
ポイント
- Reference Architectures show the right way to design KDB-X systems.
- Blueprints give developers runnable KDB-X starting points, not just guidance.
- Both assets turn scattered expertise into deployable Developer Center resources.
- The first releases focus on AI, RAG, model distillation, ingestion, and sharding.
- The goal is faster movement from business problem to working KDB-X system.
We’re adding two new types of solution assets to the Developer Center: Reference Architectures and Blueprints. Both are built to shorten the distance between “I have a problem to solve” and “I have a working KDB-X system.”
Why we built these
Developers, customers, and partners ask: What’s the right way to build this on KDB-X?
You have a business problem (capturing a market data feed, running TCA across billions of rows, accelerating financial research with AI) and you have KDB-X. What you need is the connective tissue between them.
Until now, that knowledge lived in scattered places: tutorials, docs, internal decks, customer engagements, and tribal knowledge. We’re pulling it into one place and making it runnable.
Anchored in the capital markets workflow
Most of these assets are positioned within the capital markets analytic workflow (outlined in a blog by my colleague Scott Rich) that KX introduced for thinking about trading systems as a set of interconnected stages: research and backtesting, live signal generation, pre-trade analysis, execution, post-trade analysis, monitoring, and governance. The workflow gives us a common language for placing every Blueprint and Reference Architecture in context.
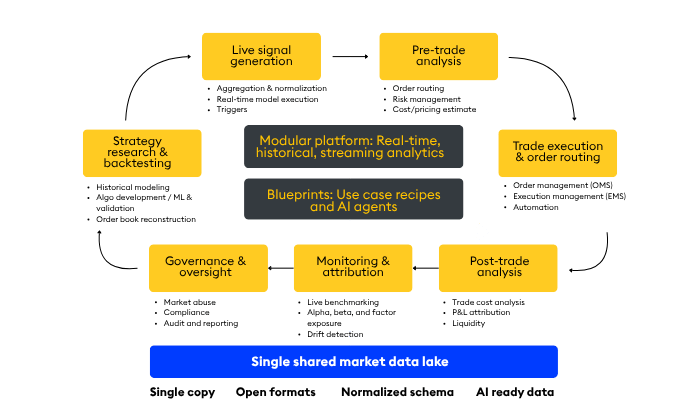
Each Blueprint is anchored in one or more of these workflow phases. Each Reference Architecture describes a pattern for instantiating part of the workflow on KDB-X. Together they make explicit what’s often implicit: how the pieces fit together, where tradeoffs live, and how a system grows from a single workflow into an integrated foundation.
What’s the difference?
Reference Architectures describe proven patterns for combining KDB-X components to meet specific functional and non-functional goals like latency, throughput, reliability, and cost. They’re design guidance, use them when you’re deciding how to build something.
Blueprints are runnable implementations of one or more Reference Architectures. Code, configuration, sample data, and operational guidance, packaged so you can deploy, extend, and adapt. Use them when you’re ready to build.
Think of it this way:
Reference Architectures help you make architectural decisions with confidence.
Blueprints get you to a working system fast.
What’s launching first
We’re launching with three Blueprints and two Reference Architectures:
Blueprints
- AI-Q Agentic Financial Research Blueprint: a GPU-accelerated agentic AI system that unifies KDB-X time-series data and KDB.AI vector search under a single NVIDIA AI-Q agent to deliver autonomous, citation-backed financial research reports in seconds. View here.
- Enterprise RAG Blueprint: an enterprise-ready RAG implementation combining NVIDIA NIM microservices and NeMo Retriever with KDB.AI for GPU-accelerated, multimodal document ingestion and question answering over proprietary data. View here.
- Financial Model Distillation Blueprint: distill large LLMs into lean, financial-domain models using NVIDIA NeMo Microservices and KDB-X, matching teacher-model accuracy at up to 98% lower inference cost. View here.
Reference Architectures
- Ingest, Transform & Persist: for ingesting data, applying transformations, and persisting the result. The right fit when preprocessing, shaping, or enriching data is part of the pipeline.
- Sharded Architecture: a highly scalable multi-node pattern for distributed workloads and horizontal scale. Use this when a single-node deployment isn’t enough and you need sharding for throughput or capacity.
Each Blueprint ships with schema, sample data, run scripts, and clear documentation describing what it does, what tradeoffs it makes, and how to integrate it with the rest of your stack.
How to use them
Blueprints are there for you to copy, modify, and run. They’re sample code, not supported products, but they’re built to be a real starting point rather than a toy.
If you’re evaluating KDB-X, start with a Blueprint that matches your use case and run it. If you’re already on KDB-X and hitting a scaling wall, browse the Reference Architectures. There’s likely a pattern (query-scaling, ingestion partitioning, replicas) that solves your problem without a re-platform.
What’s next
We’re already working on the next wave, both anchored in the market data ingestion stage of the workflow:
- Scaling Market Data Ingest Blueprint: high-throughput, fault-tolerant tick capture for production market data feeds.
- Tick Reference Architecture: the canonical KDB-X pattern for tick data systems, covering tickerplant ingestion, RDB, HDB, and gateway components.
Beyond that, the capital markets workflow has plenty of phases we haven’t covered yet, including pre-trade risk, post-trade analytics, smart order routing, surveillance, and research sandboxes. We’ll prioritize the next set of Blueprints based on what you tell us is most valuable.
Head to the Solutions section of the Developer Center to explore. If there’s a workflow you’d like to see become a Blueprint, let us know.


