

Key Takeaways
- Video content is inherently multimodal. Visuals and audio/text must be embedded together to capture their relationship.
- Traditional video RAG pipelines, which embed frames individually and rely on cosine similarity, are now considered outdated.
- Multimodal models like voyage-multimodal-3 can produce dense vector representations of the entire scene.
Let me be honest: most video RAG pipelines are outdated. You’re probably embedding frames individually with CLIP, storing image and text vectors separately, and praying that cosine similarity is enough to find the moment you’re looking for. While that approach was the best we could do in 2024, things have changed with the arrival of production-ready multimodal AI embedding models such as voyage-multimodal-3.
In this blog, I will define the blueprint for building a modern RAG pipeline for video, simultaneously ingesting visual frames and corresponding text transcripts to produce dense vectors of an entire scene. Together, we will work through video ingestion, semantic scene division (frames + transcript), embedding, storage, and retrieval using a vision LLM such as GPT-4o-mini.
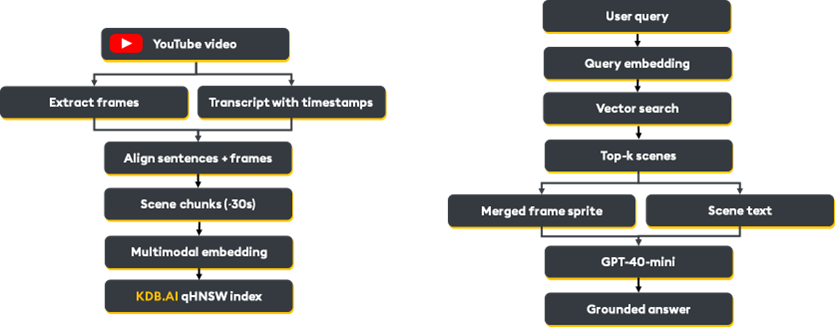
Note: Video search is still an active research area. I aim to provide a comprehensive technical guide on where we are today. You can follow along from my Colab notebook.
Understanding multimodal AI embeddings
You likely know about embeddings, which map sentences and images to numerical vectors, which are then grouped by similarity into a high-dimensional space.
A multimodal embedding model does something more sophisticated: It takes multiple types of input at once, perhaps a chunk of text and several related images, then maps them to a single vector representing their combined meaning. It learns that the words “This formula shows…” belong with the frame displaying E=mc² and enables similarity search to find moments where the visual and auditory information align with the query. Voyage AI’s model is a prime example of this new capability.
Note: There are only a few truly multimodal embedding models, and the best are closed-source as of this blog’s writing.
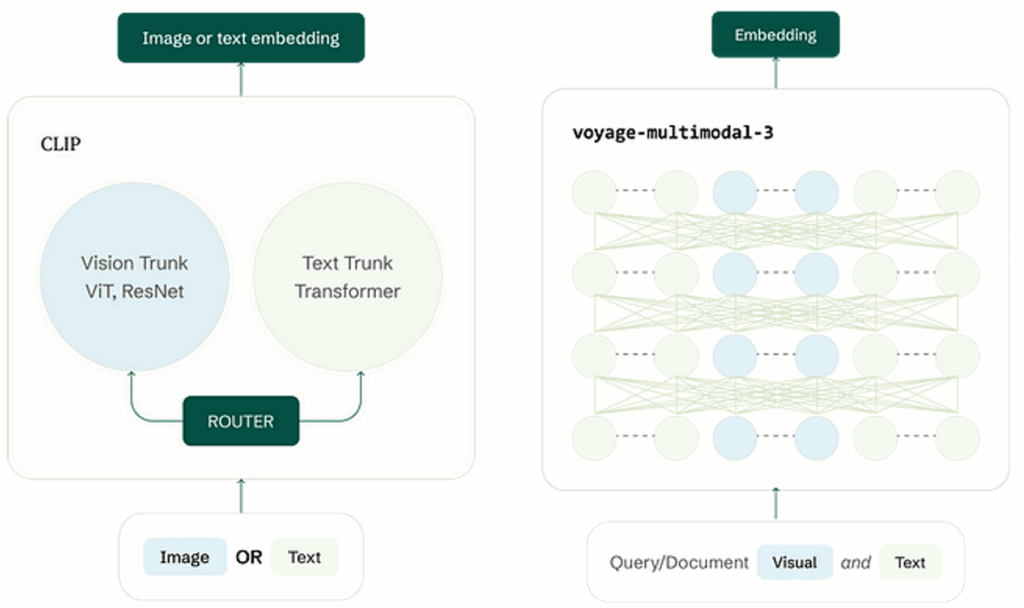
Image source: https://blog.voyageai.com/2024/11/12/voyage-multimodal-3/
Optimizing embeddings with KDB.AI
Built by the kdb+ team (known for low-latency financial systems), KDB.AI is a multimodal vector database enabling scalable, real-time AI applications with advanced capabilities. It integrates temporal and semantic relevance into enterprise-scale workflows, helping developers optimize costs while working seamlessly with popular LLMs.
In our example, we use qHNSW, a groundbreaking advancement designed to address the limitations of traditional HNSW (Hierarchical Navigable Small World) indices, which rely heavily on in-memory storage. While not as accurate as exhaustive searches like Flat, it balances accuracy and efficiency, making it ideal for large-scale datasets when high-speed, approximate nearest neighbor (ANN) searches are necessary.
| Index | Flat | qFlat | HNSW | qHNSW | IVF | IVFPQ |
| Retrieval speed | Low | Low | Very high | Very high | Moderate | High |
| Indexing speed | Very high | Very high | Low | Low | Moderate | Moderate |
| Accuracy | Highest | Highest | Balanced | Balanced | Balanced | Balanced |
| Memory used | High | Very low | Very high | Low | High | Moderate |
| Storage | Memory | Disk | Memory | Disk | Memory | Memory |
Key Features
- On-disk storage: Unlike its predecessors, qHNSW stores the index on disk with memory-mapped access, drastically reducing memory requirements
- Incremental disk access: Queries read data incrementally from disk, optimizing memory utilization
- Cost efficiency: Disk-based storage is generally less expensive and energy-intensive than memory-based storage
When to use
- Large-scale datasets: The hierarchical graph structure allows for efficient and low-memory indexing and querying
- Approximate searches with high recall: qHNSW provides a good balance between approximation and accuracy, making it ideal for scenarios where perfect accuracy is not mandatory but speed is critical
- Memory-constrained environments: qHNSW is an excellent fit if you need fast approximate search on a large dataset, but memory is a bottleneck (think IoT and edge devices)
To find out more, please visit KDB.AI
Example
Step 1: Data preparation
Let’s now put this together in a technical example. Remember, you can follow along from my Colab notebook.
First, we will extract the transcript and a video frame every 5 seconds.
# ... [For download video code - see Colab] ...
with VideoFileClip(VIDEO_PATH) as clip:
# Extract frames at 0.2 FPS. This rate is a tunable hyperparameter.
# Lower FPS = fewer frames, less cost, potentially less visual detail.
# Higher FPS = more detail, more cost, diminishing returns after a point.
clip.write_images_sequence(os.path.join(FRAMES_DIR, "frame%04d.png"), fps=0.2, logger=None)
clip.audio.write_audiofile(AUDIO_PATH, codec="libmp3lame", bitrate="192k", logger=None)
# Transcribe using Whisper
openai_client = OpenAI()
with open(AUDIO_PATH, "rb") as audio_file:
# Requesting segments gives us text blocks with rough start/end times
transcription = openai_client.audio.transcriptions.create(
model="whisper-1", file=audio_file, response_format="verbose_json",
timestamp_granularities=["segment"]
)What just happened:
- We obtained sequentially numbered frames and a structured transcription object containing text segments with timestamps.
- We set the value fps=0.2 to balance detail and cost.
- We set timestamp_granularities to ‘segment’ to get timestamps and punctuation with the OpenAI Whisper API.
- We grouped frames and aligned transcript sentences based on timestamps using NLTK, creating six frames and approximately 30 seconds of transcript per ~30s video chunk.
# --- 1.d Create Video Chunks (NLTK, sentence‑aware, true punctuation) ------
import os, re, math, pandas as pd
from IPython.display import display
import nltk
##############################################################################
# Configuration
##############################################################################
FRAMES_DIR = frames_dir # from step 1.b
FRAME_FPS = 0.2 # write_images_sequence fps
TARGET_CHUNK_SEC = 30 # desired chunk length
SLACK_FACTOR = 1.20 # allow up to 20 % over‑run before forcing cut
##############################################################################
print("\n--- Building sentence‑aligned ~30 s chunks ---")
# ---------------------------------------------------------------------------
# 0. Make sure the Punkt model is present
# ---------------------------------------------------------------------------
try:
nltk.data.find("tokenizers/punkt")
except LookupError:
nltk.download("punkt", quiet=True)
from nltk.tokenize import sent_tokenize
# ---------------------------------------------------------------------------
# 1. Frame paths and helper
# ---------------------------------------------------------------------------
frame_paths = sorted(
[os.path.join(FRAMES_DIR, f) for f in os.listdir(FRAMES_DIR) if f.endswith(".png")],
key=lambda p: int(re.search(r"frame(\d+)\.png", os.path.basename(p)).group(1))
)
def idx_from_time(t): return int(round(t * FRAME_FPS))
# ---------------------------------------------------------------------------
# 2. Build per‑sentence list with *estimated* timestamps
# ---------------------------------------------------------------------------
sentences = [] # list of dict(start, end, sentence)
for seg in transcription_result.segments:
seg_start, seg_end, seg_text = seg.start, seg.end, seg.text
seg_sents = sent_tokenize(seg_text)
# Distribute the segment’s duration across its sentences by char length
seg_dur = seg_end - seg_start
char_total = sum(len(s) for s in seg_sents)
running_t = seg_start
for s in seg_sents:
char_frac = len(s) / char_total
sent_end = running_t + char_frac * seg_dur
sentences.append({"start": running_t, "end": sent_end, "sentence": s})
running_t = sent_end
print(f" • {len(sentences):,} sentences total")
# ---------------------------------------------------------------------------
# 3. Pack sentences into chunks (guarantee ending punctuation)
# ---------------------------------------------------------------------------
chunks, cur_sents = [], []
cur_start, cur_end = None, None
def ends_with_stop(txt): return txt[-1] in ".?!"
for sent in sentences:
if not cur_sents: # start new chunk
cur_sents = [sent]
cur_start, cur_end = sent["start"], sent["end"]
continue
prospective_end = sent["end"]
prospective_span = prospective_end - cur_start
# Decide if we should append sentence to current chunk
if prospective_span <= TARGET_CHUNK_SEC * SLACK_FACTOR or not ends_with_stop(cur_sents[-1]["sentence"]):
cur_sents.append(sent)
cur_end = prospective_end
else:
chunks.append({"start": cur_start, "end": cur_end, "sentences": cur_sents})
cur_sents = [sent]
cur_start, cur_end = sent["start"], sent["end"]
if cur_sents:
chunks.append({"start": cur_start, "end": cur_end, "sentences": cur_sents})
print(f" • {len(chunks)} chunks produced "
f"(avg {sum(c['end']-c['start'] for c in chunks)/len(chunks):.1f}s)")
# ---------------------------------------------------------------------------
# 4. Attach frames to each chunk
# ---------------------------------------------------------------------------
records = []
total_imgs = 0
for idx, ch in enumerate(chunks):
start_t, end_t = ch["start"], ch["end"]
first_idx = idx_from_time(start_t)
last_idx = max(idx_from_time(end_t) - 1, first_idx) # inclusive
imgs = frame_paths[first_idx : last_idx + 1]
total_imgs += len(imgs)
chunk_text = " ".join(s["sentence"] for s in ch["sentences"]).strip()
records.append(
{
"section": idx,
"start_time": round(start_t, 2),
"end_time": round(end_t, 2),
"images": imgs,
"text": chunk_text,
}
)
print(f" • {total_imgs} total images linked")
# ---------------------------------------------------------------------------
# 5. DataFrame
# ---------------------------------------------------------------------------
df_aligned = pd.DataFrame(records)
pd.set_option("display.max_colwidth", None)
display(df_aligned.head(10))
# ---------------------------------------------------------------------------Output:
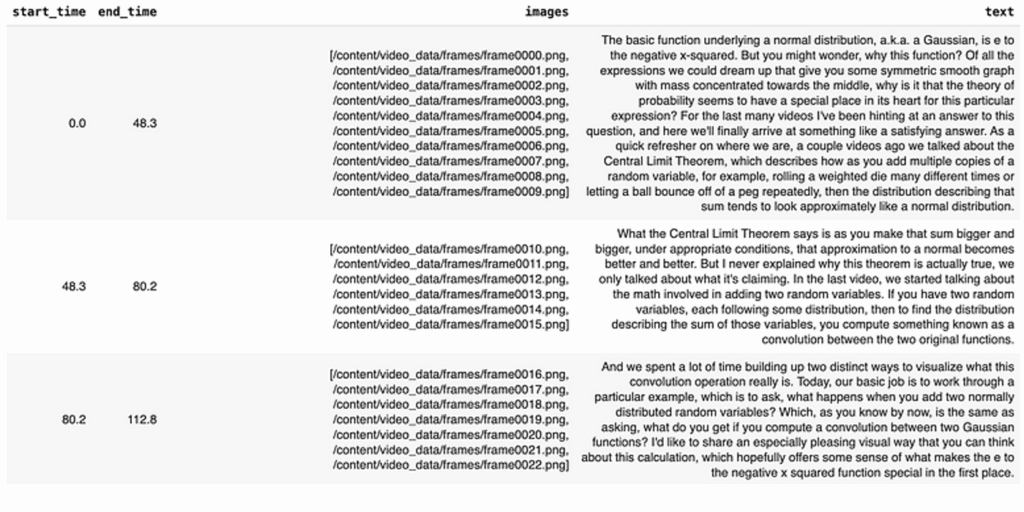
This chunking method is more sophisticated than simple fixed-size splitting. It uses Whisper’s segment timestamps and NLTK’s sentence tokenizer to create chunks that are roughly TARGET_CHUNK_SEC long. To improve semantic coherence, it also tries to end on proper sentence boundaries. It then maps each calculated text chunk’s time range (start_t, end_t) back to the corresponding frame files based on the FRAME_FPS, ensuring that each row in scene_df represents a ~30-second multimodal scene.
Step 2: Multimodal embedding
Next, we will pass each scene (text string + list of PIL Images) into Voyage AI.
# Generating the Multimodal Embedding Vector
import voyageai
from PIL import Image
voyage = voyageai.Client() # Reads API key from env
model_name = "voyage-multimodal-3"
def embed_scene(scene_data):
text = scene_data["text"]
# Load images associated with this scene
pil_images = [Image.open(p) for p in scene_data["images"] if os.path.exists(p)]
if not pil_images: return None # Skip if no valid images
# Critical: Input must be [text_string, Image_obj1, Image_obj2, ...]
input_payload = [text] + pil_images
try:
response = voyage.multimodal_embed(
inputs=[input_payload], # Embed one scene at a time
model=model_name,
input_type="document", # Optimize for retrieval
truncation=True # Auto-handle long inputs
)
return response.embeddings[0] # Get the single vector
except Exception as e:
print(f"Error embedding scene {scene_data.get('id', 'N/A')}: {e}")
return None
# Apply the embedding function to each row
scene_df['embedding'] = scene_df.apply(embed_scene, axis=1)
# Drop rows where embedding failed
scene_df.dropna(subset=['embedding'], inplace=True)How we structure the input_payload is important; Voyage requires the text first, then the images.
- input_type=”document” is crucial because it notifies Voyage that you’re embedding content for storage/search, not making a query
- Each scene is embedded individually for clarity, but Voyage supports batching (inputs=[scene1_payload, scene2_payload, …]) for higher throughput in production
Step 3: Store in KDB.AI
Now, we will define the table schema and implement our index.
# SNIPPET 4: KDB.AI Schema and Table Creation
import kdbai_client as kdbai
import json
import numpy as np
session = kdbai.Session(endpoint=os.getenv("KDBAI_ENDPOINT"), api_key=os.getenv("KDBAI_API_KEY"))
db = session.database("default")
TABLE_NAME = "video_multimodal_scenes"
embedding_dim = len(scene_df['embedding'].iloc[0])
schema = [
{"name": "id", "type": "str"},
{"name": "text_bytes", "type": "bytes"}, # Store text efficiently as bytes
{"name": "image_paths", "type": "str"}, # JSON string list of frame paths
{"name": "embeddings", "type": "float32s", "pytype": f"{embedding_dim}f"}, # Vector
]
# Use qHNSW for large datasets: Approximate search, disk-based storage
indexes = [{
"type": "qHNSW", # Changed from qFlat for scalability
"name": "idx_emb",
"column": "embeddings",
"params": {"dims": embedding_dim, "metric": "CS"}
}]
table = db.create_table(TABLE_NAME, schema=schema, indexes=indexes)
# Prepare and insert data
table.insert(insert_payload) # insert_payload is the formattedWhat just happened:
- Text is stored as (UTF-8 encoded) bytes
- Image paths are stored as a JSON string
- The embeddings column uses float32s
- The index is set as qHNSW
Step 4: Run a query
Finally, we will embed the query, find similar scenes, prepare context (with merged images), and query the VLM.
Before we do, I’d like to flag that when initially developing this, I regularly hit API limits due to the number of generated tokens. To overcome this issue, I created a sprite, a long merged image comprising many sub-images.
from PIL import Image
def merge_images(paths):
images = [Image.open(p) for p in paths]
widths, heights = zip(*(img.size for img in images))
total_width = sum(widths)
max_height = max(heights)
merged = Image.new('RGB', (total_width, max_height))
x_offset = 0
for img in images:
merged.paste(img, (x_offset, 0))
x_offset += img.size[0]
return merged
def multimodal_rag(query: str, k: int = 3) -> str:
global table
q_emb = voyage.multimodal_embed([[query]], model="voyage-multimodal-3", input_type="query", truncation=True).embeddings[0]
retrieved = table.search(vectors={"idx_emb": [q_emb]}, n=k)[0]
context = [{"type": "text", "text": f"Answer the query based only on the following video segments.\n\nQuestion: {query}\n"}]
preview = []
for i, row in retrieved.iterrows():
tid = row.get('id', f'Retrieved_{i}')
txt = row['text_bytes'].decode('utf-8')
context += [{"type": "text", "text": f"\n--- Segment {tid} Text ---"}, {"type": "text", "text": txt}]
preview.append({"type": "input_text", "text": f"\n--- Segment {tid} Text ---\n{txt}"})
img_paths = json.loads(row.get('image_paths', '[]'))
if img_paths:
merged_img = merge_images(img_paths)
merged_img_path = "/tmp/merged_segment_image.jpg"
merged_img.save(merged_img_path, format="JPEG")
base64_img = encode_base64(merged_img_path)
context += [{"type": "image_url", "image_url": {"url": base64_img}}]
preview.append({"type": "input_image", "image_url": base64_img})
display(merged_img)
context.append({"type": "text", "text": "\n--- End of Retrieved Context ---"})
display_rag_preview(preview)
res = openai.chat.completions.create(model="gpt-4o-mini", messages=[{"role": "user", "content": context}], max_tokens=500)
out = res.choices[0].message.content
display(Markdown(out))
return outLet’s test this with a new query.
question1 = "What is the central limit theorem?"
print(f"\nExecuting RAG for query: '{question1}'")
response1 = multimodal_rag(query=question1, k=4)Result:

What just happened:
- Voyage optimizes query vectors differently from document vectors; we therefore use input_type=”query” when embedding the user’s question
- AI table.search uses the idx_emb (HNSW index) for fast retrieval of the top k most similar scene vectors
- To dramatically cut the number of image inputs, we use merge_images_to_sprite, thereby reducing k * 6 = 24 separate images, down to k=4 merged sprites
- The llm_context carefully interleaves text ({“type”: “text”, …}) and the corresponding merged image sprite ({“type”: “image_url”, …}) which models like GPT-4o require
The new standard?
A scene-based multimodal RAG approach represents a fundamental improvement, respecting video’s inherent nature and the fusion of sight and sound over time.
It ensures:
- Context preservation: Embeddings capture the link between frames and the transcript.
- Relevant retrieval: Search finds semantically relevant scenes rather than isolated frames or text snippets.
- Grounded generation: VLMs can answer questions using both visual and textual evidence.
- Cost management: Image merging makes VLM calls affordable.
However, there are opportunities for improvement; finding the optimal fps and FRAMES_PER_CHUNK for different video types, for example, is still an art. But even with these considerations, the advancements in multimodal AI help transform video search from a cumbersome task into a seamless experience. By integrating visual and textual data, we can now achieve a more accurate and contextually relevant search, making it easier to find the exact moments we seek. This converts your video archive from a passive storage problem into an active, searchable knowledge base.
If you enjoyed this blog, please check out my others on kx.com and connect with me on Slack. You can also find all of the code used in this blog via my Colab notebook: https://github.com/KxSystems/kdbai-samples/blob/main/video_RAG/video_RAG.ipynb


