
kdb+ has long been renowned for its high-performance time-series database capabilities and excels at storing and analyzing vast amounts of structured data with rapid query performance.
Today, we are excited to share that kdb+ databases can now be integrated into KDB.AI, delivering two advanced capabilities to your kdb+ deployments: advanced pattern matching for structured time-series data and semantic similarity search.
Similarly, this integration enables developers to mount massive kdb+ datasets into their AI workflows, which, in some cases, can contain trillions of rows.
db.create_table(
table="trade",
external_data_references=[{"path":b'/db', "provider" :"kx"}],
partition_column="date")Using this connection, users can leverage KDB.AI’s powerful Non-Transformed Temporal Similarity Search (TSS) and semantic vector search directly upon data in kdb+. This means there is no need for costly and impractical data migration between systems.
By connecting these systems, organizations can unlock deeper insights, identify subtle patterns, and make more informed decisions based on a holistic view of their data estate.
The primary driver behind this integration is the enhancement of decision-making capabilities. By bridging the gap between traditional time-series data and advanced pattern recognition, organizations can now generate real-time insights that were previously challenging to obtain. This integration enables insights from both structured and unstructured data, leading to more nuanced and accurate predictions, risk assessments, and operational strategies.
Benefits of temporal similarity search on kdb+
The connection between KDB.AI and kdb+ is designed to drive rapid adoption and deliver immediate value in any field dealing with large volumes of time-series or unstructured data.
The integration aims to achieve several objectives:
- Facilitate Temporal Similarity Search (TSS) on both splayed and partitioned kdb+ tables, enhancing the ability to identify temporal patterns in massive datasets.
- Enable similarity searches on embeddings stored in kdb+ splayed tables, allowing users to perform semantic similarity searches and RAG on their unstructured data.
- Provide comprehensive support through reference architectures and examples, ensuring that users across industries can quickly implement and benefit from the integration.
Another key aspect of this integration is its ease of use for existing kdb+ users. The introduction of a q API makes it intuitive for q programmers to leverage advanced pattern matching and similarity search capabilities using a familiar language.
gw:hopen 8082
gw(`createTable;
`database`table`externalDataReferences!
(`default;`trade;enlist `path`provider!("/db";`kx)))This familiarity accelerates adoption and enables organizations to capitalize on their existing data infrastructures.
Industry use cases for similarity search
Temporal Similarity Search (TSS)
Integrating kdb+ with KDB.AI enables Non-Transformed Temporal Similarity Search on raw time series data without migrating and enables the following key capabilities:
Pattern matching
Using Temporal Similarity Search (TSS) integrated with kdb+ and KDB.AI enables the rapid identification of similar patterns at scale. This can be applied across various industries, such as finance, telecommunications, energy management, and transportation.
table.search(
{"price": patterns()},
type="tss",
n=5,
filter=[("=", "sym", "AAPL")],
options=dict(force=True, returnMatches=True))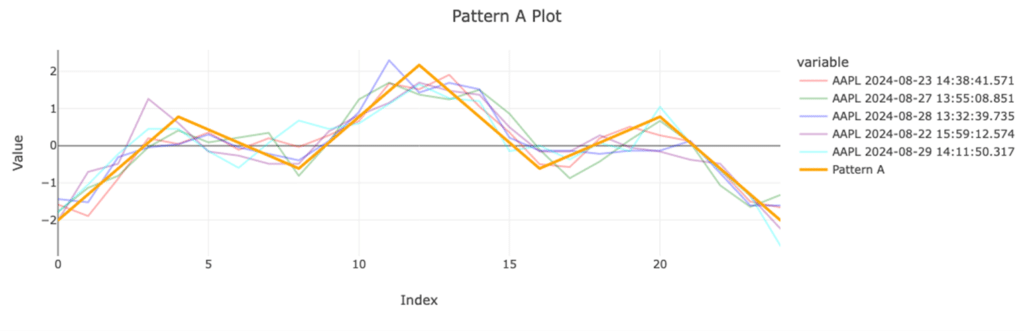
For instance, in finance, Temporal Similarity Search could detect indicative patterns in price and volume data to aid in trading decisions, while in telecommunications, it could predict and prevent network outages by identifying usage patterns. Similarly, energy management benefits from recognizing consumption patterns to optimize distribution, and urban planners could use traffic flow patterns detected through Temporal Similarity Search to reduce congestion.
Anomaly detection
Temporal Similarity Search facilitates anomaly detection by identifying patterns that deviate from historical data. For example, it can help recognize changes in customer behavior, prompting proactive outreach in the retail and service sectors. It can detect equipment performance anomalies in manufacturing, preventing failures and downtime. Additionally, it plays a vital role in spotting data quality issues in real-time data feeds and recognizing unusual patterns in sensor data for predictive maintenance. This comprehensive capability makes Temporal Similarity Search a powerful tool for ensuring operational efficiency and strategic decision-making across diverse fields.
table.search(
{"price": patterns)},
type="tss",
n=-5,
filter=[("=", "sym", "NVDA")],
options=dict(force=True, returnMatches=True))Similarity search
There is also the option to store embedding representations of unstructured data within kdb+ splayed tables. This enables vector similarity searches and Retrieval Augmented Generation for semantically similar data.
For example, in finance, trading firms could retrieve historical market conditions that resemble the current state for better decision-making. Similarly, engineers could detect quality issues in manufacturing by analyzing maintenance logs and technician reports.

Integrating kdb+ with KDB.AI allows organizations to maximize the value of their existing data without needing to migrate. It enables semantic search on stored embeddings for unstructured data insights and the rapid identification of patterns, anomalies, and similarities in extensive datasets.
To learn more, check out our latest documentation, or view our migration guide, and sample on GitHub.


