

Our whitepaper, Cultivate Sustainable Computing and Environmentally Responsible Analytics in an AI Age, had me thinking, how many of us strive for sustainability, only to fall short? I recycle, shop locally, live in a small house, and advocate for environmental causes. Yet my family drives two petrol-guzzling cars, we regularly fly short-haul, and our drafty one-time Tudor merchant house is anything but energy-efficient.
My passive environmentalism helped draw me to KX. Yes, I love the analytics, Python, and AI, but it was my previous experience in enterprise middleware, which helped me realize computing should be much greener.
Everywhere I looked in middleware, I saw computational waste. I don’t mean technical debt. I mean inefficient compute, inefficient memory utilization, and over-complicated stacks, probably held together by spiderwebs of APIs and Kubernetes processes. This comes from the programming languages used in the core tooling, and cultures that reward performance over efficiency. Let’s explore.
The Language Bloat Problem
When in middleware, I worked in the Java ecosystem. It could have been Python, C++, JavaScript. But I worked with Java, and it so happens that many big data tools are built in the so-called Java Virtual Machine, such as Kafka, Cassandra, Spark, Solr, ElasticSearch, Solr, Hadoop, ZooKeeper, and Flink. Python and JavaScript, also relevant to data analytics, use similar virtual machines or runtime environments.
Runtimes are great for development. They encapsulate general-purpose functionality and facilitate “write once, run anywhere” development. Trouble is, runtimes tend to “price” for all use cases and the hardest workloads – memory utilization, compute. It’s a bit like driving ten cars rather than one to the grocery store, with all ten prepped to drive thousands of miles.
In Java’s case, glitches and inconsistent performance mean users must assign memory and compute accordingly. This affects its performance and efficiency. Python, with its own runtimes, has struggled with the so-called Global Interpreter Lock (GIL for short), which has impacted its ability to optimally thread processes and thus run efficient compute.
Such factors have been compared in the often-cited Energy Efficiency Across Programming Languages Survey where Java seemingly performs better than Python. The survey is somewhat academic and should not be read too literally, but it highlights the green credentials of programming languages that underpin enterprise and data stacks.
The Massive Data Stack Problem
Who hasn’t seen a highly elaborate architecture presented at a conference or in an engineering blog? Has the presenter or author sought to “wow” you with their stupendous ability to navigate multiple tools? Sometimes, those “complexity wows” get institutionalized, like with the legendary Hadoop stack with its plethora of confusingly named components, like Hive, Yarn, Pig, HBASE, etc. When a complex stack meets key SLA targets, normally latency, throughput, and carrying capacity, the green efficiency of the bloated stack hasn’t always been scrutinized. “Job done” matters more than “how well it was done.”
In AI, Matt Turck’s oft-cited AI landscape illustrates something similar and is exacerbated further by compute-intensive LLMs and GenAI workflow injections. So troublesome is the GenAI stack compute load on the environment that the topic is discussed frequently in the Telegraph, New York Times, and Economist. For example, ‘did you know a 50-question interaction with an AI chatbot can consume around 500mls of water?’
In sum, the modern stack has been complacent about languages and the proliferating nature of applications, which GenAI compute exacerbates. Unchecked by proper measurement, data centers – which power the everyday needs of you and me – can consume the electricity consumption and carbon footprints of large nations!
Squish the Stack
KX is built differently to service the heaviest analytics workloads, from the biggest data sets and the fastest streams to the most intensive AI application. Not a single byte of code or memory is wasted. With KX you can:
- Run vector processing in the simplest, tersest way possible. No bloat.
- Combine data management and analytics.
- Perform single vector operations to reduce compute; no multiple loops or batched relational queries.
- Deploy the smallest footprint – a few hundred bytes.
For Environmental Social Governance (ESG) analysis, KX ingests, aggregates, and analyzes disparate and inconsistent data. For industrial applications, it ingests data from sensors, databases, and shopfloor metrics, providing observability, which, in turn, provides insights to reduce waste.
Lower Environmental Overheads? Lower Bills Too?
Environmental efficiencies should equate to cost efficiencies and performance improvements.
For cloud scale – measured economically by FinOps – cost optimizations come to the forefront. FinOps, CloudOps and AIOps practitioners should complement common Performance SLAs with Cost per Query and Queries per Watt indicators, like in the following chart.
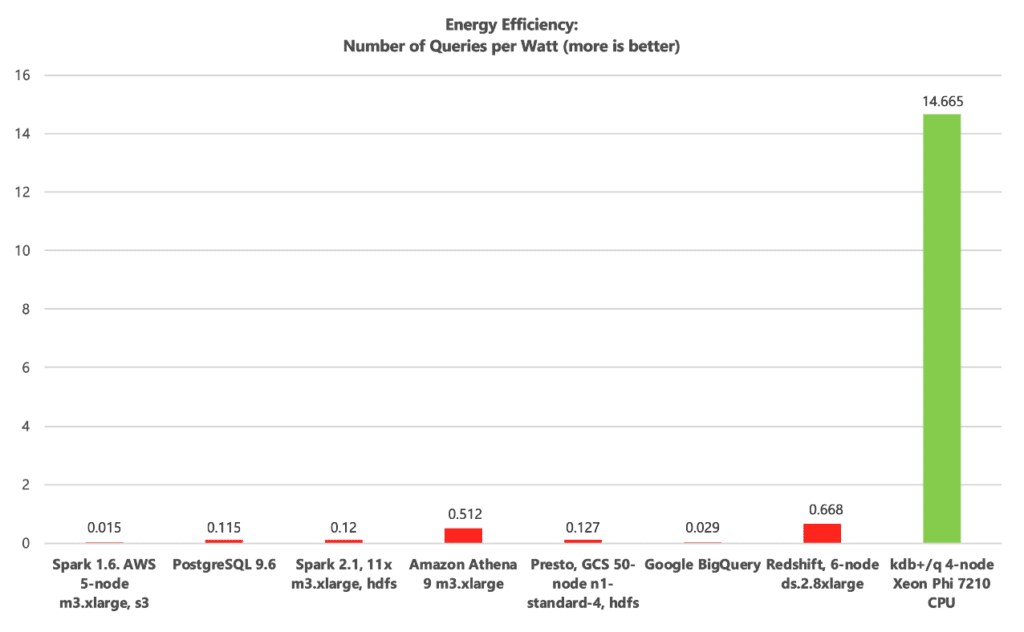
In an ideal world, Queries per Watt (sustainable computing), Cost per Query (FinOps) and SLA efficacy (throughput over a given time) should correlate. When they do, performance, cost and sustainability harmony ensue. When high performance comes at the cost of low numbers of Queries per Watt and/or high Cost per Query measures, bloat ensues, exacerbated at cloud and GenAI scale.
(Above) The Virtuous Trinity of Cloud Scale Analytics: Optimal Scaling in the Presence of Lowest Costs
Download our whitepaper, ‘Cultivating Sustainable Computing and Environmentally Responsible Analytics in an AI Age’ if you’re interested in ESG issues and want practical solutions to your business needs.
I also recommend following and engaging with the Green Software Foundation.