

Key Takeaways
- Effective file compression is crucial for managing large-scale data efficiently.
- The choice of compression algorithm and parameters involves balancing storage savings, data ingestion speed, and query performance.
- Understanding data characteristics, query workloads, and hardware infrastructure (e.g., storage speed) is essential to choosing the most effective compression strategy.
- The right compression strategy combined with data tiering can optimize resource utilization, reduce costs, and maintain high performance.
At KX, we recognize the critical importance of speed and efficiency, particularly when managing substantial volumes of time-series data. Effective compression is crucial for reducing storage footprints and associated costs, and can also help enhance query performance by minimizing input/output bottlenecks. This blog examines the fundamentals of compression in kdb+ and shares key insights from a recent case study in the financial services industry. We will also evaluate the best practices when implementing your compression strategy.
kdb+ data storage and compression
Traditional databases store data in rows, which is often inefficient for advanced analytical workloads. This method requires scanning complete rows during querying, which creates unnecessary overhead and slows performance. kdb+, in contrast, employs a columnar storage model, which ignores unrelated fields. This results in faster queries, reduced memory bandwidth usage, and enhanced CPU cache performance.
kdb+ is also designed to ingest and query real-time data directly in RAM, bypassing disk latency altogether. This ensures sub-millisecond performance for high-speed analytics, making it ideal for time-sensitive use cases like trading systems, fraud detection, and IoT monitoring. kdb+ immediately makes real-time data available for analysis without complex transformation or loading. This enables users to query live data with minimal delay, reducing time to actionable insight.
As data ages out of memory, kdb+ seamlessly transitions it to disk-based tiers without interrupting performance or access. This tiered structure strikes a balance between the need for low latency and long-term scalability, while maintaining high query performance.
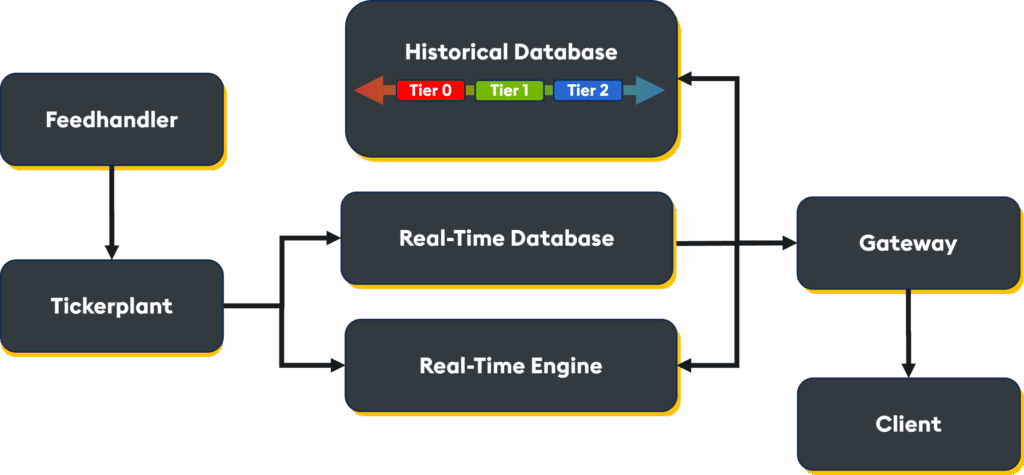
- The real-time database (RDB) is an in-memory data store for ultra-fast querying with sub-millisecond latency. This layer is ideal for the most recent and high-frequency data
- The intraday database (IDB) is used when memory thresholds are reached and comprises a set of disk-based tables optimized for fast querying. The IDB is typically partitioned by small time windows (e.g., 5–60 minutes) to reduce memory pressure and ensure efficient query performance
- The historical database (HDB) is an on-disk, end-of-day, long-term storage solution. It can span petabytes of data and is often used for backtesting, compliance, and batch analytics. Data in HDB can be tiered based on the access frequency
Because kdb+ stores data in a columnar fashion, it is highly conducive to compression. When tables are “splayed” on disk, each column is saved as a separate file, allowing for better compression ratios and single-column homogeneity (lower entropy). Before implementing a compression strategy, however, there are three key aspects to consider:
- Compression ratio: Indicates how much the data can be reduced. A high compression ratio means smaller files and lower storage costs. Smaller files can also reduce query execution time, especially if the storage is slow.
- Compression speed: Measures the time required to compress a file. High compression speed minimizes CPU usage and associated costs, allowing for faster data ingestion.
- Decompression speed: Reflects the time taken to retrieve data from the compressed version. High decompression speed ensures faster queries.
kdb+ supports five compression algorithms, some of which have tunable parameters to balance compression ratio and speed. The choice of algorithm depends on your priorities, whether you want to achieve the fastest possible query execution or minimize storage costs.
- qIPC: The default compression used by q for fast, lightweight data transfer over IPC. Optimized for speed rather than compression, it is ideal for temporary data transfers over q sessions. qIPC has no external library dependency.
- gzip: Widely supported, it achieves a high compression ratio but is relatively slow. It should be used when storage savings are more important than speed (archival purposes) or for interoperability with other systems (since gzip is common).
- snappy: Designed for high-speed compression/decompression. It should be used when speed is critical and moderate compression is acceptable, such as in real-time analytics and low-latency environments.
- lz4hc: A high-compression variant of LZ4 (LZ4HC = “LZ4 High Compression”). It is slower to compress but very fast to decompress. It is ideal for read-heavy systems where compression can be done once (e.g., batch load), but read performance matters.
- zstd: Offers a good balance across speed, ratio, and flexibility when balancing space and performance. It is perfect for columnar data, such as splayed or parquet tables.
|
Algorithm |
Compression Ratio | Compression Speed | Decompression Speed | Best For |
|
qIPC |
Low | Very Fast | Very Fast | IPC Messaging |
|
gzip |
High | Slow | Moderate | Archival, Interoperability |
|
snappy |
Low/Medium | Very Fast | Very Fast | Real-time analytics |
|
lz4hc |
Medium/High | Moderate/Slow | Very Fast | Read-heavy batch data |
|
zstd |
High | Fast | Fast | Balanced general use |
Kdb+ supports setting different compression for each column file, providing great flexibility in cost and performance optimization.
Financial case study
In a recent case study conducted in collaboration with Intel, we obtained real-world performance comparisons of these algorithms using a publicly available TAQ (Trade and Quote) dataset from the New York Stock Exchange (NYSE). The study utilized two systems with different storage characteristics: The first with fast local SSDs and the second using slower Network File System (NFS) storage.
The reason for using this dataset was to replicate the vast amount of data generated daily by the financial sector and how this necessitates effective data management strategies. Compression algorithms play a pivotal role in reducing data size, lowering storage costs, and enhancing data processing speeds. However, the effectiveness of these algorithms can vary significantly based on the type of data and the hardware used.
The study’s findings highlight the trade-offs between compression efficiency and speed, enabling organizations to select the most suitable algorithm for their specific needs. Additionally, the study’s recommendations on tiered storage strategies emphasize the importance of aligning compression practices with data access patterns, thereby ensuring optimal performance and cost efficiency.
Key findings and observations:
- Compression ratios: zstd and gzip generally provide the best compression ratios, with zstd offering a slight edge. Columns with lower entropy compress much better than those with high entropy.
- Write speed and compression times: Compression typically slows down write operations. However, snappy and zstd level 1 can improve write speed for certain column types.
- Query response times: Compression can slow queries, especially for CPU-bound workloads, and should be avoided for frequently accessed (“hot”) data. However, compression improves performance when large datasets are read from slower storage, making it beneficial for cooler tiers.
Recommendations
For an optimal balance of cost and query performance, we recommend a tiered storage strategy:
- Hot tier: Compression should not be used when the maximum ingestion rate and the fastest queries are required. This tier should also be on fast storage, typically storing up to a month’s worth of data.
- Second tier: Use compression for less frequently queried data. Choose snappy or lz4 for improved query speed, or zstd for high compression ratios.
- Cold tier: Utilize compression for infrequently accessed data, typically stored on less expensive and slower storage. Consider recompressing data with zstd to save storage space.
File compression is an indispensable tool for efficiently managing large-scale data; however, selecting the appropriate compression algorithm and its parameters involves striking a balance between storage savings, data ingestion speed, and query performance.
The FSI case study provides invaluable insights into how modern algorithms like zstd and lz4 perform against established ones like gzip. Understanding your data characteristics, query workloads, and hardware infrastructure will ultimately guide you to the most effective compression strategy for your kdb+ deployment.
Read the full report on code.kx


