Key Takeaways
- The KX-NVIDIA AI-Q blueprint eliminates the “context-switching tax” by unifying structured time-series data and unstructured research content under a single intelligent agent.
- Unlike traditional RAG systems, AI-Q agents actively plan, execute parallel queries, and self-correct—enabling true cross-modal financial reasoning rather than passive retrieval.
- GPU acceleration across ingestion, vector search (cuVS/CAGRA), and reranking dramatically reduces latency, allowing real-time retrieval across millions of documents.
- By exposing KDB-X via Model Context Protocol (MCP), the agent can safely execute complex q/SQL analytics, grounding LLM outputs in deterministic market data.
- The result is enterprise-ready, agentic financial research that compresses hours of manual analysis into minutes, enabling faster, citation-backed, decision-grade insight at scale.
In financial research, the “context-switching tax” is a structural divide that kills productivity. Quants and analysts currently navigate two irreconcilable data worlds: the rigid, high-velocity realm of time-series (prices and risk metrics) and the vast, unstructured wilderness of documents (transcripts and filings).
Historically, these worlds have remained technically divorced. Bridging them requires a grueling manual relay—toggling between database queries for anomalies and PDF viewers for catalysts. This friction creates massive latency and risks missing the critical link between the “what” and the “why.”
The KX-NVIDIA AI-Q Agentic Blueprint eliminates this friction. It is a GPU-accelerated architecture that unifies these data types through a single intelligent agent. This isn’t just a “faster search.” It is an agentic system that plans research, executes complex queries in parallel, and synthesizes comprehensive, citation-backed reports in seconds.
By combining NVIDIA’s NeMo Retriever and NIM microservices with KX’s KDB-X and KDB.AI, we’ve created an enterprise-ready architecture that moves beyond simple lookups into the era of autonomous financial intelligence.
From RAG to agentic financial research: NVIDIA AI-Q + KX
Standard Retrieval-Augmented Generation (RAG) changed the baseline by grounding LLMs in private data. However, in capital markets, simple RAG hits a “reasoning ceiling.” It is passive: it retrieves text but cannot decide to cross-reference a price spike with a specific earnings transcript unless explicitly told to do so.
The NVIDIA AI-Q Research Assistant Blueprint shifts the paradigm from passive retrieval to active reasoning, establishing a framework that NVIDIA calls “Artificial General Agents.”
Unlike a linear pipeline, an AI-Q agent operates in a continuous, goal-oriented loop:
- Dynamic planning: The agent receives a high-level research objective and uses a reasoning model to decompose it into a DAG (Directed Acyclic Graph) of sub-tasks.
- Parallel execution: Instead of sequential lookups, the agent fires off multiple queries in parallel across different domains—searching internal documents, querying databases, and hitting web APIs simultaneously.
- Self-correction & reflection: An “LLM-as-a-judge” step evaluates data quality. If a gap is found—like a missing volatility metric—the agent automatically re-plans to find it.
Adapting AI-Q for the KX ecosystem
AI-Q provides the “brain”, but a researcher is only as good as its “senses”. The KX adaptation optimizes this for finance via two layers:
The unstructured layer (KDB.AI cuVS): Sub-second semantic search over millions of documents, powered by NVIDIA cuVS.
The structured layer (KDB-X): This is the critical missing piece in standard AI blueprints. By exposing KDB-X via the Model Context Protocol (MCP), the agent gains the ability to execute complex q/SQL queries.
In this architecture, RAG is not the system—it is a tool. The agent sits above the data, reasoning about which tool is best suited for the question at hand.
Architecture overview: How the pieces fit together
The KX-NVIDIA AIQ Blueprint architecture is organized into three distinct tiers: the “Brain” (orchestration), the “Senses” (tooling), and the “Memory” (data).
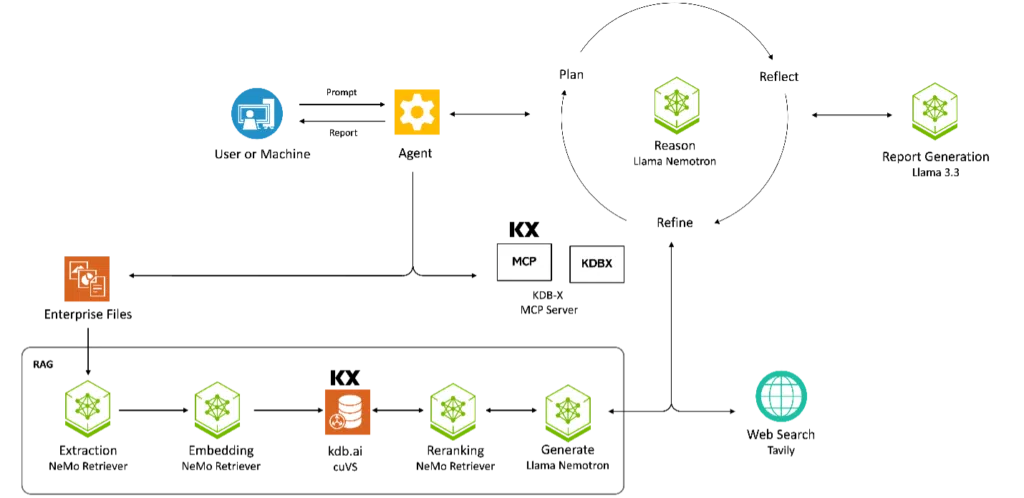
Top layer: AI-Q Research Agent (NeMo agent toolkit)
At the summit of the stack sits the NVIDIA AI-Q Research Agent, orchestrated by the NeMo Agent Toolkit. This isn’t a static script; it’s a dynamic state machine that manages the lifecycle of a research request.
- Dynamic planning: The agent decomposes a complex prompt into sub-questions.
- Parallel execution: The toolkit allows the agent to fire off tool calls in parallel, querying the RAG engine for sentiment while simultaneously asking KDB-X for volatility metrics.
- Iterative refinement: The agent reflects on the gathered context. If it finds conflicting data or gaps, it initiates a “Refine” loop, re-querying tools until the report meets the user’s requirements.
Tooling layer: KX + NVIDIA data services
The agent doesn’t talk to raw databases; it talks to specialized “Services” that abstract away the complexity of financial data.
- KX-NVIDIA RAG Blueprint: A fork of the NVIDIA Enterprise RAG Blueprint uses NeMo Retriever for multimodal extraction (tables/charts) and KDB.AI cuVS for GPU-accelerated vector search. for GPU-accelerated vector search.
- KDB-X MCP Server: This bridge gives the agent a standardized way to call “tools” like get_price_history. The agent generates a tool call, and the MCP server translates it into high-performance q/SQL.
Data layer: The memory
Underpinning everything are the two core KX data engines, both optimized for NVIDIA infrastructure:
- KDB-X: The industry standard for high-volume, time-series data. It stores the “ground truth” of market prices, curves, and risk metrics.
- KDB.AI: A purpose-built vector database for finance that natively integrates cuVS algorithms like CAGRA. It handles the “unstructured” side of the house—filings, transcripts, and macro reports.
Inside the GPU-Accelerated RAG Blueprint (KDB.AI + NVIDIA cuVS)
To build a truly agentic assistant, the entire data lifecycle must be accelerated. In standard RAG, the bottleneck isn’t the model’s intelligence; it’s the time it takes to find the right needle in a multi-million-page haystack. Let’s dive into the KX-NVIDIA RAG Blueprint to understand how our AI-Q agent accesses highly relevant unstructured data:
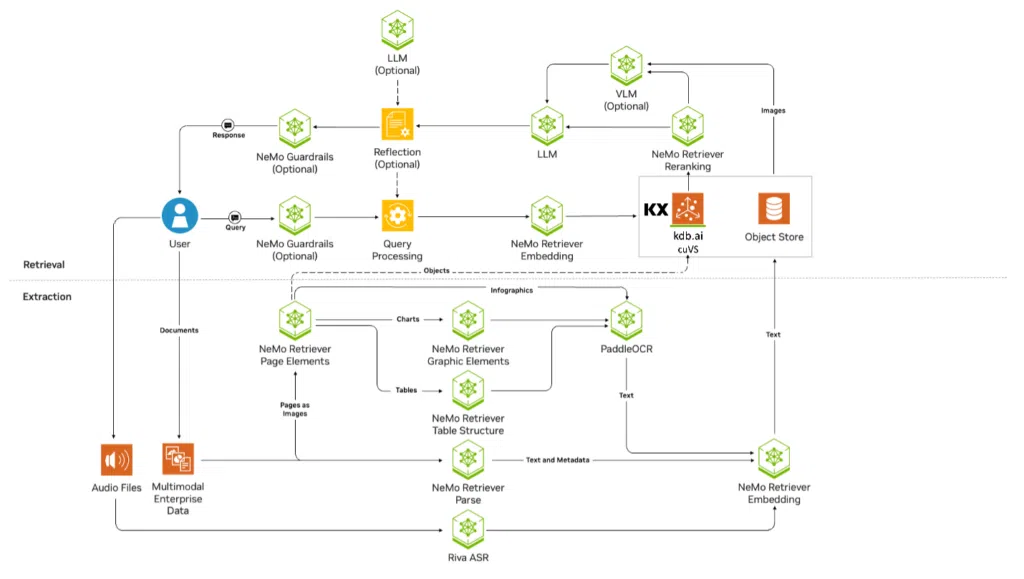
Multimodal ingestion and extraction
Financial intelligence is rarely just plain text. It lives in complex PDF tables, data-heavy charts, and audio streams. The blueprint uses NVIDIA NeMo Retriever Extraction to partition documents and identify visual elements like infographics and tables in parallel.
- Multimodal PDF extraction: NeMo Retriever Extraction microservices deliver a 15x throughput increase in multimodal data extraction compared to open-source alternatives.
- Audio transcription: NVIDIA Rivaprovides GPU-accelerated speech-to-text for audio like earnings calls, running in 150ms on an A100 GPU—far below the 300ms threshold for real-time applications.
GPU-Accelerated Retrieval (KDB.AI + cuVS)
Once the data is ingested and embedded via NeMo Retriever Embedding NIMs, it resides in KDB.AI cuVS. This is where the physics of the GPU changes the game for search.
The system uses CAGRA (CUDA Approximate Nearest-neighbor Graph-based), a graph-based search algorithm built specifically for CUDA. Unlike CPU algorithms that branch sequentially, CAGRA explores hundreds of candidate paths across thousands of GPU cores simultaneously.
Precision reranking: The quality gate
Vector search is great at finding “similar” content, but “similar” isn’t always “relevant” in a financial context. To solve this, the blueprint incorporates a NeMo Retriever Text Reranking NIM.
To solve the “relevance” problem, the blueprint uses a NeMo Retriever Text Reranking NIM. This cross-encoder “quality gate” re-scores results token-by-token on the GPU, providing 1.6x better reranking throughput compared to open-source FP16 alternatives and ensuring only the most precise context reaches the LLM.
By moving ingestion, search, and reranking to the GPU, we reduce the “latency tax” of the entire pipeline. This gives the agent more time to “think” and reason without making the user wait.
KDB-X via MCP: Structured time-series at LLM speed
RAG provides the context (the “why”), but KDB-X provides the evidence (the “what”). For an agent to be truly effective, it needs a way to safely and efficiently interrogate live market data, risk metrics, and historical time-series without a human middleman.
Why KDB-X in the loop?
Large Language Models (LLMs) are notorious for “hallucinating” numbers or failing at complex arithmetic. By plugging KDB-X directly into the agent’s reasoning loop, we offload the heavy lifting—aggregations, as-of joins, and multi-year volatility calculations—to the world’s most powerful time-series engine.
MCP: Letting the agent call q/SQL safely
The bridge between the AI-Q agent and the database is the KDB-X MCP Server. Model Context Protocol (MCP) is an open standard that allows the agent to “discover” what KDB-X can do. When the agent starts, the KDB-X MCP server sends a manifest of available tools, complete with descriptions and parameter schemas.
The agent doesn’t need to know the complexities of q or even specific table schemas from the start. It uses MCP tools like kdbx_describe_tables to understand the data landscape and then uses kdbx_run_sql_query to fetch the exact data it needs.
Read this article to learn more about the KDB-X MCP Server.
Example: Combining KDB-X with RAG
The real power of this architecture is cross-modal reasoning. Consider a request like: “Explain why the volatility of our tech portfolio spiked last Tuesday.”
- Step 1 (Structured): The agent calls a KDB-X tool to identify the specific tickers with the highest variance and retrieves the intraday price curves for that Tuesday.
- Step 2 (Unstructured): Using those tickers and the specific timestamps, the agent queries the KDB.AI RAG tool for news, earnings calls, or analyst notes released within that same window.
- Step 3 (Synthesis): The agent concludes: “Volatility spiked 14% at 10:15 AM following a specific regulatory announcement retrieved from KDB.AI, which impacted the 5 tickers identified in the KDB-X analysis.”
The AI-Q session: From prompt to publication
This is where the architecture translates into a category shift in productivity. To see the full stack in action, let’s follow a senior analyst tasked with a deep-dive: “Write a report on risk drivers in European high-yield credit over the last quarter.”
- Planning: The agent proposes an outline (Macro, Quantitative Risk, Sector Breakdown). The analyst edits this plan to focus on specific interests.
- Parallel Search: The engine fires queries to KDB.AI for research notes and KDB-X for spread calculations simultaneously.
- Reflection: The agent notices a “data gap” in recent Real Estate news and triggers an adaptive fallback to web search.
- Synthesis: The analyst receives a cited, 5-page draft in minutes. A morning of hunting is now minutes of reviewing. Now they can dive deeper into the report, asking further questions.
Developer quickstart: Running the AI-Q Blueprint
The blueprint is modular and deployable via Docker Compose. This guide will get the full stack—including the Agent, the KDB.AI-backed RAG service, and the KDB-X MCP server—running in minutes. These blueprints are developed by Abdalhamid Alattar, Generative AI Solutions Architect at KX.
Setup
Full Docker self-hosted setup instructions:
Prerequisites
Before you begin, ensure your environment meets the following requirements:
- Hardware: An NVIDIA GPU (L4, A100, H100, or RTX 6000+) with at least 24GB VRAM.
- Drivers: NVIDIA Driver 550.x or later and the NVIDIA Container Toolkit.
- Software: Docker and Docker Compose (v2.29+).
- API Keys:
- An NGC API Key for accessing NVIDIA NIM microservices
- KX Licenses for KDB-X/KDB.AI.
- KX bearer token to pull the images
- First, run the RAG blueprint, then use the AI-Q blueprint to deploy the RAG system on top of AI-Q. AI-Q reuses the NIMs and LLM from the RAG blueprint.
These instructions launch:
- AI-Q Researcher Agent: The orchestration “brain” using the NeMo Agent Toolkit.
- KDB.AI RAG Service: The cuVS-accelerated vector retrieval tool.
- KDB-X MCP Server: The Model Context Protocol bridge for structured queries.
- Ingestion Pipeline: NVIDIA nv-ingest for parsing PDFs and embeddings.
Using the agent
Access the UI at http://localhost:8090.
- Ingest: Drop PDFs into the “Upload” tab for GPU-accelerated parsing.
- Research: Prompt the agent for portfolio comparisons or macro risks.
- Trace: Use the “Agent Logs” to watch the parallel calls to KDB-X and KDB.AI.
Extending the blueprint: Next steps
This blueprint is a foundation. Because it uses open standards like MCP and NIM, you can adapt it to your firm’s proprietary needs:
- Custom KDB-X tools: Add new q/SQL functions to the MCP server to expose internal risk models or liquidity metrics.
- Alternative data: Create additional KDB.AI collections for alternative data sources like satellite imagery metadata or ESG sentiment feeds.
- Human-in-the-loop tuning: Modify the “LLM-as-a-judge” prompts in the orchestration layer to enforce specific compliance or stylistic guidelines for your firm’s reports.
Ready to start? Head over to the GitHub Repository to explore the source code, and join the KX community to ask questions and share your feedback.
Download the free KDB-X Community Edition to get started with the next generation of kdb+ today.