

Crafters normally harness two things in their art: a skill in the domain and the right tools to express it. Both are necessary: Give a painter some colours and their favourite brushes and expect a nice piece of art in return, give them a toothbrush instead and expect… well… or maybe you like modern art?
Data scientists are no different. Their raw material is data and their tool of choice is normally Python. While the data is essential, Python may be optional as, yes there are other tools and yes, they can do the job too. But you need your answers quickly and by using Python you know how to get them, right now.
So why even consider the overhead of using a different language like say, q, the integrated vector programming language in kdb, the world’s fastest time-series database and analytics engine? It’s true, what you can do with the q programming language on kdb as its data source you can probably do with Python on any other data source. But with q there is one big difference – speed. As it is integrated within kdb, it works directly on the data stored there, eliminating the need for any extraction process or latency-inducing transferring of data. As a result, its speed of processing is faster, significantly faster. Just check out these benchmark results to see.
So, what if that speed of kdb could be tapped from within Python too? Well, now it can, and very easily.
How easy? Try this.
![]()
Just add PyKX in your Python Notebook and it enables users to harness the power of kdb from the familiarity of Python and instantly gives the best of both worlds. Actually the best of three worlds, as the beauty of PyKX is that you can still programme in q along with your Python code – that can be very important for areas needing ultra-low latency.
PyKX supports three primary use cases:
- It allows users to store, query, manipulate and use q objects within a Python process.
- It allows users to query external q processes via an IPC interface.
- It allows users to embed Python functionality within a native q session
In addition, it provides a module interface that can be used to easily load q scripts, namespaces, and contexts. Once loaded their functions and other members can be accessed as if they were Python modules. Add to that support for standard ANSI SQL querying and it make data science a lot more powerful.
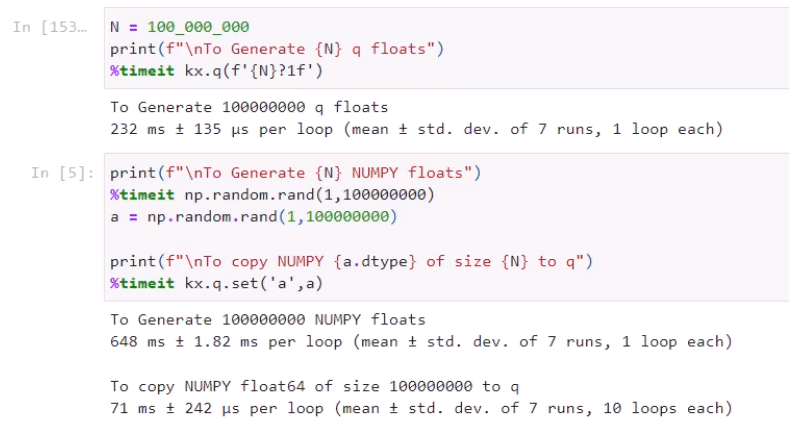
Reuben Taylor, Senior Software Engineer, recently gave a demo that shows it in action and conveys that speed of execution KX is known for. Within the demo, to get an appreciation of its speed, he compared the time to generate 100 million floats in q versus NumPy. The difference was stark – in q it took 232 milliseconds, in NumPy it took 648.
Elsewhere in the presentation he showed how PyKX also supports ANSI SQL, making it even easier for a wide range of users to access the benefits of kdb without necessarily having to learn q as its querying language.
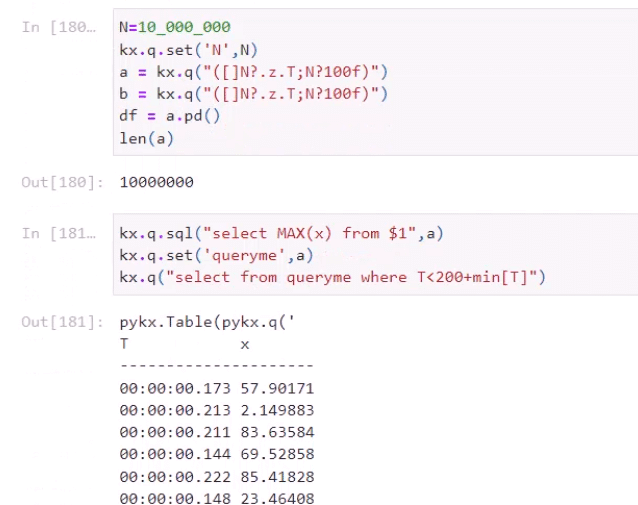
Later he compared the speed of running an SQL query in PyKX (2.31 milliseconds) versus Pandas (40 milliseconds)

If you interested in learning more, please check out our Academy course “Introduction to PyKX” on the KX Learning Hub. To get an PyKX overview visit our PyKX product page. For more PyKX developer resources, please visit our PyKX developer center page or read our documentation on code.kx.com.
Better still, try it out! PyKX is now available on PyPI and installation is as easy as “pip install pykx” – just follow this helpful guide for getting started.