

Data analysts know, that whether in finance, healthcare, manufacturing or any other industry, efficient handling of time series data helps derive better decision making and enhanced business intelligence. The process however can often be cumbersome and resource intensive due to language limitations, code complexity and high-dimensional data.
In this blog, we will explore the partnership between KX and Databricks and understand how the technologies complement each other in providing a new standard in quantitative research, data modelling and analysis.
Understanding the challenge
SQL, despite its widespread use, often stumbles when interrogating time-based datasets, struggling with intricate temporal relationships and cumbersome joins. Similarly, Python, R, and Spark drown in lines of code when faced with temporal analytics, especially when juggling high-dimensional data.
Furthermore, companies running on-premises servers will often find that they hit a computational ceiling, restricting the types of analyses that can be run. Of course, procurement of new technology is always possible, but that often hinders the ability to react to fast paced market changes.
By leveraging the lightning-fast performance of kdb+ and our Python library (PyKX), Databricks users can now enhance their data-driven models directly within their Databricks environment via our powerful columnar and functional programming capability, without requiring q language expertise.
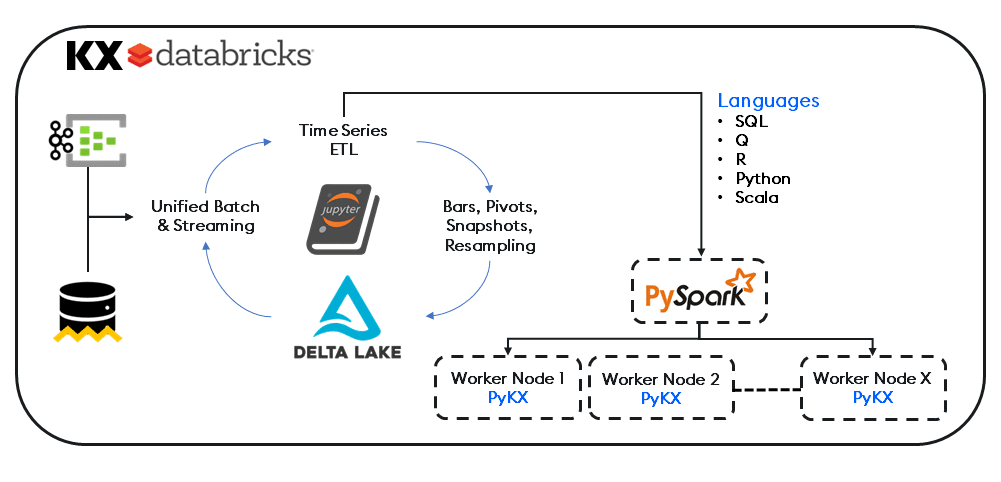
Integrating into PySpark and existing data pipelines as an in-memory time-series engine, KX eliminates the need for external dependencies, connecting external sources to kdb+ using PyKX, Pandas or our APIs. And with direct integration into the Databricks Data Intelligence Platform, both Python and Spark workloads can now execute on native Delta Lake datasets, analysed with PyKX for superior performance and efficiency.
The net result is a reduction in hours spent with on-premises orchestration, efficiencies in parallelization through Spark and prominent open-source frameworks for ML Workflows.
In a recent transaction cost analysis demo, PyKX demonstrated 112x faster performance with 1000x less memory when compared to Pandas. This was working with Level 1 equities and trade quotes sourced from a leading data exchange and stored natively in Databricks on Delta Lake.
| Syntax | Avg Time | Avg Dev | runs | loops | Total Memory | Memory Increment |
| Pandas | 2.54 s | 24.7 ms | 7 | 1 | 3752.16 Mib | 1091.99 Mib |
| PyKX | 22.7 ms | 301 us | 7 | 10 | 2676.06 Mib | 1.16 Mib |
These results show a remarkable reduction in compute resource and lower operating costs for the enterprise. Analysts can import data from a variety of formats either natively or via the Databricks Data Marketplace, then use managed Spark clusters for lightning-fast ingestion.
Other Use Case Examples
- Large Scale Pre and Post Trade Analytics
- Algorithmic Trading Strategy Development and Backtesting
- Comprehensive Market Surveillance and Anomaly Detection
- Trade Lifecycle and Execution Analytics
- High Volume Order Book Analysis
- Multi-Asset Portfolio Construction and Analysis
- Counterparty Risk Analysis in High-Volume Trading Environments
In closing, the combined strengths of KX and Databricks offer significant benefits in data management, sophisticated queries, and analytics on extensive datasets. It fosters collaboration across departments by enabling access to a unified data ecosystem used by multiple teams. And by integrating ML algorithms into the vast datasets managed with Databricks Lakehouse, analysts can uncover more profound and timely insights, predict trends, and improve mission-critical decision making.
To find out more, read the blog: “KX and Databricks Integration: Advancing Time-series Data Analytics in Capital Markets and Beyond” or download our latest datasheet.