

ポイント
- KX Nano is an open-source benchmark tool designed to evaluate hardware performance from the perspective of kdb+.
- KX Nano focuses on executing fundamental kdb+ operations, providing granular insights into hardware performance, including sequential and random read and write tasks, as well as aggregation, serialization, and vector operations.
- KX Nano thoroughly investigates the core components of your system through rigorous tests for storage, memory, and CPU.
KX has a long-standing reputation for prioritizing performance and maximizing the potential of available hardware. This commitment is evident in our constant collaboration with hardware vendors, independent reports, and the world records achieved via STAC-M3TM benchmarking.
STACTM, considered the gold standard in high-speed analytic testing, captures the performance of the entire solution, including database software, compute resources, networking, and storage. However, it is closed-source and challenging to replicate. Fortunately, there are other tools readily available, including KX Nano, an open-source toolkit designed to calculate raw CPU, memory, and storage I/O capabilities.
Nano features:
- Comprehensive hardware testing: Nano investigates the deep core components of your system. It includes rigorous tests for storage, memory, and CPU, specifically stressing L1, L2, and L3 caches
- Low-level kdb+ operations: Nano focuses on executing fundamental kdb+ operations, including sequential/random read/write tasks together with aggregation (e.g. sum and sort), serialization, compression, and vector operations (opening a file)
- Stress testing capabilities: Nano employs a clever approach to simulate demanding workloads. The main bash script initiates multiple kdb+ worker processes and a kdb+ controller, then directs these workers to execute the same operation simultaneously. Some of these operations are multi-threaded. This places a significant load on the hardware, particularly on the filesystem or on the memory, helping to identify bottlenecks and limitations
- Modular and extensible: Recognizing that every testing scenario is unique, KX designed Nano to be highly modular and extensible. Clients and hardware vendors have requested and contributed new tests in the past, making it a continuously evolving tool
- Configurable and customizable: Whether you want to compare the performance of flagship AMD CPUs against AWS Graviton and Intel CPUs using the cpuonly mode or are curious about how FSx Lustre or Rook Ceph run hundreds of parallel random reads across thousands of memory-mapped files, Nano offers complete flexibility and test customization
Getting started with Nano is straightforward. Specify the data directory where the kdb+ processes will persist data and run the script with the default values.
$ git clone https://github.com/KxSystems/nano.git
$ cd nano
$ echo "/mnt/nvme1/nanotest " > partitions # specify the data directory
$ source ./config/kdbenv # load kdb+ environment
$ source ./config/env # load default benchmark values
$ ./nano.sh
You can also adjust parameters, including the number of kdb+ worker processes and the number of threads per worker.
$ THREADNR=8 ./nano.sh --processnr 32 –-scope cpuonlyThe script nano.sh generates a rich result file in PSV (pipe-separated values) format, where each line captures detailed test metrics and metadata. Every entry includes essential test information, such as the test name and the corresponding q expression, along with specific hardware components being stressed (e.g., CPU, memory, or disk). Additionally, each record contains the measured performance value, allowing for straightforward parsing and analysis. This structured output facilitates performance benchmarking and hardware profiling by organizing key data points in a consistent, machine-readable, and human-readable format.
For future reference and reproducibility, nano.sh also captures hardware information, such as the output of lscpu and numactl, and creates a config.yaml that stores the most important hardware and software settings (e.g, the number of CPUs or the kdb+ version used).
Case study
Advanced Micro Devices (AMD) is a leading semiconductor company that designs and develops a range of products, including central processing units (CPUs), graphics processing units (GPUs), and system-on-chip (SoC) solutions, catering to markets such as data centers, gaming, and embedded systems.
KX Nano was tested on two generations of AMD EPYCTM based systems, 4th-generation AMD EPYC processors (codenamed “Genoa”) and 5th-generation AMD EPYC processors (codenamed “Turin”).
The CPU tests in nano.sh measure the performance of various kdb+ operations on vectors of different sizes, targeting different levels of the memory hierarchy. For example:
- The test “med float large” benchmarks the median calculation on a large floating-point vector
- “18! int tiny” evaluates how quickly a small integer vector can be serialized and compressed.
These tests are designed to stress different parts of the system: small vectors fit in L1/L2 CPU caches, medium-sized vectors test L3 cache, and large vectors exercise main memory bandwidth. Both integer and floating-point operations are included to assess arithmetic performance across data types. The workload includes operations with different memory access patterns: some, like “reciprocal”, read and generate new vectors (testing read-write throughput), while others, such as “sum”, are read-heavy.
Additionally, a random vector generation test evaluates pure memory write performance. The throughput of each operation is derived from the vector size divided by execution time, providing a measure of elements processed per second.
To summarize overall CPU performance, the geometric mean of these results is computed, offering a balanced aggregate metric across different test scenarios.
Benchmarks
Three benchmarking scenarios were conducted1:
- Scenario 1: One kdb+ worker – One thread/kdb+ worker, which stresses the performance of a single core
- Scenario 2: Max kdb+ workers – One thread/kdb+ worker, which tests the performance of the entire system and deploys as many kdb+ workers as there are available threads in the system
- Scenario 3: N kdb+ workers – Eight threads/kdb+ worker, which tests the performance of the entire system and allows for variation in the number of threads/kdb+ worker
For all three of the scenarios, the geometric means across all vector sizes were calculated against the following test groups:
| Test group | Tests |
| CPU cache – Tests stress L1 and L2 cache |
|
| Mem – Tests access L3 cache and main memory |
|
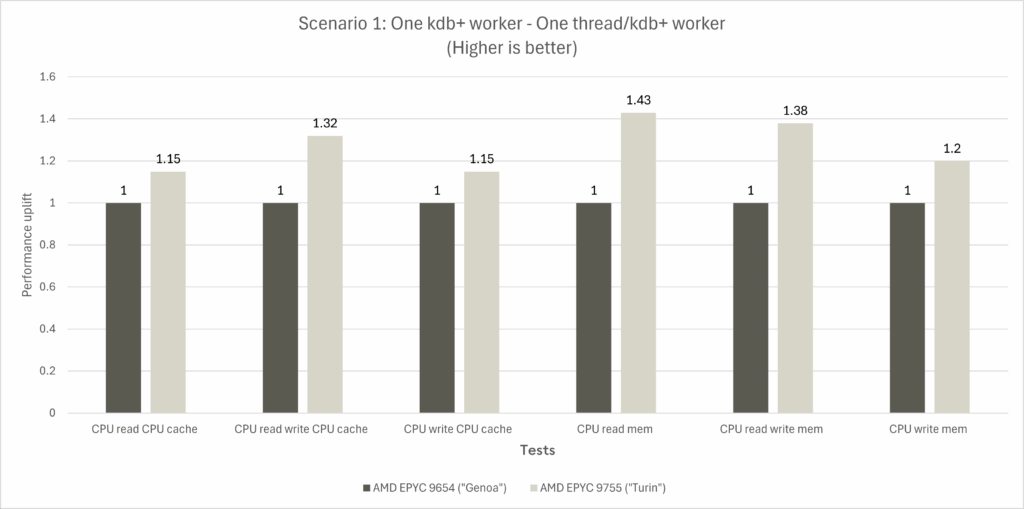
Scenario 1 outcome
- A single Turin thread executing a single kdb+ worker outperforms the same configuration on Genoa by up to 32% in the CPU read-write test among the “CPU cache” test group
- Turin outperforms Genoa by up to 43% in the CPU read test amongst the “mem” test group
Given the multi-threaded nature of the Nano benchmarking suite, scenarios 2 and 3 are more representative of system-level production deployments.
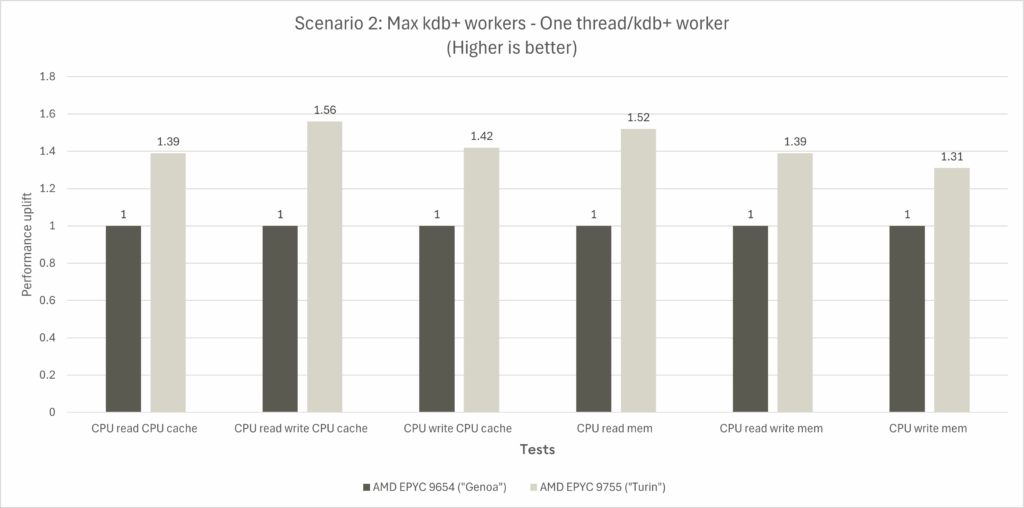
Scenario 2 outcome
- One thread is allocated per kdb+ worker
- Genoa runs 192 kdb+ workers across a two-socket 2P system (96 per socket)
- Turin runs 256 kdb+ workers across a two-socket 2P system (128 per socket)
- All cores were observed to execute at 100% CPU utilization, maximizing the compute capacity of the systems under test
Greater generational performance improvements are observed in scenario 2.
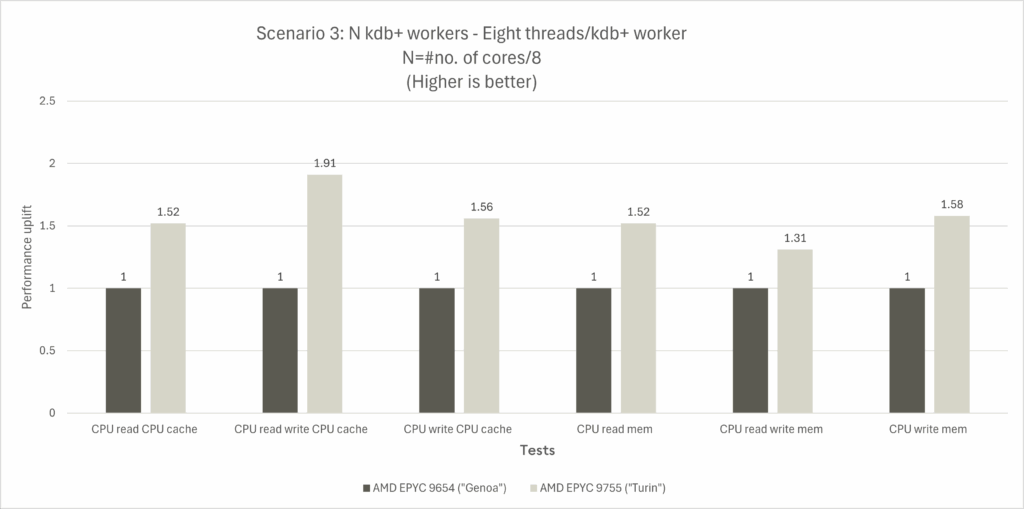
Scenario 3 outcome
- A variable number of threads can be allocated per kdb+ worker. Given the eight-core/CCD configurations of both “Zen 5” and “Zen 4” cores, a decision was made to assign eight threads per kdb+ worker
- Dividing 192 threads of the two-socket Genoa system by eight yields a total of 24 kdb+ workers
- Dividing 256 threads of the two-socket Turin system by eight yields a total of 32 kdb+ workers
- Interestingly, although all cores were under load, it was observed that CPU utilization varied across tests, compared to the 100% CPU utilization observed across all cores in Scenario 2
- The highest extent of generational performance improvement is observed in Scenario 3, with a maximum performance uplift of 1.91x for the CPU read-write test in the “CPU cache” test group
Some test-level details are summarized below. The benchmarks used a large vector filled with semi-random floating-point numbers to evaluate performance. The graph displays execution time ratios, where a value of 1.6 indicates that the Turin CPU completed the test 60% faster than the Genoa CPU. This normalization allows for straightforward comparison across different hardware configurations.
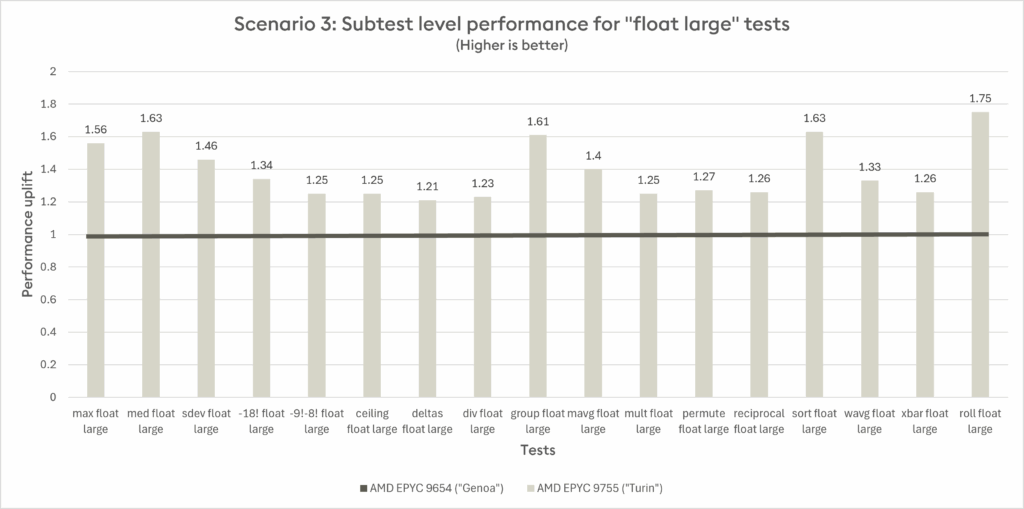
Scenario 3 (subtest level performance) outcome
Turin consistently outperforms Genoa across the “float large” subtests.
System under test
| AMD EPYC 9654 | AMD EPYC 9755 | |
| Server model | AMD CRB “Titanite” | AMD CRB “Volcano” |
| Processor | 9654 | 9755 |
| Socket | 2 | 2 |
| Cores per socket | 96 | 128 |
| Frequency | 2.4 GHz/3.7 GHz | 2.7 GHz/4.1 GHz |
| L1d/L2/L3 | 6 MiB/192 MiB/ 768 MiB | 12 MiB/ 256 MiB/ 1 GiB |
| NUMA nodes | 2 | 2 |
| Memory | 1.5 TB | 2.3 TB |
| Memory module size | 64 GB | 96 GB |
| Memory speed | DDR5/4800 MT/s | DDR5/6400 MT/s |
| Memory channels | 24 | 24 |
| OS | RHEL 9.5 | RHEL 9.5 |
| Kernel | 5.14.0-503.11.1.el9_5.x86_64 | 5.14.0-503.40.1.el9_5.x86_64 |
| SMT | OFF | OFF |
| Determinism | Power | Power |
| Nano version | 6.2 | 6.2 |
| *CRB = customer reference board | ||
While both AMD EPYC processor families are designed to advance data center and enterprise computing, the 5th Generation AMD EPYC processors released in October 2024 bring the latest technological advancements, including the following.
- Zen 5 and Zen 5c cores are produced using 4nm and 3nm process technology, respectively, featuring up to 17% higher instructions per clock (IPC) for single-threaded tasks.
- Increased core density, offering up to 192 cores from the previous maximum core counts in 4th Generation AMD EPYC of 96 cores with “Genoa” and 128 cores with “Bergamo”
- Enhanced memory with DDR5 6400 MT/s speeds supported via the 6nm process I/O die.
You can learn more about the AMD EPYC processors via the following links:
- 5th Gen AMD EPYC™ Processors Lead Enterprise and Cloud Workloads Forward
- 5th Gen AMD EPYC™ Processor Architecture
- 4th Gen AMD EPYC™ Processor Architecture
- 5th Generation AMD EPYC™ Processors Model Specifications
1Simultaneous multithreading SMT=OFF and SMT=ON were both tested. As SMT=ON (whereby a single core can execute two threads concurrently) was observed to provide performance improvement in some cases and performance degradation in others, the choice was made to opt for SMT=OFF (whereby a single core operates as a single thread) to report optimal results across the geomeans.
KX Nano is an open-source tool. We encourage you to explore its capabilities, contribute your enhancements, and add tests. By fostering a collaborative environment, the tool can become even more robust and beneficial for the entire kdb+ community.
Visit our GitHub repository to learn more.




