

In 2023, KX launched KDB.AI, a high-performance vector database designed to help organizations build scalable, enterprise-grade AI applications and advanced RAG-based solutions. In our latest update, KDB.AI 1.3, we introduce several new features to reduce memory consumption and improve search performance.
Let’s explore
Fuzzy filtering
Fuzzy filtering in KDB.AI 1.3 enhances the accuracy and relevance of search results by allowing for approximate matches rather than exact ones. It’s helpful in scenarios where data may have inconsistencies or where users might have input queries with slight variations.
For example:
-
- A trader accidentally types “Aple” instead of “Apple” while searching for stock price information for Apple. Inc
-
- The query and available stock information are converted into vectors, allowing the system to understand the semantic meaning behind the query
-
- Fuzzy filtering identifies that “Aple” is similar to “Apple” based on the composition of the words. This is achieved by using techniques like Levenshtein distance, which measures the number of single-character edits needed to change one word into another
-
- Filters are then applied to include closely matched results, ensuring that even with the typo, the trader receives the relevant stock price information for “Apple”
By accommodating variations in search queries, fuzzy filtering bridges the gap between user intent and available information, resulting in more satisfying interaction and improved efficiency.
To find out more, please visit our documentation hub.
New on-disk indexing
Traditional vector indexes are stored in memory to provide the fastest response times. However, they can become constrained as indexes grow and memory resources deplete. To address this, KDB.AI boasts two on-disk indexing solutions, qFlat and qHNSW.
qFlat
With the exception of on-disk processing, qFlat performs like a typical Flat index whereby vectors are stored in their original form and searched exhaustively. Query vectors are then compared against all other vectors in the database using a distance calculation such as Euclidean distance or cosine similarity.
Flat indexing is often used for real-time data ingestion, creating vectors with minimal computation for smaller-scale databases. It guarantees 100% recall and precision but is less efficient than other index types.
By offloading to disk, qFlat can support larger indexes with higher dimensionality. It ensures data persists even after the system restarts and provides a more cost-effective solution for customers wishing to lower operating costs.
qHNSW
qHNSW is introduced in KDB.AI 1.3 and acts as an HNSW index variant for approximate nearest neighbor (ANN) searches in particularly high-dimensional spaces. It is suitable for large-scale databases requiring improved search speeds and moderate accuracy.
Operating over multiple sparse layers, it creates an efficient search solution in which each vector connects to its neighbors based on proximity.
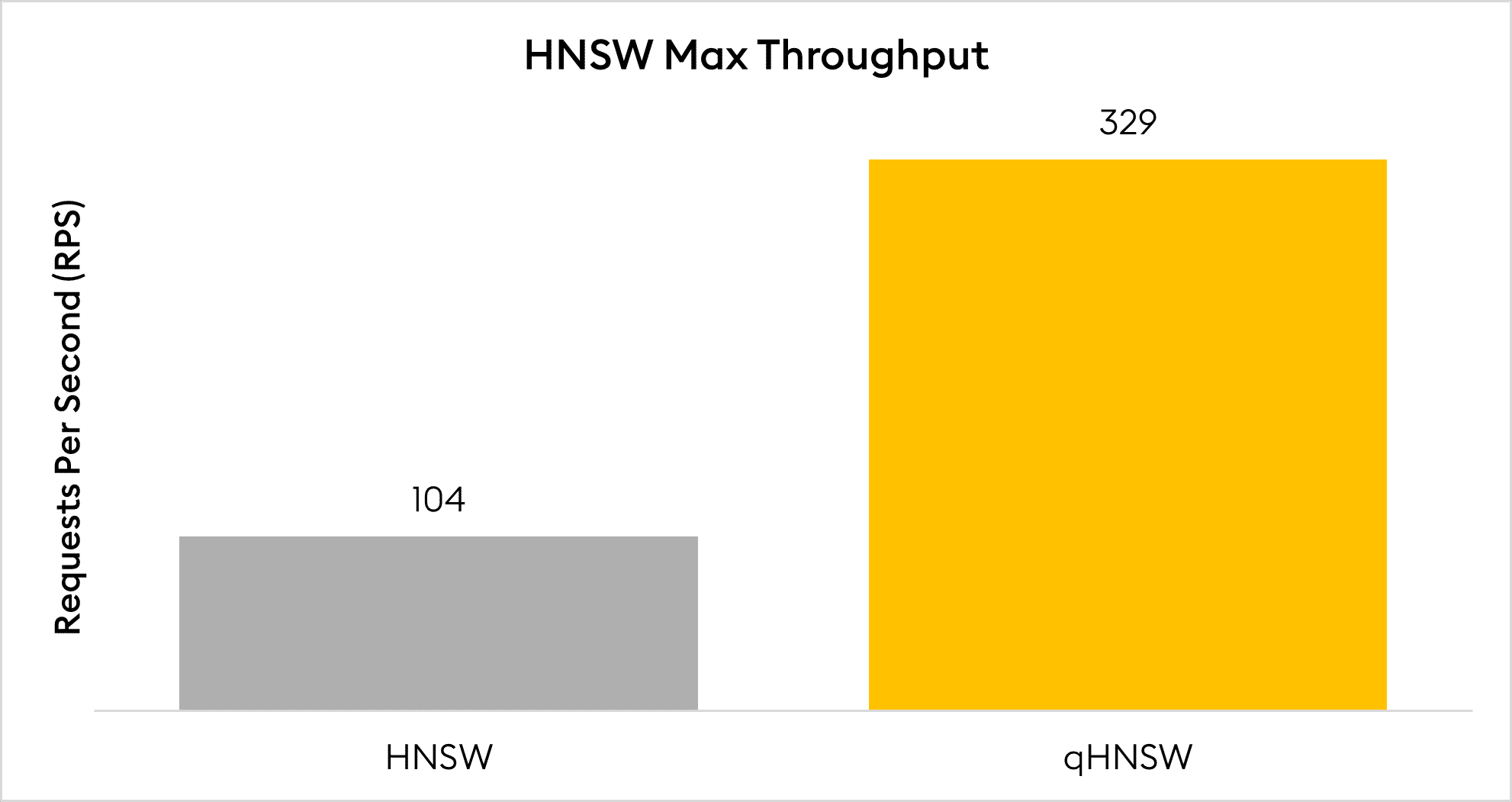
qHNSW presents a significant advancement in vector indexing, performing 3.16 times faster than FAISS-based HNSW during testing for unprecedented scalability without compromising speed.
Benefits:
- Reduced memory footprint when compared to traditional HNSW indexes
- Low memory utilization with incremental disk access
- Persistent indexing with increased storage capacity
- Reduced total cost of ownership (TCO)
qHNSW is Ideal for applications such as recommendation systems, natural language processing, and image retrieval. And because it shares the same underlying data structure as qFlat, developers can switch between high-performance approximations and exhaustive searches depending on workload.
To find out more, please visit our documentation hub.
We can’t wait to see what possibilities these enhancements bring to your AI toolkit and invite you to sign up for your free trial of KDB.AI here.