
ポイント
- AI libraries combine semantic vector search, BM25 keyword search, and time-series similarity search to enable fast retrieval across structured and unstructured data.
- HNSW, and IVF-PQ indexing methods, let users balance speed, accuracy, and memory efficiency for thousands to billions of vectors.
- BM25, hybrid, and fuzzy matching achieve higher precision and flexibility in keyword search.
- Temporal similarity search (TSS) and dynamic time warping (DTW) enable powerful comparisons of market data, sensor logs, and live machine signals.
We’ve just released the new AI libraries module for KDB-X, built to make search faster, smarter, and easier to scale. The module combines advanced semantic vector search and BM25 keyword search for unstructured data, as well as time-series similarity search (TSS) for structured data, two capabilities essential for real-world systems that work with documents, logs, market data, and live signals.
In this article, we’ll take a closer look at what’s inside: vector indexing methods, complementary retrieval techniques, and time-series search. Each one is designed to help you move from raw data to fast, accurate results, without adding latency or complexity.
Let’s explore
Vector search
KDB-X utilizes its AI libraries module for vector indexing and search by applying algorithms to high-dimensional embeddings stored within the database. These algorithms map vectors into specialized data structures, making similarity search far faster than scanning raw embeddings. To handle different workload scales, KDB-X supports multiple indexing methods (Flat, HNSW, IVF-PQ), each balancing accuracy, speed, and memory.
Once embeddings are stored in a KDB-X index, they become readily searchable, enabling a variety of use cases, including document search, retrieval augmented generation (RAG), image similarity search, and temporal similarity search (TSS).
Get hands-on with tutorials via our GitHub.
KDB-X vector indexes
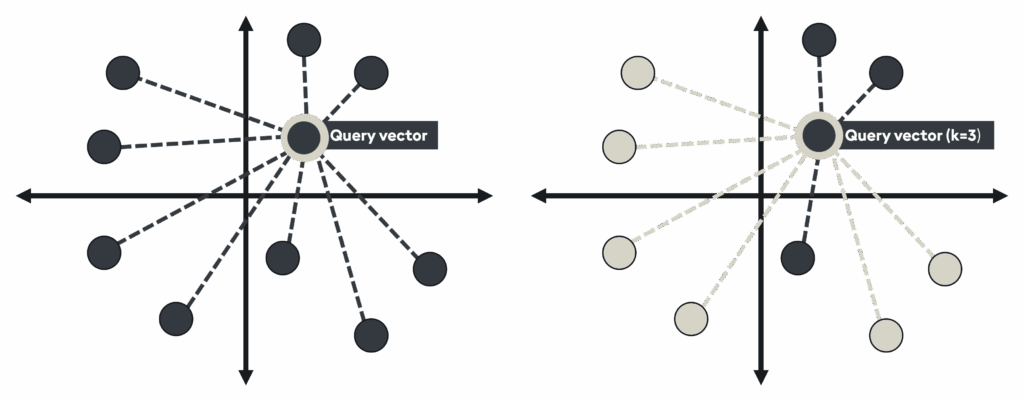
Brute force (Flat)
Flat indices (otherwise known as “brute force”) compare every vector against the query vector to find the exact nearest neighbors. It operates via a linear scan using a distance metric (e.g., cosine, L2) and ensures exact results, with predictable computational scaling.
When to use
- Small collections (thousands to a million vectors), lower dimensionality means faster search
- Quality-critical scenarios where exactness beats speed
- Cold‑start evaluation and ground‑truth benchmarking for ANN methods
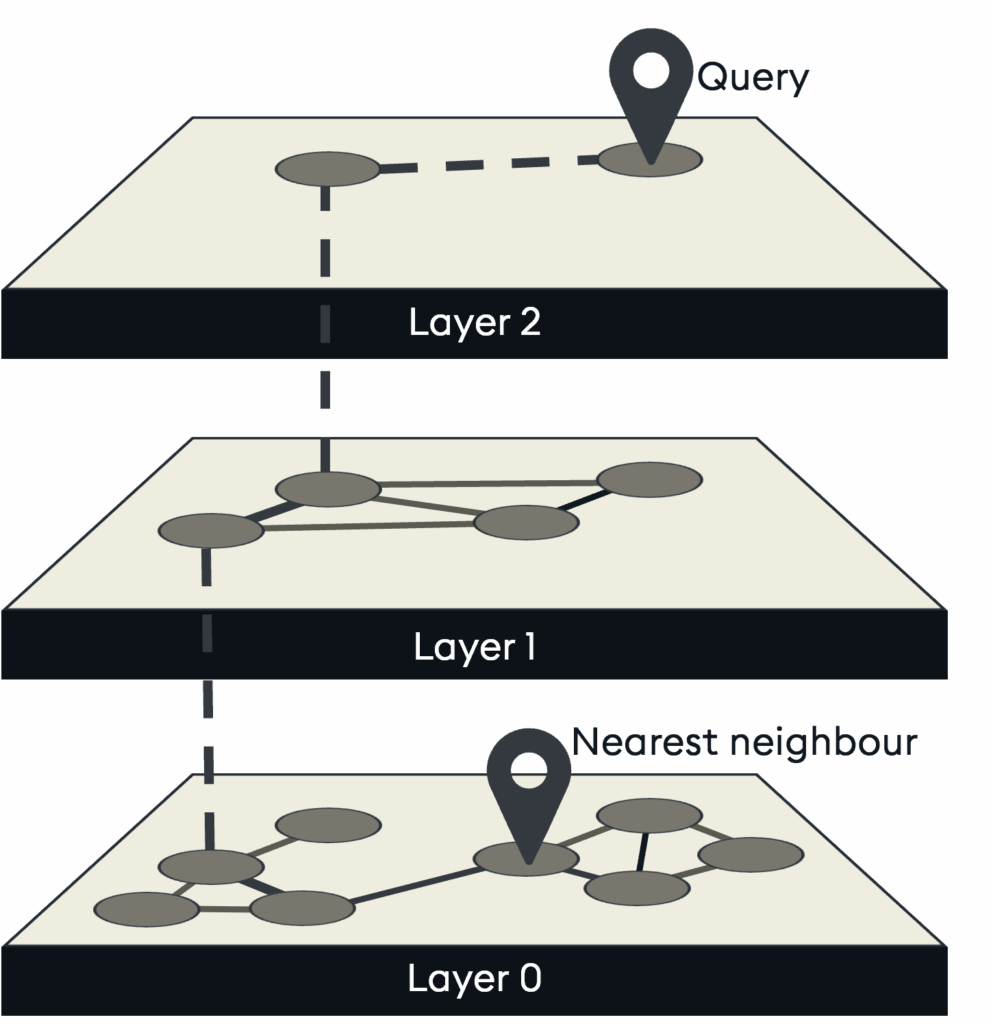
Hierarchical navigable small worlds (HNSW)
Graph indices, such as HNSW, utilize a graph-based approximate nearest neighbor (ANN) algorithm to achieve low-latency search on large datasets with high recall. They work by building a multi-layer small-world graph, where queries traverse from top to bottom to rapidly find their nearest neighbors.
When to use
- Large corpora (millions to tens of millions of vectors)
- Interactive latency requirements (sub‑100ms)
- High recall where near‑exactness is sufficient
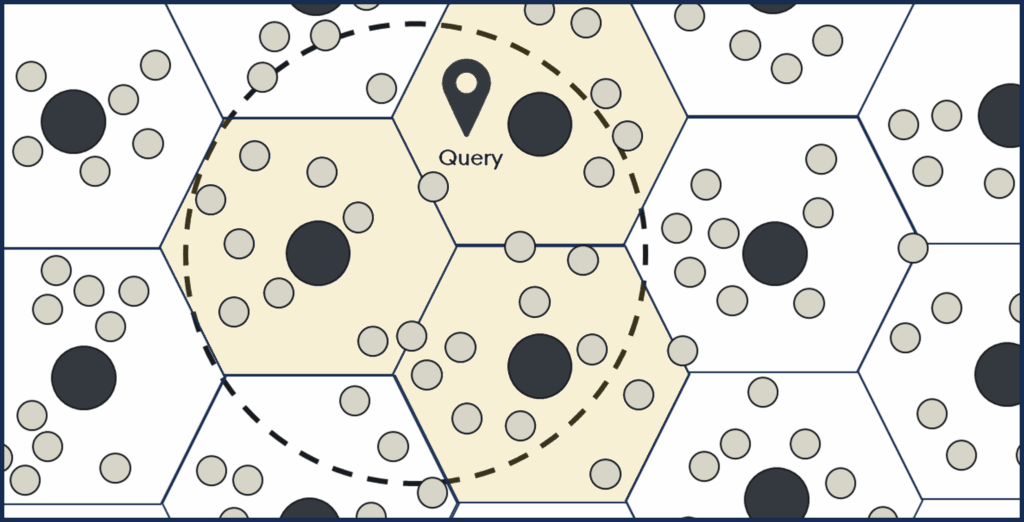
Inverted file (IVF) & IVF-PQ
IVF (Inverted file index) speeds up nearest neighbor search by clustering the dataset into coarse groups (cells) and only searching the clusters closest to the query. IVF-PQ (Inverted file with product quantization) adds compression by splitting each vector into smaller parts and storing short codes instead of full-precision values. This enables faster and more memory-efficient searches on very large datasets.
Complementary retrieval methods
Extend beyond pure dense vector search, using keywords, hybrid strategies, or fuzzy matching to improve precision.
Best matching 25 (BM25)
BM25 is used in information retrieval to score the relevance of a document to a search query. It’s based on term frequency (how often a word appears in a document), inverse document frequency (how rare the word is across all documents), and document length normalization. It is widely used for keyword-based search in text corpora because it balances the importance of matching terms with their distinctiveness and document size.
Use cases
- Financial services: Use to rank analyst reports, research notes, or filings by relevance to a keyword search (e.g., “interest rate risk”) instead of just returning keyword matches
- Aerospace and Defense: Use to search large maintenance logs or technical manuals to find the most relevant sections for a specific fault code or procedure
- High-speed manufacturing: Use to retrieve the most relevant troubleshooting guides or incident reports for an equipment error code
Hybrid search
Hybrid Search combines multiple retrieval methods, typically vector search (semantic similarity) and keyword search (exact term matching), to deliver more relevant results. It balances the precision of keyword-based approaches, such as BM25, with the flexibility of vector similarity methods, like HNSW or IVF, making it effective when both meaning and exact matches are important.
Use cases
- Financial services: Retrieve analyst reports that both mention “inflation” explicitly (keyword) and discuss related concepts like “consumer price growth” (semantic)
- Aerospace and Defense: Search maintenance logs for exact fault codes while also retrieving entries that describe similar symptoms in different terminology
- High-speed manufacturing: Find production notes that include the exact defect code plus similar cases described in different words or languages
Fuzzy matching
Fuzzy matching is a technique for finding items in a dataset that are similar to a given input, even if they aren’t exact matches. It’s useful when dealing with typos, alternate spellings, OCR errors, or slight variations in data.
Use cases
- Financial services: Use to match client names across systems despite spelling errors or formatting differences (e.g., “J.P. Morgan” vs “JP Morgan Chase”)
- Aerospace and Defense: Use to identify parts or equipment in inventory records when catalog entries contain inconsistent naming or abbreviations
- High-speed manufacturing: Use to detect and link similar defect labels or machine error codes entered differently by operators
Time series search
Working with time-series data isn’t just about matching values; it’s about matching patterns, sequences, and events as they unfold over time. With KDB-X, the new AI libraries module features two powerful approaches for searching and comparing temporal data: Temporal similarity search (TSS) and dynamic time warping (DTW).
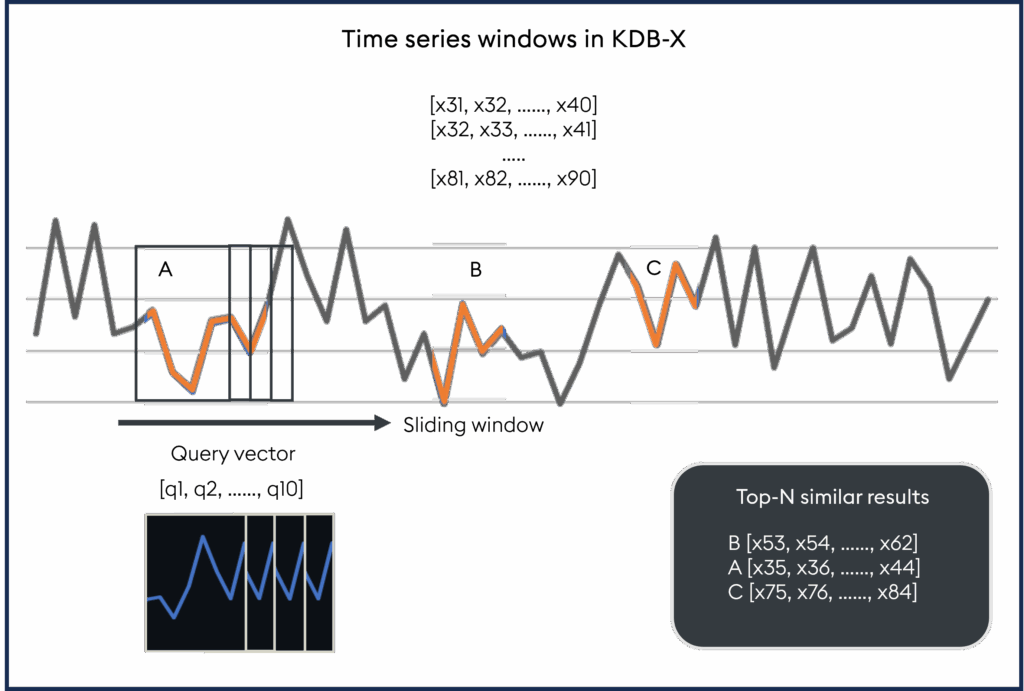
Temporal similarity search (TSS) uses sliding-window comparisons to quickly scan large time-series datasets for regions that resemble a query sequence. TSS is ideal when you need fast, approximate matches to identify repeating patterns, trends, or anomalies across massive streams of numeric data.
Dynamic time warping (DTW), on the other hand, focuses on accuracy and flexibility. DTW aligns sequences that may vary in speed or timing, making it especially valuable when comparing events that happen at different rates or phases. For example, two machines might exhibit the same failure pattern, but one drifts more slowly than the other; DTW can still recognize them as similar.
Together, TSS and DTW give you a toolkit for both high-throughput pattern detection and nuanced sequence alignment.
Use cases
- Financial services: Detect historical market periods whose price movements closely match a current trend for strategy backtesting or risk analysis
- Aerospace and Defense: Match recent engine sensor readings to past flight test sequences that led to known failures
- High-speed manufacturing: Compare live machine telemetry to historical patterns that preceded defects or breakdowns
With KDB-X, the new AI libraries module combines optimized vector search on unstructured data and time-series similarity search on structured data into a single platform. These capabilities are designed to scale across large data estates, enabling faster, more accurate, and production-ready retrieval.
If you enjoyed this blog and would like to explore examples, you can visit our GitHub repository. You can also begin your journey with KDB-X by signing up for the KDB-X Community Edition Public Preview.




