Ferenc Bodon is an expert kdb+ programmer, as well as an experienced software developer in several other programming languages, and a software architect with an academic background in data mining and statistics.
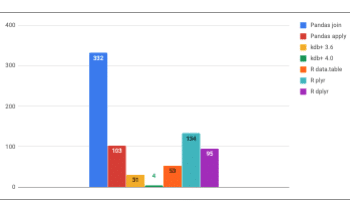
In a recent posting on KDnuggets, Ferenc compared kdb+ with Pandas, Ray, Dask, R and BigQuery in terms of their elegance, speed, and simplicity. In the article, he extended beyond a simple use case to examine aggregation based on multiple columns. Furthermore, he investigated how to tune the performance and use parallelism across multicore processors or clusters of machines.
Ferenc has rerun his tests on version 4.0 of kdb+ and updated his analysis – please click on this link to KDnuggets to read his revised blog