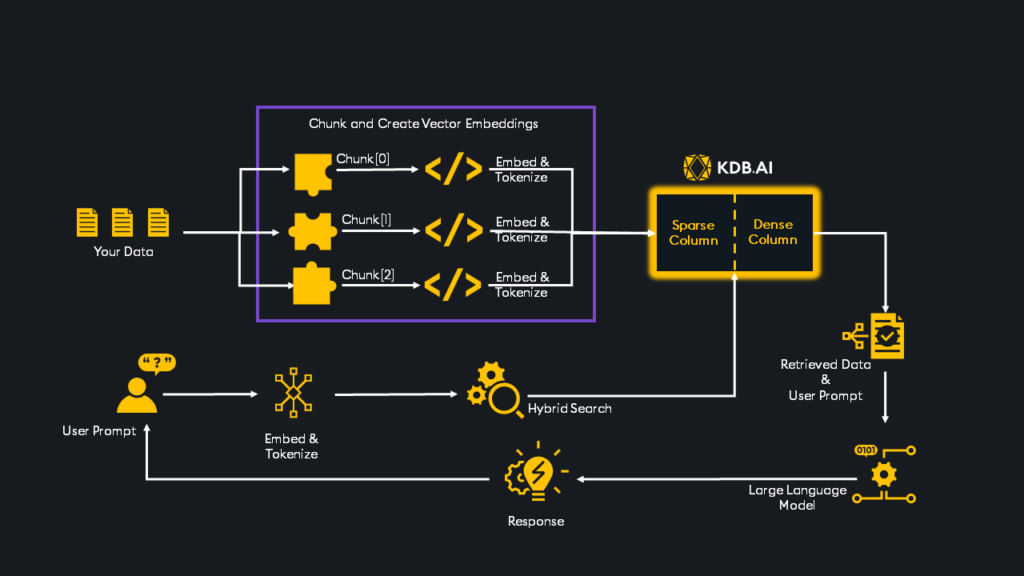
Once the context is established, the hybrid system forwards data to our LLM to formulate the language-based answer we see above as one answer. In this way, hybrid query processing combines accuracy, similarity, and prompt-based answers to provide GenAI answers powered by structured data.
Semantic data layer
When answering prompts with structured data, the software must understand what data it has on hand to query, its relationships to other data, and how to retrieve and combine it before passing that guidance to the LLM to answer questions. For that, we need a semantic data layer—a roadmap to the structured data the system has at hand. New research from Dataworld showed that LLM systems with this semantic understanding of data are three times more accurate than those without (54% versus 16% accuracy).
A semantic data layer is like a data treasure map that describes the semantics of the business domain and the physical database schema in a knowledge graph. It can include synonyms and labels not expressible in SQL to help convert natural language queries into the right SQL queries needed to satisfy the query.
Researchers argue that this context must be treated as a first-class citizen, managed with metadata like a master data management (MDM) tool or data catalog, or ideally in a knowledge graph architecture. Otherwise, the crucial context that provides accuracy would need to be managed ad hoc.
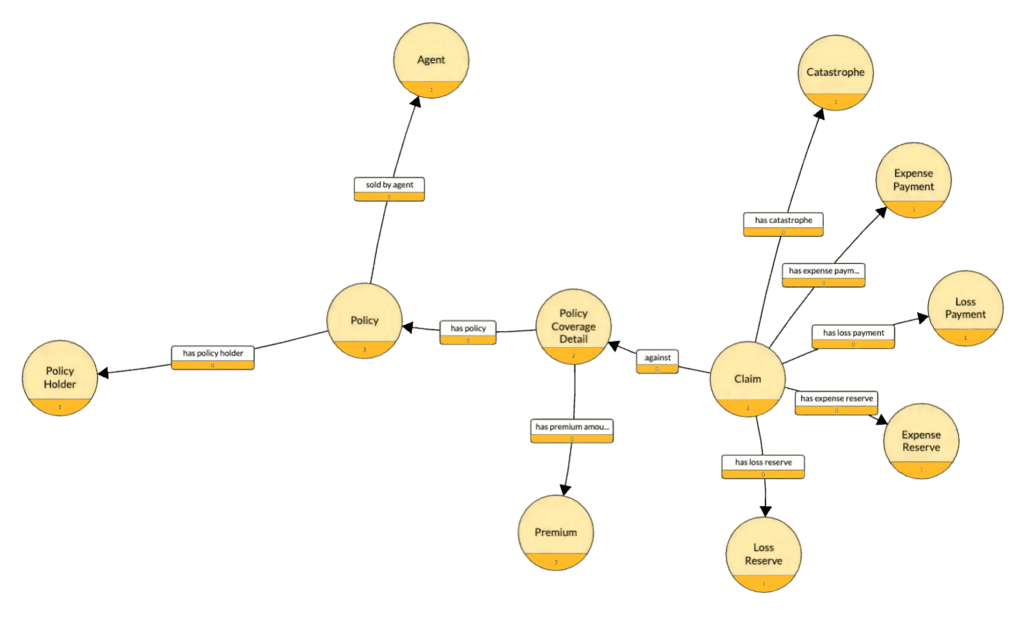
For example, to understand the relationships between an insurance claim, its policy payment, premiums, and profit and loss, you need to know how those data elements are related, like the portion of the graph below. Analysts and programmers traverse this graph to answer questions like, “What is the payout and cost of claim XYZ?” Once they find the claim and its associated policy, they can then understand payout, expenses, and reserves.
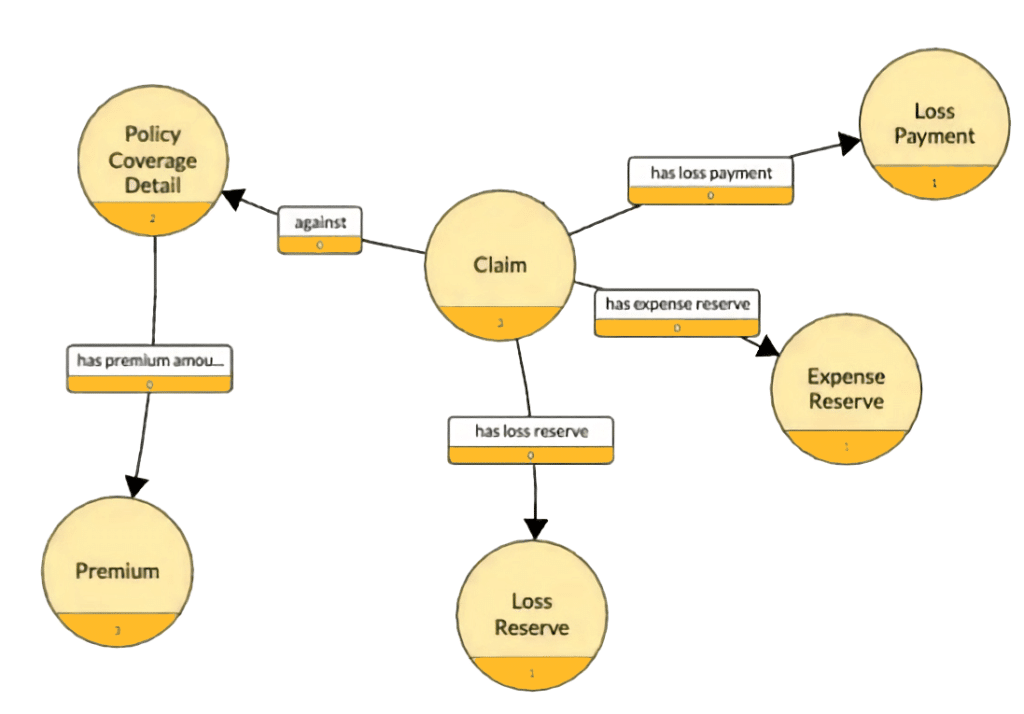
For our portfolio analysis question, a semantic data layer could help our hybrid query system understand the relationship between your portfolio and others, including the investment sector, portfolio size, risk, and other factors described in the semantic data layer. This helps ensure we have the right context and meaning in the data we provide the LLM.
Hybrid data indexing
The third requirement of hybrid computing is that it must work on constantly changing large data sets. Indexes are the fuel that powers all data-oriented computation. A hybrid data computing system must combine traditional structured data indexing, vector embeddings, and LLM data in one high-performance system (see diagram below).
Vector embeddings are a type of data index that uses numerical representations to capture the essence of unstructured data like text, images, or audio. They also extract the semantic relationships that can be integrated with a semantic data layer. Machine learning models create vector embeddings to help make unstructured data searchable.
Vector indexing refers to creating specialized data structures to enable efficient similarity search and retrieval of vector embeddings in a vector database. Like traditional database indexing, vector indexing aims to speed up queries by organizing the vector data to allow fast nearest-neighbor searches.
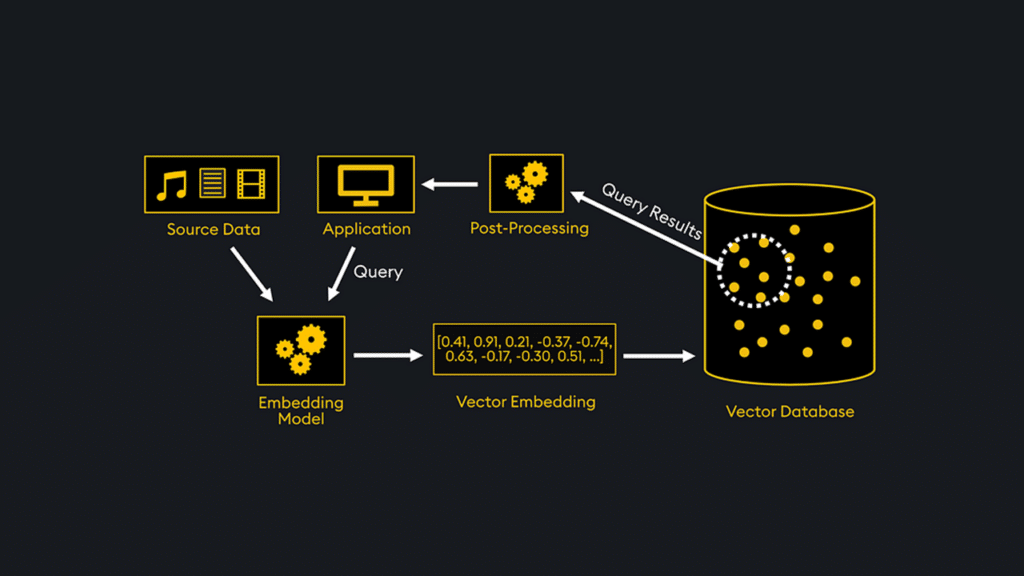
The elephant-in-the-room challenge associated with indexing unstructured data is that there’s so much of it. Financial services firms that analyze companies to make investment decisions must index thousands of pages of unstructured public from SEC filings like 10-K, 10-Q, 8-K, proxy statements, investor calls, and more.
The details of high-performance, scalable hybrid data indexing are outside the scope of this discussion. Still, it is the third foundational requirement of systems that process unstructured and structured data in one place. It is commonly done by “chunking” unstructured data into groups associated with similarly structured data and queried efficiently. Intelligent chunking uses vector embeddings to form a new type of hybrid index that combines unstructured and structured data in one optimized format.
Properly constructed hybrid computation, using hybrid indexing, can result in jaw-dropping economics. In one example using KDB.AI, a hybrid database, queries were found to be 100 times more efficient and 0.001% as expensive per query than non-optimized solutions. As a result, the solution was significantly more efficient, cost-effective and easier to use.
Accurate answers at scale with hybrid data
Hybrid data computing is an essential approach to the next wave of enterprise applications that use LLMs with carefully curated, structured data to produce more accurate, cost-effective answers at scale. The technologies to perform this kind of hybrid system are just now coming to market as vector databases mature and LLM use becomes more prevalent.
Learn how to integrate unstructured and structured data to build scalable GenAI applications with contextual search at our KDB.AI Learning Hub.


