
The retrieval-augmented generation (RAG) revolution has been moving forward for some time. Still, it’s not without issues, especially when handling non-text elements like images and tables. One challenge is the accuracy reduction whenever RAG retrieves specific values from tables. It’s even worse when the documents have multiple tables on related topics, such as an earnings report.
In this blog, I will discuss how I have tried to improve table retrieval within my RAG pipelines.
Understand the problem
Challenges
- Retrieval inconsistency: Vector search algorithms often struggle to pinpoint the correct tables, especially in documents with multiple, similar-looking tables.
- Generation inaccuracy: Large language models (LLMs) frequently misinterpret or misidentify values within tables, particularly in complex tables with nested columns.
Solution
Let’s approach these challenges with four key concepts:
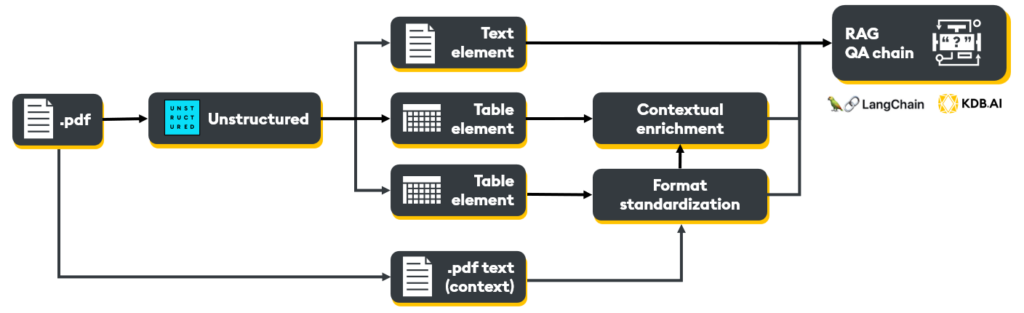
- Precise extraction: Cleanly extract all tables from the document.
- Contextual enrichment: Leverage an LLM to generate a robust, contextual description of each table by analyzing the extracted table and surrounding document content.
- Format standardization: Employ an LLM to convert tables into a uniform markdown format, enhancing embedding efficiency and LLM comprehension.
- Unified embedding: Create a ‘table chunk’ by combining the contextual description with the markdown-formatted table, optimizing it for vector database storage and retrieval.
Implement the solution
Objective: Build a RAG pipeline for Meta’s earnings report data to retrieve and answer questions from the document’s text and multiple tables.
See the full notebook in Google Colab, or fork the code on GitHub.
Step 1: Precise extraction
We will use Unstructured.io to extract the text and tables from the document. Let’s start by installing and importing all dependencies.
!apt-get -qq install poppler-utils tesseract-ocr
%pip install -q --user --upgrade pillow
%pip install -q --upgrade unstructured["all-docs"]
%pip install kdbai_client
%pip install langchain-openai
%pip install langchain
import os
!git clone -b KDBAI_v1.4 https://github.com/KxSystems/langchain.git
os.chdir('langchain/libs/community')
!pip install .
%pip install pymupdf
%pip install --upgrade nltk
import os
from getpass import getpass
import openai
from openai import OpenAI
from unstructured.partition.pdf import partition_pdf
from unstructured.partition.auto import partition
from langchain_openai import OpenAIEmbeddings
import kdbai_client as kdbai
from langchain_community.vectorstores import KDBAI
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
import fitz
nltk.download('punkt')Next, we will set our OpenAI API key.
# Set OpenAI API
if "OPENAI_API_KEY" in os.environ:
KDBAI_API_KEY = os.environ["OPENAI_API_KEY"]
else:
# Prompt the user to enter the API key
OPENAI_API_KEY = getpass("OPENAI API KEY: ")
# Save the API key as an environment variable for the current session
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEYFinally, we will complete our setup by downloading Meta’s second quarter 2024 results pdf.
!wget 'https://s21.q4cdn.com/399680738/files/doc_news/Meta-Reports-Second-Quarter-2024-Results-2024.pdf' -O './doc1.pdf'We will use Unstructured’s ‘partition_pdf’ and implement a ‘hi_res’ partitioning strategy to extract text and table elements from the earnings report.
We can set a few parameters during partitioning to extract tables accurately.
- Strategy = “hi_res”: Identifies the document layout, recommended for use-cases sensitive to correct element classification
- Chunking_strategy = “by_title”: Preserves section boundaries by starting a new chunk when a ‘Title’ element is encountered, even if the current chunk has space
elements = partition_pdf('./doc1.pdf',
strategy="hi_res",
chunking_strategy="by_title",
)
Let’s see the extracted elements.
from collections import Counter
display(Counter(type(element) for element in elements))
>>> Counter({unstructured.documents.elements.CompositeElement: 17,
unstructured.documents.elements.Table: 10})
Step 2 & 3: Table contextual enrichment and format standardization
Let’s explore a table element and see if we can understand why there might be issues in the RAG pipeline
print(elements[-2])
>>>Foreign exchange effect on 2024 revenue using 2023 rates Revenue excluding foreign exchange effect GAAP revenue year-over-year change % Revenue excluding foreign exchange effect year-over-year change % GAAP advertising revenue Foreign exchange effect on 2024 advertising revenue using 2023 rates Advertising revenue excluding foreign exchange effect 2024 $ 39,071 371 $ 39,442 22 % 23 % $ 38,329 367 $ 38,696 22 % 2023 $ 31,999 $ 31,498 2024 $ 75,527 265 $ 75,792 25 % 25 % $ 73,965 261 $ 74,226 24 % 2023 GAAP advertising revenue year-over-year change % Advertising revenue excluding foreign exchange effect year-over-year change % 23 % 25 % Net cash provided by operating activities Purchases of property and equipment, net Principal payments on finance leases $ 19,370 (8,173) (299) $ 10,898 $ 17,309 (6,134) (220) $ 10,955 $ 38,616 (14,573) (614) $ 23,429
The table is a long string combining natural language and numbers. If ingested into the RAG pipeline, it’s easy to see how difficult it would be to decipher. We, therefore, need to enrich each table with context and format into markdown. To do this, we will first extract the entire text from the pdf document for context.
def extract_text_from_pdf(pdf_path):
text = ""
with fitz.open(pdf_path) as doc:
for page in doc:
text += page.get_text()
return text
pdf_path = './doc1.pdf'
document_content = extract_text_from_pdf(pdf_path)
Next, we will create a function to take the entire context of the document, along with the extracted text, and output as a new comprehensive description and table in markdown.
# Initialize the OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def get_table_description(table_content, document_context):
prompt = f"""
Given the following table and its context from the original document,
provide a detailed description of the table. Then, include the table in markdown format.
Original Document Context:
{document_context}
Table Content:
{table_content}
Please provide:
1. A comprehensive description of the table.
2. The table in markdown format.
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant that describes tables and formats them in markdown."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.contentLet’s now pull it all together by applying the above function to all table elements.
# Process each table in the directory
for element in elements:
if element.to_dict()['type'] == 'Table':
table_content = element.to_dict()['text']
# Get description and markdown table from GPT-4o
result = get_table_description(table_content, document_content)
# Replace each Table elements text with the new description
element.text = result
print("Processing complete.")Example of an enriched table chunk/element in markdown format for easy reading.
This markdown table provides a concise presentation of the financial data, making it easy to read and comprehend in a digital format.
### Detailed Description of the Table
The table presents segment information from Meta Platforms, Inc. for both revenue and income (loss) from operations. The data is organized into two main sections:
1. **Revenue**: This section is subdivided into two categories: "Advertising" and "Other revenue". The total revenue generated from these subcategories is then summed up for two segments: "Family of Apps" and "Reality Labs". The table provides the revenue figures for three months and six months ended June 30, for the years 2024 and 2023.
2. **Income (loss) from operations**: This section shows the income or loss from operations for the "Family of Apps" and "Reality Labs" segments, again for the same time periods.
The table allows for a comparison between the two segments of Meta's business over time, illustrating the performance of each segment in terms of revenue and operational income or loss.
### The Table in Markdown Format
```markdown
### Segment Information (In millions, Unaudited)
| | Three Months Ended June 30, 2024 | Three Months Ended June 30, 2023 | Six Months Ended June 30, 2024 | Six Months Ended June 30, 2023 |
|----------------------------|----------------------------------|----------------------------------|------------------------------- |-------------------------------|
| **Revenue:** | | | | |
| Advertising | $38,329 | $31,498 | $73,965 | $59,599 |
| Other revenue | $389 | $225 | $769 | $430 |
| **Family of Apps** | $38,718 | $31,723 | $74,734 | $60,029 |
| Reality Labs | $353 | $276 | $793 | $616 |
| **Total revenue** | $39,071 | $31,999 | $75,527 | $60,645 |
| | | | | |
| **Income (loss) from operations:** | | | | |
| Family of Apps | $19,335 | $13,131 | $36,999 | $24,351 |
| Reality Labs | $(4,488) | $(3,739) | $(8,334) | $(7,732) |
| **Total income from operations** | $14,847 | $9,392 | $28,665 | $16,619 |
```
As you can see, this provides much more context than the element’s original text, which should significantly improve the performance of our RAG pipeline.
Step 4: Unified embeddings
Now that all elements have the context for high-quality retrieval and generation, let’s embed and store them in KDB.AI. To begin, we will create embeddings (numerical representations of the semantic meaning ) for each element.
from unstructured.embed.openai import OpenAIEmbeddingConfig, OpenAIEmbeddingEncoder
embedding_encoder = OpenAIEmbeddingEncoder(
config=OpenAIEmbeddingConfig(
api_key=os.getenv("OPENAI_API_KEY"),
model_name="text-embedding-3-small",
)
)
elements = embedding_encoder.embed_documents(
elements=elements
)Next, we’ll create a Pandas data frame to store our elements with columns based on each element’s attributes. For example, unstructured.io creates an ID, text, metadata, and an embedding for each element.
We can then store the data in a data frame to be easily ingested into KDB.AI.
import pandas as pd
data = []
for c in elements:
row = {}
row['id'] = c.id
row['text'] = c.text
row['metadata'] = c.metadata.to_dict()
row['embedding'] = c.embeddings
data.append(row)
df = pd.DataFrame(data)You can get a KDB.AI API key and endpoint for free here: https://trykdb.kx.com/kdbai/signup/
KDBAI_ENDPOINT = (
os.environ["KDBAI_ENDPOINT"]
if "KDBAI_ENDPOINT" in os.environ
else input("KDB.AI endpoint: ")
)
KDBAI_API_KEY = (
os.environ["KDBAI_API_KEY"]
if "KDBAI_API_KEY" in os.environ
else getpass("KDB.AI API key: ")
)
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)Once connected, we can define the schema for our table and a column for each attribute created earlier (id, text, metadata embedding).
schema = [
{'name': 'id', 'type': 'str'},
{'name': 'text', 'type': 'bytes'},
{'name': 'metadata', 'type': 'general'},
{'name': 'embedding', 'type': 'float32s'}
]Next, we’ll define the index and several parameters:
- Name: The user-defined name of this index
- Column: The column in the schema to which this index will be applied
- Type: The type of index, here simply using a flat index
- Params: The dimensions and search metrics
indexes = [
{'name': 'flat_index',
'column': 'embedding',
'type': 'flat',
'params': {'dims': 1536, 'metric': 'L2'}}
]
Table creation based on the above schema.
# Connect to the default database in KDB.AI
database = session.database('default')
KDBAI_TABLE_NAME = "Table_RAG"
# First ensure the table does not already exist
if KDBAI_TABLE_NAME in database.tables:
database.table(KDBAI_TABLE_NAME).drop()
#Create the table using the table name, schema, and indexes defined above
table = db.create_table(table=KDBAI_TABLE_NAME, schema=schema, indexes=indexes)
Now, we can insert the data frame into our KDB.AI table.
# Insert Elements into the KDB.AI Table
table.insert(df)
From here, we will use LangChain and KDB.AI to perform RAG!
# Define OpenAI embedding model for LangChain to embed the query
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# use KDBAI as vector store
vecdb_kdbai = KDBAI(table, embeddings)First, let’s define a RAG chain using KDB.AI as the retriever and gpt-4o as the LLM for generation.
# Define a Question/Answer LangChain chain
qabot = RetrievalQA.from_chain_type(
chain_type="stuff",
llm=ChatOpenAI(model="gpt-4o"),
retriever=vecdb_kdbai.as_retriever(search_kwargs=dict(k=5, index='flat_index')),
return_source_documents=True,
)Next, we will define a helper function to perform RAG.
# Helper function to perform RAG
def RAG(query):
print(query)
print("-----")
return qabot.invoke(dict(query=query))["result"]Review the results
Finally, we will test the output using a series of RAG prompts.
Example 1:
# Query the RAG chain!
RAG("what is the 2024 GAAP advertising Revenue in the three months
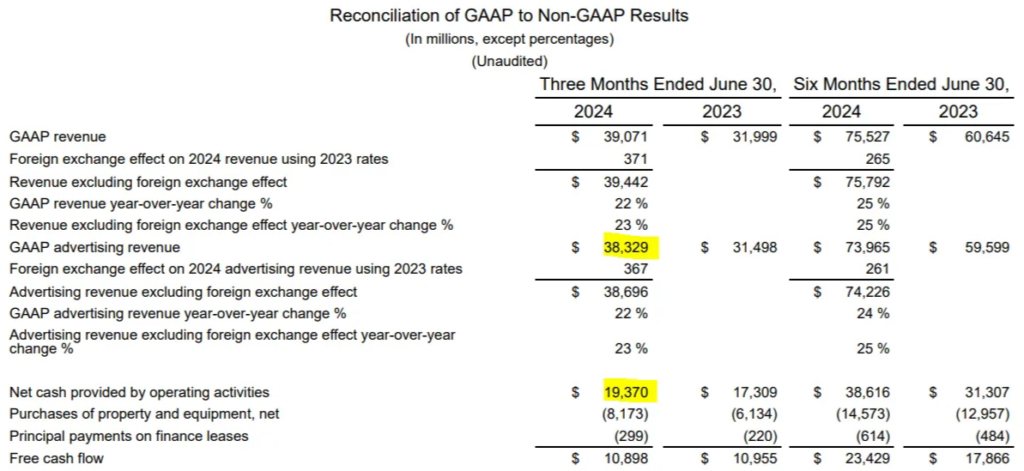
ended June 30th? What about net cash by operating activies")Result: For the three months ended June 30, 2024:
- The GAAP advertising revenue was $38,329 million
- The net cash provided by operating activities was $19,370 million
Example 2:
# Query the RAG chain!
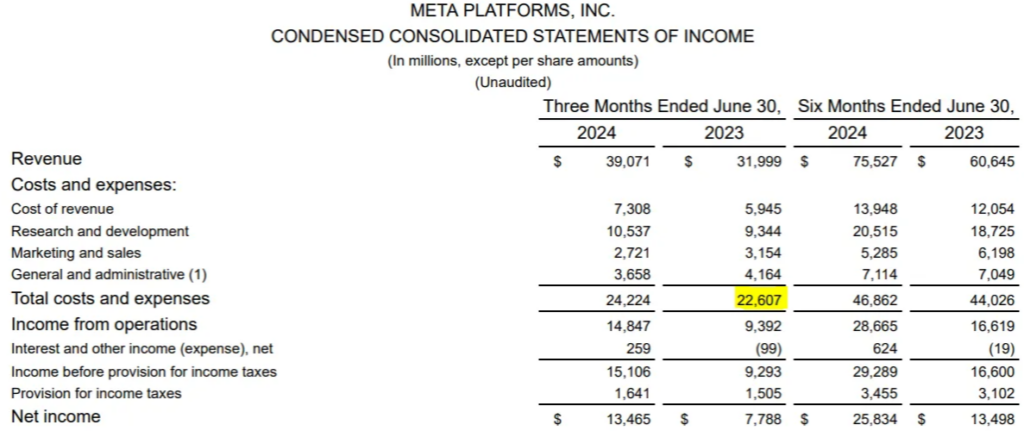
RAG("what is the three month costs and expenses for 2023?")Result: The three-month costs and expenses for Meta Platforms, Inc. in the second quarter of 2023 were $22.607 billion.
Example 3:
# Query the RAG chain!
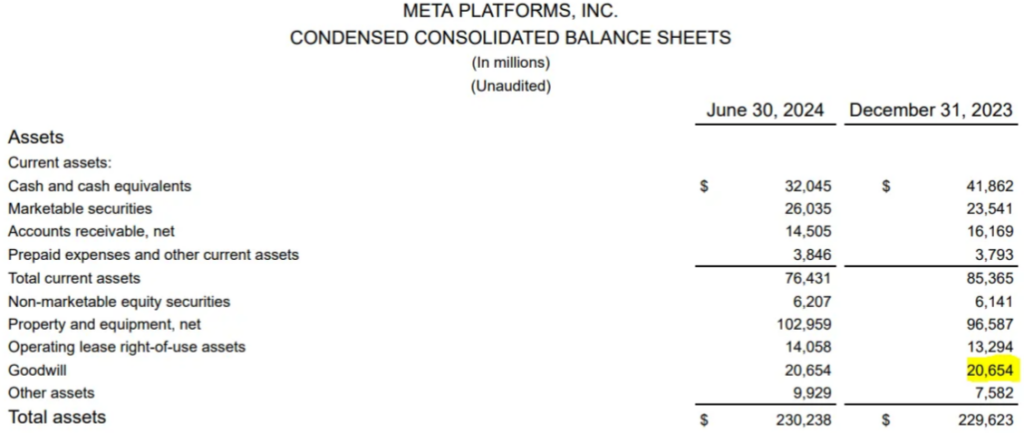
RAG("At the end of 2023, what was the value of Meta's Goodwill assets?")Result: At the end of 2023, the value of Meta’s Goodwill assets was $20,654 million.
Example 4:
# Query the RAG chain!
RAG("What is the research and development costs for six months ended in June 2024")Result: The research and development costs for the six months ended in June 2024 were $20,515 million.
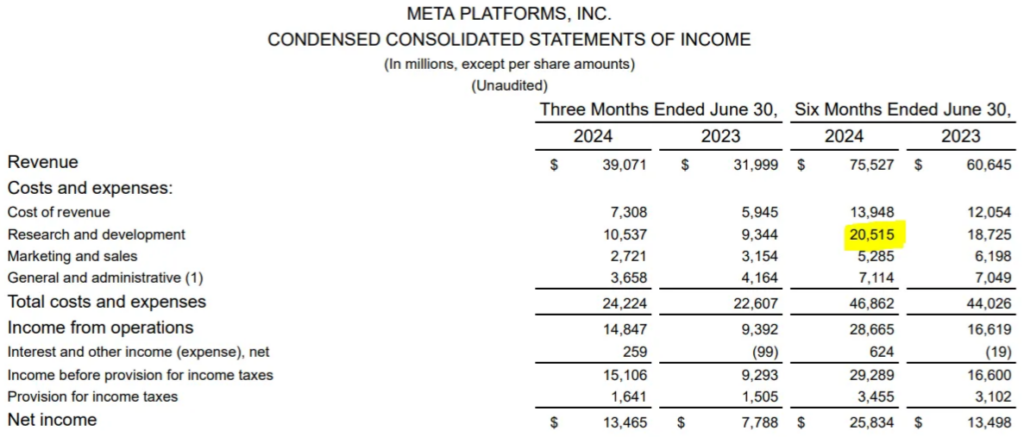
Note: This is an example where using non-contextualized table chunks gets it wrong, meaning the more complex the table, the more helpful it will be to add additional context and formatting.
Example 5:
# Query the RAG chain!
RAG("Given a sentiment score between 1 and 10 for the outlook? Explain your reasoning")
I would give the sentiment score for Meta Platforms, Inc.'s outlook
an **8 out of 10**. Here's the reasoning behind this score:
### Positive Indicators:
1. **Significant Increase in Earnings Per Share (EPS)**:
- **Basic EPS** has risen from $3.03 in Q2 2023 to $5.31 in Q2 2024, and from $5.24 in H1 2023 to $10.17 in H1 2024.
- **Diluted EPS** has also shown substantial growth, from $2.98 in Q2 2023 to $5.16 in Q2 2024, and from $5.18 in H1 2023 to $9.86 in H1 2024.
2. **Revenue Growth**:
- Revenue increased by 22% from $31.999 billion in Q2 2023 to $39.071 billion in Q2 2024.
3. **Improved Income from Operations**:
- Income from operations rose by 58%, from $9.392 billion in Q2 2023 to $14.847 billion in Q2 2024.
- Operating margin improved from 29% in Q2 2023 to 38% in Q2 2024.
4. **Net Income Growth**:
- Net income for Q2 2024 was $13.465 billion, marking a 73% increase from $7.788 billion in Q2 2023.
5. **Effective Tax Rate**:
- The effective tax rate decreased from 16% in Q2 2023 to 11% in Q2 2024, benefiting overall profitability.
### Negative or Neutral Indicators:
1. **Increase in Costs and Expenses**:
- Total costs and expenses increased by 7%, from $22.607 billion in Q2 2023 to $24.224 billion in Q2 2024.
2. **Decrease in Retained Earnings**:
- Retained earnings slightly decreased from $82,070 million at the end of 2023 to $81,188 million by June 30, 2024.
### Conclusion:
The significant improvements in EPS, revenue, income from operations, and net income indicate strong financial performance and a positive outlook for Meta Platforms, Inc. The increase in costs and expenses and a slight decrease in retained earnings are areas to watch, but they don't outweigh the overall positive momentum. Hence, the sentiment score of 8 reflects a strong outlook with some room for careful monitoring of expenses.
Notice that the LLM can use numbers from the embedded tables to create reasoning for the sentiment scores generated.
Considerations: While adding additional context will likely improve the results of your table-heavy RAG pipeline, it is a more expensive method due to further calls to the LLM to gather and create context. For datasets with a few simple tables, it might not be necessary.
My experimentation highlighted that using non-contextualized table chunks works reasonably well for simple tables; however, they fall short as they gain complexity, for example, with nested columns (as shown in ‘Example 4’).
Conclusion
The challenge of accurate Retrieval-Augmented Generation (RAG) for table-heavy documents requires a methodical approach that addresses retrieval inconsistency and generation inaccuracy. By implementing a strategy that includes precise extraction, contextual enrichment, format standardization, and unified embedding, we can significantly enhance the performance of RAG when dealing with complex tables.
The results from the meta-earnings example highlight the improved quality of generated responses once enriched with table chunks. As RAG continues to evolve, incorporating these techniques could be an excellent choice for ensuring reliable and precise outcomes, particularly in table-heavy datasets.
If you enjoyed reading this blog, why not try out some of our other examples:
You can also visit the KX Learning Hub to begin your certification journey with KX.