

ポイント
- Capital markets systems can be understood as interconnected analytic workflows spanning research, execution, and governance.
- These workflows are not separate systems but different access patterns over a shared data foundation.
- Data quality, consistency, and time alignment directly determine the effectiveness of every workflow.
- AI introduces stricter requirements on data design, including reproducibility, schema consistency, and support for mixed data types.
- Scalable architectures rely on reusable patterns and blueprints to connect workflows into a coherent, production-ready system.
KX has worked with capital markets firms for close to three decades. Over that time, kdb+ (now KDB-X) has been deployed across banks, hedge funds, and market infrastructure, often in the most performance-sensitive parts of their systems. This provides a broad view across asset classes, trading horizons, and organizational models, and repeated exposure to how systems are built, evolve, and interact across multiple workflows under real constraints.
This view is not tied to a single architecture or generation of technology. It reflects patterns that recur as systems scale, and it is the basis for the language we will use throughout this material. Different firms, starting from different points, converge on similar solutions.
The diagram below captures the most common structure.
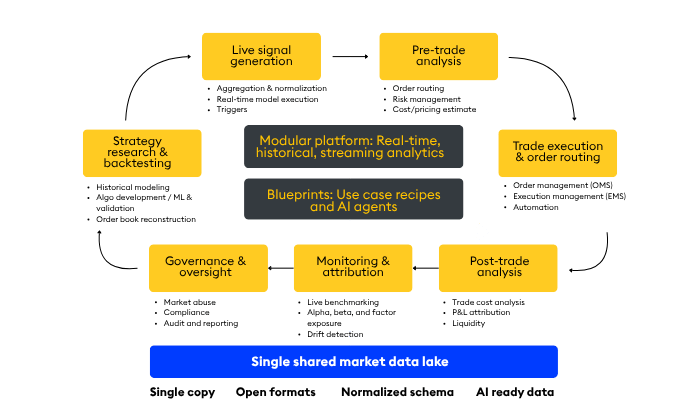
A workflow model of trading systems
At a high level, most trading organizations can be understood as a set of interconnected workflows: research and backtesting, live signal generation, pre-trade analysis, execution, post-trade analysis, monitoring, and governance and oversight.
Research and backtesting consume curated historical data to develop and validate models, producing signals, features, and evaluation metrics that feed forward into production.
Live signal generation ingests real-time data, applies transformations and models, and emits signals with strict latency constraints, handing off to pre-trade analysis.
Pre-trade analysis combines signals with positions, risk limits, and cost models to produce orders and routing intent, which interface with execution systems.
Execution handles order lifecycle and market interaction, returning acknowledgements, fills, and market feedback to downstream workflows.
Post-trade analysis reconstructs events and evaluates outcomes (e.g. TCA, P&L attribution), feeding insights back into research and model calibration.
Monitoring provides continuous views of system behavior and performance, surfacing anomalies and drift to operators and quants.
Governance and oversight require consistent, point-in-time views across all stages to audit decisions and ensure compliance, including surveillance (e.g. market abuse), best execution analysis, regulatory reporting, audit trails, and model and decision lineage. These are not independent systems; they are different access patterns over the same underlying data, each with distinct latency, consistency, and functional requirements.
The role of execution systems
Trade execution and order routing sit within this model but are often implemented using highly specialized technologies, including hardware-accelerated systems. While these components are critical, they are not the primary focus of the material here. Instead, the emphasis is on the workflows immediately around them, where data is prepared, decisions are made, and outcomes are analyzed. These surrounding workflows are where kdb+ is most heavily applied and where consistency of data and logic has the greatest impact.
The data foundation behind every workflow
That underlying market data is not itself a workflow, but it enables all of them. Without timely, accurate, and sufficiently broad data, these activities are not effective. The data foundation sets the ceiling on what each workflow can achieve. Timeliness affects whether decisions can be acted on, accuracy whether they are correct, and reach how completely the market is represented. Firms that invest in this layer treat it as a direct source of competitive advantage.
AI raises the bar on data design
AI now appears across these workflows: in research, signal generation, execution optimization, post-trade analysis, and surveillance. This raises the bar on the data itself. It must be usable for training and inference, not just queryable. That requires consistent schemas, clear time semantics, reproducibility, and the ability to combine structured and unstructured sources. AI-ready data is becoming table stakes and imposes additional discipline on how the data foundation is designed and maintained.
Convergence across the lifecycle
Over time, the separation between well-integrated workflows becomes less distinct. Data is reused across contexts, logic moves from research into production, and post-trade analysis feeds back into model development. As these feedback loops tighten, the system operates on shorter cycles, and the distinction between stages becomes less about structure and more about latency and purpose. Consistent data across these workflows also enables governance to accurately reason about decisions that span multiple stages of the lifecycle.
From fragmented systems to shared foundations
Systems that hold together treat these workflows as different access patterns over a shared foundation rather than independent stacks. That foundation is defined by consistency of data, continuity between real-time and historical views, and support for multiple workloads without fragmentation.
As systems grow into this structure, the need for consistent implementation patterns becomes clear. Blueprints and Reference Architectures capture those patterns in a form that can be reused.
From model to implementation
The workflow model provides the language we will use to position concrete implementations. Blueprints are anchored in one or more workflows. Reference Architectures describe how components can be combined and deployed to instantiate workflows. Reusable modules and accelerators are introduced in terms of the role they play within this structure.
The goal is to make explicit what is often implicit and to establish a common language for describing these systems. Experienced kdb+ users will recognize these patterns. For newer users, this provides a way to place individual components in a larger system and to reason about how that system will evolve.
There is no single correct architecture. Firms make different trade-offs based on their priorities. This model is a frame of reference, grounded in experience, for reasoning about those trade-offs consistently.
What comes next
This model is intended as a foundation. The next step is to move from description to implementation—showing how specific workflows can be built, operated, and scaled using consistent patterns.
In the next piece, we will introduce a Blueprint that takes one of these workflows and walks through it in detail: how data is structured, how logic moves from research into production, and how real-time and historical views are aligned to support both decision-making and governance.
Learn more about KDB-X, the next generation of kdb+, designed to support modern AI and data workloads in capital markets without the complexity of fragmented systems.


