

Developer
Apex innovators: How hedge funds can evolve analytics at speed and scale

Harnessing hedge fund analytics for real-time insights, seamless data integration, and ultra-low latency execution.
Download our ebook to uncover how to seamlessly integrate data, scale with market demands, and transform analytics into competitive advantage.
Key Takeaways
- Hedge funds gain more advantage from timely, context-rich insights than from pure reaction speed.
- High-fidelity, point-in-time data is essential for building models that behave reliably in both research and production.
- Unified access to real-time and historical datasets eliminates fragmentation and accelerates quant iteration cycles.
- Accurate pattern and trend detection depends on granular microstructure data and scalable pipelines.
- Combining structured and unstructured data creates deeper contextual understanding and strengthens predictive signals.
In financial markets, speed is often heralded as the ultimate competitive advantage. Many market-making firms, particularly those engaged in high-frequency trading, invest heavily in ultra-low latency systems that process data in microseconds so they can capture fleeting microstructure opportunities. This type of trading depends on reacting first, competing at the top of the order book, and managing inventory risk over extremely short horizons. Hedge funds operate under different conditions. Their strategies rely less on beating others to the next tick and more on understanding how signals behave across time, venues, and regimes. For these teams, the real advantage comes from generating accurate, context-rich insights at the moment they are needed, rather than simply reacting the fastest.
As recent volatility has shown, markets change direction with little warning, liquidity conditions shift in irregular ways, and the volume of available data continues to expand at an extraordinary pace.
Hedge funds are now dealing with faster signal decay, frequent regime changes, and a growing range of data sources that influence price behaviour. Traditional research workflows struggle to keep up because they rely on historical datasets that are difficult to align with real-time market conditions. Backtests often fail to capture execution behaviour with precision. Data remains scattered across multiple systems, which introduces inconsistencies that slow down analysis. Many research teams also experience long iteration cycles because their pipelines cannot scale effectively to handle modern tick-level data.
In this environment, a meaningful advantage comes from producing insights that are accurate, reliable, and grounded in both real-time and historical context. Quant teams need information that reflects current market structure, preserves historical truth, and supports rapid exploration of new ideas. The ability to generate timely, high-fidelity insights directly influences the speed and quality of model development, the confidence researchers have in their results, and the performance of strategies once they are deployed.
For quants, this capability is becoming essential. It strengthens signal discovery, reduces uncertainty during model promotion, and improves the overall strategy development process.
The difference between fast data and timely data
Many firms focus on processing speed, but raw speed can produce streams that arrive quickly while still lacking structure or context. Quantitative research requires something more complete.
Fast data:
- Prioritises low latency
- Often arrives without the filtering, alignment, or enrichment needed for modelling
- Provides limited support for rigorous validation
Timely data:
- Delivers information when it is needed in the research cycle
- Preserves context by aligning historical truth with real-time updates
- Supports informed decision-making throughout model development
Acting on fast but incomplete data leads to inconsistent model performance and unreliable outcomes after deployment. Timely, high-fidelity data allows quants to validate assumptions, refine signals, and build strategies with greater confidence.
Why time-series fidelity matters
High-quality time-series data is the foundation of reliable quant research. Models depend on accurate representation of market behaviour across both time and venue. This includes the ability to reconstruct the true order book sequence so that features such as queue position changes, cancellation patterns, and spread transitions can be analysed and modelled correctly.
Key requirements include:
Granular insights at tick-level resolution
Tick-level data reveals the microstructure signals that influence fill probability, such as order replenishment rates, order book reshuffling, or bursts of hidden liquidity.
Point-in-time accuracy without look-ahead bias
Backtests must reflect the data that was available at the moment of decision. Even small timestamp misalignments or missing fields can distort strategy performance.
Unified access to real-time and historical data
Separating datasets introduces drift and duplicates logic across environments. Unified access supports consistent data preparation and feature engineering.
Consistent datasets across research and production
Fragmentation creates mismatched features, duplicated code, and unpredictable behaviour in production. Consistency allows researchers to attribute strategy outcomes to real market behaviour rather than environmental differences.
How high-fidelity time-series analytics accelerate quant research
The most effective quant teams combine accuracy, historical context, and real-time insight within a single workflow. High-performance time-series analytics create an environment where researchers can move quickly while maintaining the precision required for production-ready models.
1. Stronger signals built from real-time and historical alignment
When real-time feeds and multi-year historical datasets sit in one environment, researchers can understand how current market conditions relate to deeper structural patterns. This supports clearer comparisons, more reliable signal testing, and faster validation of early hypotheses. For example, researchers can examine whether order book imbalance patterns during stress events mirror or diverge from those in past volatility cycles.
This allows quants to:
- Compare live behaviour with historical patterns in context
- Understand how volatility regimes form and shift
- Identify meaningful correlation changes across assets or venues
- Move from concept to validated strategy with fewer bottlenecks
2. Faster iteration with scalable and efficient data pipelines
Tick-level datasets place heavy demands on research infrastructure. When pipelines scale cleanly with data volume, researchers can test more ideas, explore more variations, and complete more cycles in less time. This includes running simulations with partial fills, venue routing variations, and slippage models that match observed behaviour.
This enables quant teams to:
- Run deeper backtests across years of tick data without downsampling
- Evaluate more scenarios and model variations in parallel
- Reduce delays caused by pipeline failures or inefficient compute
- Limit engineering dependencies that slow down experimentation
3. Higher predictive accuracy through rich pattern and trend detection
Accurate models depend on detailed insight into liquidity, order flow, and price formation. High-fidelity time-series data preserves these details and helps researchers uncover subtle shifts that influence predictive behaviour. This includes changes in sweep order activity, liquidity replenishment speed, or queue dynamics that precede spread movements.
With better pattern visibility, quants can:
- Detect emerging signals earlier and with more precision
- Capture liquidity dynamics and spread movements accurately
- Identify regime changes that influence model stability
- Produce more resilient models that hold up under new conditions
4. Reduced fragmentation and more reliable production outcomes
Fragmented data environments create inconsistencies between research and production. When datasets and logic are unified, models behave more consistently and production outcomes become easier to trust. Drift becomes easier to detect because feature distributions, prediction errors, and execution costs can be monitored against historical baselines in real time.
A unified approach helps researchers:
- Maintain consistent feature engineering across the lifecycle
- Produce backtests that reflect real production behaviour
- Identify drift earlier through live-versus-research comparisons
- Move strategies into production without extensive rework
5. Richer context through combined structured and unstructured data
Market behaviour is shaped by information that extends beyond standard price and volume feeds. Text disclosures, sentiment indicators, news reports, transcripts, imagery, and other unstructured sources add context that strengthens modelling and hypothesis generation. For example, transcript embeddings can be aligned with intraday market moves to understand how tone, guidance, and language patterns relate to volatility or liquidity shifts.
Dual-mode data environments allow quants to:
- Link market reactions to corporate disclosures or narrative shifts
- Build features based on sentiment, language patterns, and behavioural cues
- Study how alternative data influences liquidity and volatility
- Combine structured and unstructured insights within a single workflow
How KX supports quant research at scale
KX provides a unified, high-performance environment that supports the full lifecycle of quantitative research. It offers real-time and historical data processing within a single system and enables large-scale experimentation without compromising accuracy.
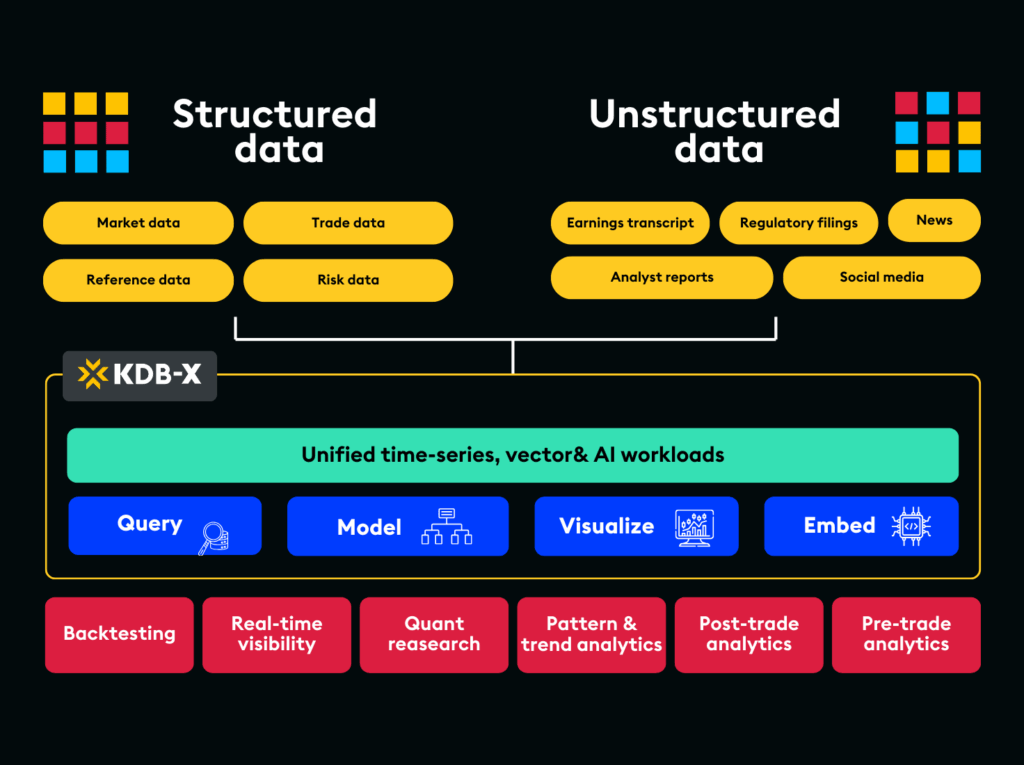
With KX, quant teams can:
- Run backtests up to 30 times faster across large tick datasets, enabling deeper simulations without compromising on data quality.
- Replay full market sessions at tick-level fidelity, including order book depth, sequencing, and execution modelling.
- Process real-time and historical data in one environment, removing data silos and reducing logic duplication.
- Detect drift within milliseconds, using live-versus-research comparisons to catch performance degradation before it affects P&L.
- Deploy models in Python without rewriting code, supported by a unified Python-native interface.
- Explore more strategy variations per cycle, with some quant teams reporting the ability to ship up to three times more validated models per quarter.
- Reduce infrastructure and operational costs, with some firms achieving up to an eighty percent reduction by consolidating pipelines into a single platform.
This combination allows quants to move from hypothesis to validated model with significantly more speed while maintaining consistent behaviour at deployment.
The path to smarter, faster insight
Speed is still important in hedge fund analytics, but speed without accuracy offers limited value. The real advantage comes from insight that is timely, precise, and fully contextualised. When quant teams have unified access to high-fidelity data, they can refine models more quickly, test strategies more thoroughly, and deploy with greater confidence.
To learn how leading hedge funds are using KX to strengthen quant research workflows and improve strategy performance, read our ebook.
Apex innovators: How hedge funds can evolve analytics at speed and scale
Harnessing hedge fund analytics for real-time insights, seamless data integration, and ultra-low latency execution.
Download our ebook to uncover how to seamlessly integrate data, scale with market demands, and transform analytics into competitive advantage.

