

ポイント
- KDB-X GPU Acceleration now supports nested columns, enabling grouped list-based analytics directly on GPU.
- New GPU profiling APIs help KDB-X users isolate query execution in Nsight Systems and reduce profiling noise.
- Built-in NVTX tracing makes it easier to identify performance bottlenecks across GPU data transfer and query workloads.
- The new memory release threshold setting helps retain GPU memory across sync points, improving repeat query performance.
- Together, these updates make KDB-X GPU Acceleration faster, more observable, and better suited to high-performance time-series analytics.
In our first blog announcing the release of KDB-X GPU Acceleration, we highlighted the ways in which leveraging the GPU module optimizes the heaviest compute operations in a KDB-X system. The fundamentals are clear: push your key columns to device, let .gpu.aj or .gpu.xasc do the heavy lifting, and bring results back only when you need them. The latest release version of this module brings several improvements across the board, including a few useful new additions worth knowing about – namely nested column support, a new profiling API, and a memory tuning knob that, in one of our benchmarks, cut runtime by up to 40%!
Nested columns: Grouping with lists of values
Until now, GPU operations worked only on flat, scalar columns. That covers the majority of tick data use cases, but it leaves out a common and useful pattern – grouping rows into lists. This is the exact type of operation when running something like select y by x from t.
The GPU module now supports this directly, with one level of nesting. The implementation deliberately favors flat data structures internally, since cache locality matters significantly for the highly parallel algorithms running on distributed multi-threaded GPU devices. That’s an implementation detail you won’t see from the q side, but it changes the current depth limit we can support, which will likely bring a lot of extra mileage. Here’s what that looks like in practice:
q)t:([] x:25?5; y:25?10f);
q).gpu.from .gpu.select[;();enlist[`x]!enlist[`x];enlist[`y]!enlist[`y]] .gpu.to t;
x y
------------------------------------------------------
0 3.714973 5.897202 9.550901 2.062569 3.414991
1 6.568734 9.625156 6.158515 7.02455 9.516746 1.169475
... The q equivalent is the familiar 0!select y by x from t – results are identical (note the use of 0! as keyed tables are not yet supported). Moving averages work the same way:
q).gpu.from .gpu.select[;();enlist[`x]!enlist[`x];enlist[`y]!enlist(mavg;3;`y)] .gpu.to t;
x y
-------------------------------------------------------
0 3.714973 4.806087 6.387692 5.836891 5.009487
1 6.568734 8.096945 7.450802 7.60274 7.566603 5.90359
... Same as 0!select 3 mavg y by x from t. The pattern composes cleanly. Group by a column, apply a moving scan, get back nested lists – all happening directly on GPU until you call .gpu.from.
Profiling your GPU workloads
When a GPU pipeline is slower than expected, the problem is rarely the CUDA kernel itself. This usually stems from resource management; how memory is allocated, when kernels are launched, and where the CPU/GPU are waiting on each other. Nsight Systems is an invaluable tool that gives an excellent window into how this is working, and GPU module v2.0 makes it significantly more useful for KDB-X workflows.
If we run a small script doing a couple sums on 10,000,000 rows, we can see the first run of the query is actually slower before leveling out:
$cat profiler_example.q
.gpu:use`kx.gpu;
N:10000000;
t:([]x:N?100i;y:N?100i;z:N?1.;price:N?1.);
expected:0!select a:sum *[z;z], b:sum price + z by x,y from t;
query:{.gpu.from .gpu.select[;();`x`y!`x`y;`a`b!((sum;(*;`z;`z));(sum;(+;`price;`z)))] .gpu.to x};
\t actual:query t;
\t actual:query t;
\t actual:query t;
show expected~actual
\\ Typically, we could just start by profiling with nsys (Nsight Systems), but there is a lot going on and it’s hard to see the interesting bit:
$nsys profile –o example q profiler_example.q -q
Collecting data...
79
44
44
1b
Generating '/tmp/nsys-report-15a1.qdstrm' Press Ctrl-C to stop symbol files downloading [1/1] [========================100%] example.nsys-rep
Generated:
*************************/example.nsys-rep 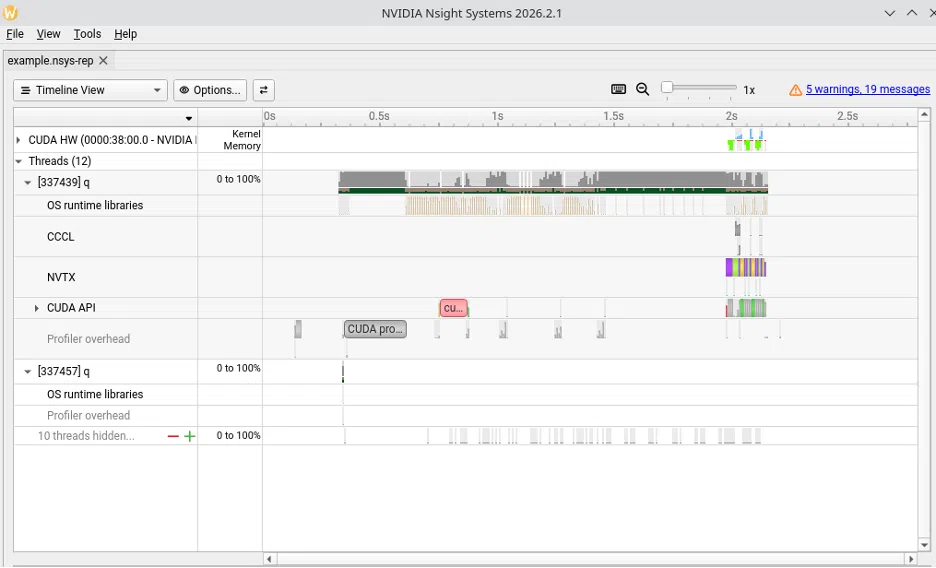
The new entry points within this module come from .gpu.profiler.start[] and .gpu.profiler.stop[], which expose cudaProfilerStart and cudaProfilerStop, respectively. Without these, profiling a q script captures everything, from q startup to data loading, and everything in-between – this ends up with a trace full of noise. Now, leveraging these APIs allows for input of exactly the code you care about, clearly visualizing the relevant bits:
$cat profiler_exampleGpu.q
.gpu:use`kx.gpu;
N:10000000;
t:([]x:N?100i;y:N?100i;z:N?1.;price:N?1.);
expected:0!select a:sum *[z;z], b:sum price + z by x,y from t;
query:{.gpu.from .gpu.select[;();`x`y!`x`y;`a`b!((sum;(*;`z;`z));(sum;(+;`price;`z)))] .gpu.to x};
.gpu.profiler.start[];
\t actual:query t;
\t actual:query t;
\t actual:query t;
.gpu.profiler.stop[];
show expected~actual
\\
$ nsys profile -o example_no_setup --capture-range=cudaProfilerApi q profiler_exampleGpu.q -q
Capture range started in the application.
83
56
44
Capture range ended in the application.
Generating '/tmp/nsys-report-2aa9.qdstrm'
Press Ctrl-C to stop symbol files downloading
[1/1] [0% ] example_no_setup.nsys-repProcessing events...
[1/1] [========================100%] example_no_setup.nsys-rep Generated:
*************************/example_no_setup.nsys-rep 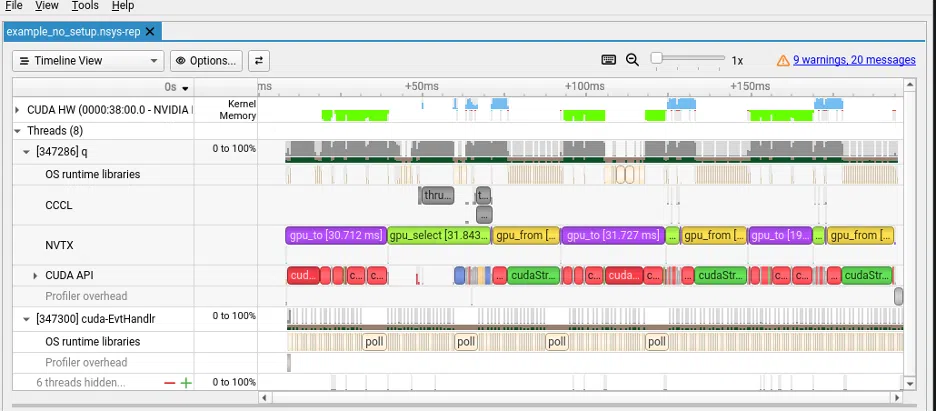
Now our trace shows only the three query executions. We cut directly into what we care about, with no startup overhead and no unrelated work.
From here, we can embed landmarks into our trace using .gpu.nvtx.start and .gpu.nvtx.end. They let you define named ranges that show up as labeled bands in Nsight Systems – we can tweak our profiler_exampleGpu.q script to add these as follows:
gpu.profiler.start[];
\t actual:query t;
rangeID:.gpu.nvtx.start["my query"];
\t actual:query t;
.gpu.nvtx.end[rangeID];
\t actual:query t;
.gpu.profiler.stop[];
show expected~actual
Using the NVTX drop down, we can visualize the range that has been inserted along with its duration:
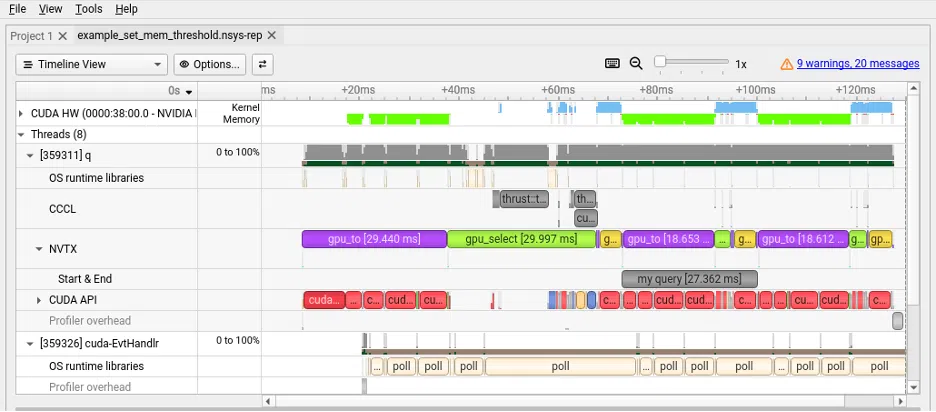
We can see the initial runs of .gpu.to and gpu.select are taking a lot longer, but that is fairly normal as the CUDA driver initializes parts of the system that can be reused. The GPU module already defines some internal NVTX ranges (specifically data transfer and select statements), so the custom ones sit alongside them in the same timeline view. When chasing a latency spike across a multi-step pipeline, being able to see exactly where your workload boundaries fall is genuinely useful.
Tuning memory release behavior
Nsight Systems clearly illustrates the above pattern where the first run of a query is slower, but that is a red herring artifact of initialization, in subsequent runs we see.gpu.from spends most of its time waiting rather than transferring data. The memory pool releases all unused memory at synchronization points, meaning every time .gpu.from syncs to return data to the CPU, the pool frees its reserved memory. The next allocation then goes back to the CUDA driver.
This is where .gpu.setMemRelThres comes into play – this function sets a ceiling on how much memory the pool retains across sync points. It doesn’t cap how much memory can be allocated; just prevents the pool from releasing memory it might need again shortly. Integrating this into the beginning of our example script, our final version (including all profiling injection changes) looks like:
.gpu:use`kx.gpu;
.gpu.setMemRelThres[20*1024*1024*1024] // 20 GiB
N:10000000;
t:([]x:N?100i;y:N?100i;z:N?1.;price:N?1.);
expected:0!select a:sum *[z;z], b:sum price + z by x,y from t;
query:{.gpu.from .gpu.select[;();`x`y!`x`y;`a`b!((sum;(*;`z;`z));(sum;(+;`price;`z)))] .gpu.to x};
gpu.profiler.start[];
\t actual:query t;
rangeID:.gpu.nvtx.start["my query"];
\t actual:query t;
.gpu.nvtx.end[rangeID];
\t actual:query t;
.gpu.profiler.stop[];
show expected~actual
\\
\t actual:query t
64
\t actual:query t
27
\t actual:query t
27 This knocked nearly 40% of the runtime off! The issue of the memory pool releasing unused memory on synchronizations is rendered obsolete by setting the threshold to 20Gb, so nothing is released and the time spent on freeing memory is gone. This is also a small performance increase by avoiding going through the CUDA driver for subsequent allocations. Note that the threshold is set per device, so in a multi-GPU setup its best practice to configure each one explicitly after calling .gpu.setdev (formerly .gpu.sdev).
At very large scale, you’re trading memory overhead for allocation speed. A 20Gb threshold on a 40Gb A100 leaves plenty of room. However, on a smaller device or a workload with genuinely variable memory demands, this should be tuned accordingly.
Device utility function changes
The device management functions have been renamed to avoid confusion of sdev with standard deviation:
| Old Name | New Name |
|---|---|
.gpu.ndev |
.gpu.cntDev |
.gpu.gdev |
.gpu.getDev |
.gpu.sdev |
.gpu.setDev |
.gpu.mdev |
.gpu.memDev |
The behavior is identical – .gpu.cntDev[] still returns the number of available devices, .gpu.memDev[] still returns available memory, and so on. If you have existing scripts that reference the old names, update them before upgrading.
Closing Thoughts
In combination, these changes round out the GPU module in two meaningful ways. Nested column support opens up grouped aggregation patterns that were previously only supported on CPU. Plus, the profiling and memory tuning APIs give users the visibility and control to squeeze more out of the hardware you already have, without guessing at where the time is going.
The initial release set the foundation. This second iteration pulls it off the ground in meaningful ways with expanded functionality. The fastest time-series database in the world just got a whole lot faster – with additional layers to unlock its full potential by leveraging full capabilities of GPU acceleration.
Learn more about KDB-X GPU Acceleration here.
Interested in building yourself? Learn how to leverage GPU Acceleration with your current workloads in our tutorials, which can be found here.


