In the era of generative AI and machine learning, the demand for faster, smarter, and more efficient data processing is growing rapidly. Traditional databases are often not equipped to handle the complexity and scale of data required by modern AI systems. Enter vector databases — purpose-built to manage and query high-dimensional vectors, driving breakthroughs in AI-powered search, recommendations, and real-time analytics.
What is vectorized data?
Vectorized data is stored in a structured series of numbers known in mathematical terms as a vector. These are sometimes called vector embeddings.
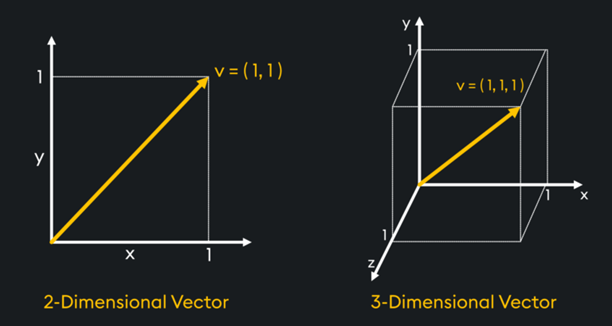
Above, we see two examples of a vector. This is a line that has both magnitude and direction. It’s shown above in 2-dimensions and 3-dimensions, but in a vector database, vectors can have thousands of dimensions (which we can’t visualize).
Each vector encodes information about the data it represents. The similarity between vectors in a vector space gives us an indication that the representative data is also similar. The beauty of this is that unstructured data (documents, text, images, video, and audio) can be encoded in vector space, and similarities between them can be retrieved in ways that were never possible before.
Much of this is possible through transformer architecture in machine learning, which uses algorithms to contextualize the information in unstructured data. The process is called embedding, and there are many flavors of it for different types of data source formats:
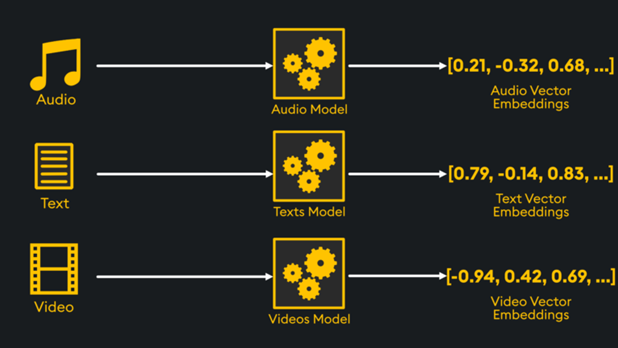
Above, we see how different embeddings can be created through different embedding models for audio, text, and video.
What is a vector database?
A vector database is a specialized database designed to store, search, and retrieve data points in vector form. Unlike traditional databases that rely on rows and columns of structured data, vector databases operate in a high-dimensional vector space, enabling faster and more accurate similarity searches.
Let us imagine we have a set of vectors in 2 dimensions (shown yellow below). A query vector is then generated using the same embedding process, ensuring it occupies the same vector space. (shown in green below).
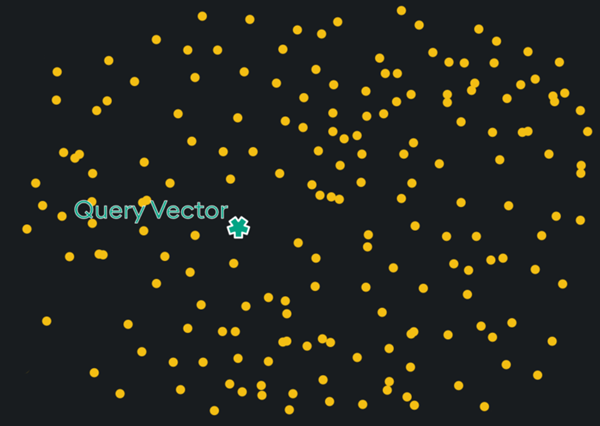
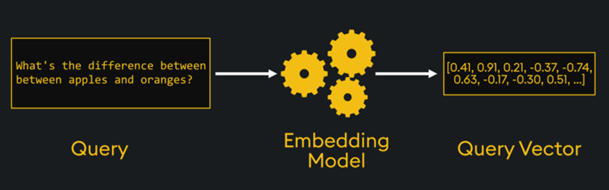
Since the query vector uses the same embedding model as the stored vector, its similarity to stored data can be computed and retrieved.
This storage is technically possible in a simple mathematical array without a database. Some vector libraries do just this. However, the data can only be vectors (no metadata), the data is immutable (cannot be changed), and you can’t query while importing data. This is where vector databases come in. Not only do they solve the aforementioned issues, but they also have other traditional database features like CRUD, persistence, backups, durability, hybrid search, and more.
Key features of a vector database
- High-dimensional search: Perform fast and scalable similarity searches across millions or billions of data points
- Low latency: Designed for real-time processing, ensuring quick responses even with large datasets
- Scalability: Optimized to handle the storage and retrieval of large datasets, growing with demand
- Integration with AI & ML models: Easily connect with machine learning frameworks to store and query embeddings generated by AI models
Applications of vector databases
Retrieval Augmented Generation (RAG): Vector databases play a crucial role in powering Retrieval Augmented Generation (RAG), a common use case where Large Language Models (LLMs) are combined with vector retrieval. By extracting relevant contextual information from a query and feeding it into an LLM, businesses can generate precise, well-articulated responses rather than returning raw data.
- Image and video search: Vector databases excel in content-based image retrieval (CBIR), where images are stored as vectors representing features like color, texture, and shape. When users search by image, the database compares vectors to find visually similar content, enhancing search accuracy for image and video queries.
- Natural language search: In natural language processing (NLP) applications, text is transformed into vectors using methods like word embeddings or transformers. Vector databases enable semantic search, retrieving contextually similar text rather than relying on exact keyword matches, improving user experience with more intuitive and accurate results.
- Recommendation systems: Vector databases are essential in building recommendation systems used by retailers, streaming platforms, and social media. By analyzing user behavior and preferences stored as vectors, these systems can suggest products, movies, or posts that align with individual user interests.
- Real-time personalization: Businesses can deliver personalized experiences in real time by storing user profiles as vectors and comparing them to others in the database. This allows for dynamic content and offers suggestions tailored to individual users, significantly improving engagement and conversion rates.
- Pattern matching and trend analytics: Vector databases are highly effective in time-series analysis, enabling quick comparison of time-dependent data through Temporal Similarity Search. This capability is vital for applications in sensor analytics, trade analytics, drilling operations, and more, where detecting patterns and trends is key to decision-making.
Vector database vs. traditional databases
| Features | Vector database | Traditional database |
| Data structure | High-dimensional vectors from unstructured data | Exact match or range-based search |
| Search type | Similarity search in vector space | Exact match or range-based search |
| Performance | Optimized for AI and machine learning | Optimized for transactional operations |
| Best use cases | AI, machine learning, NLP, image search | Transactional, relational data storage |
| Scalability | High scalability for large datasets | Limited scalability for high-dimensional data |
How to choose a vector database
Choosing the right vector database depends on your use case, data requirements, and scale. Here are some considerations:
- Performance and scalability: Vector databases, such as KDB.AI, are designed to handle large volumes of data efficiently, offering high-performance search capabilities that can scale with your data needs. KDB.AI, for example, integrates RAG and mixed search, enabling nuanced querying that considers context and relationships for more accurate and insightful analysis.
- Integration: Vector databases should have a user-friendly interface and integrate seamlessly with existing systems. They should support various programming languages and frameworks, making it easy for developers to implement.
- Pricing: Look for flexible pricing models that grow with your needs. KDB.AI, for example, includes a free tier and licensed options for larger applications. This ensures that the pricing aligns with your budget and usage patterns.
- Support: Look for a solution that has a strong community and reliable support. This is a fast-moving space, so you want a solution that provides regular updates, an active user community, and responsive support to help you troubleshoot issues and stay updated with the latest features and best practices.
Integrated vs Native vs Library
Vector search comes in a variety of forms. At its simplest, a vector library can be used for free, but it has many limitations because it is not a true database. Additionally, some traditional database vendors have offered vector search in their databases, but these come with performance and scalability limitations. The best solution is a native vector database that can integrate with your other structured data search systems.
| Feature | Native vector databases | Integrated vector databases | Vector libraries |
| Purpose | Purpose-built for vector search and management | Traditional DBs with added vector support | Libraries for custom vector operations |
| Performance for vectors | High (optimized for vector operations) | Low (depends on implementation) | High (for smaller datasets in memory) |
| Scalability | High scalability, optimized for large datasets | Scalable but not as efficient as native | Limited by in-memory capacity |
| Cost | Higher (new infrastructure) | Moderate (extends existing infrastructure) | Low (minimal infrastructure) |
| Ease of use | Easy for vector-centric applications | Familiar for traditional DB users | Requires more development effort |
| Database features | Includes DB features (CRUD, persistence, partitioning) | Full DB features (ACID, hybrid queries) | Lacks database features |
Benefits of KDB.AI
KDB.AI provides a high-performance vector database to help organizations build scalable, enterprise-grade AI applications and advanced RAG solutions for real-time intelligent search and contextual reasoning.
It includes several features to optimize your vector search:
- Multi-modal RAG: Multi-modal RAG combines the capabilities of Large Language Models (LLMs) with an ability to retrieve and utilize information from various data sources, including audio, video, and text. It enables developers to build highly accurate, contextually relevant responses across datasets for a holistic response to queries.
- Hybrid search: Hybrid search is an advanced search feature that combines the keyword accuracy of sparse search with the contextual comprehension and semantic significance of dense search. It enables developers to build AI systems that provide comprehensive results from contrasting data sources.
- Temporal Similarity Search: provides a comprehensive suite of tools for analyzing patterns, trends, and anomalies within time series datasets. Comprising two key components, Transformed TSS for highly efficient vector searches across massive time series datasets and Non-Transformed TSS for near real-time similarity search of fast-moving data.
- Fuzzy filtering: Fuzzy filtering enhances the accuracy and relevance of search results by allowing for approximate matches rather than exact ones. It’s helpful in scenarios where data may have inconsistencies or with queries that contain typographical errors or variation.
- On-disk indexing: Traditional vector indexes are stored in memory to provide the fastest response times. However, they can become constrained as indexes grow and memory resources deplete. To address this, KDB.AI boasts two on-disk indexing solutions, qFlat and qHNSW.
- Flat indexing is often used for real-time data ingestion, creating vectors with minimal computation for smaller-scale databases. It guarantees 100% recall and precision but is considered less efficient than other index types due to its “brute force” retrieval approach. By offloading to disk, qFlat can support larger indexes with higher dimensionality, ensuring that data persists even after the system restarts.
- qHNSW provides an HNSW index variant for approximate nearest neighbor (ANN) search. It is suitable for large-scale databases requiring improved search speeds and moderate accuracy. Operating over multiple sparse layers, it creates an efficient search solution in which each vector connects to its neighbors based on proximity. qHNSW is Ideal for applications such as recommendation systems, natural language processing, and image retrieval.
 qHNSW shares the same underlying data structure as qFlat; because of that, developers can switch between high-performance approximations and exhaustive searches depending on workload.
qHNSW shares the same underlying data structure as qFlat; because of that, developers can switch between high-performance approximations and exhaustive searches depending on workload.
Frequently Asked Questions
What is a vector in a vector database?
A vector is a numerical representation of data in a high-dimensional space, often used to represent complex objects like images, text, or audio.
What are vector embeddings?
Embeddings are dense vector representations of objects (e.g., words, images) generated by machine learning models to capture their key features and relationships.
How does a vector database handle large datasets?
Vector databases are optimized for scalability, using approximate nearest neighbor (ANN) algorithms and distributed architectures to manage large volumes of high-dimensional data efficiently.
Can I use a vector database with my existing AI models?
Yes, vector databases are designed to integrate with machine learning frameworks and can store embeddings generated by popular AI models.
What are the key features of a vector database?
Key features include high-dimensional search, low latency, scalability, and integration with AI and ML models.
What applications use a vector database?
Applications include retrieval augmented generation (RAG), image and video search, natural language search, recommendation systems, real-time personalization, pattern matching, and trend analytics.
How do vector databases compare to traditional databases?
Vector databases are optimized for AI and machine learning, handling high-dimensional vectors from unstructured data. Traditional databases, in contrast, are optimized for transactional operations and structured data.
What is hybrid search in vector databases?
Hybrid search combines the keyword accuracy of sparse search with the contextual comprehension and semantic significance of dense search. This delivers more relevant results in use cases such as e-commerce, content recommendation, and enterprise search.