
No one likes a know-all – certainly not the human variety anyway, the one with an answer to every question and a view on every subject. Ironically though, that’s precisely what we want from AI systems: instant, well-informed, trustworthy responses to any question that we can act upon.
Achieving such depth of knowledge is just as challenging for a computer as it is for a human: new information pours in every second, but there are contradictory “facts”, incomplete sources, erroneous sources, and possibly inaccessible sources. So how can AI systems be infused with validated, up to date, and sometimes private information that enables them to deliver accurate, informed responses? The answer is Retrieval Augmented Generation (RAG) and KX’s Developer Advocate team is delivering a series of LinkedIn Live sessions to explain it.
Introducing RAG
In the first instalment of the series on RAG, Neil Kanungo and Ryan Siegler introduce how to implement RAG using KDB.AI, KX’s vector database, and LangChain, an open source framework for building applications with Large Language Models (LLMs). They provide some background on RAG and explain how it complements your LLM with additional information in the form of vector embeddings. Those embeddings, effectively digital encodings of text, videos, pdfs, or other data, provide information your LLM didn’t have access to when it was trained initially. Examples could include:
- Private, internal information such as contacts, internal policies or personnel records
- Corrections or updates to previously published information or official records
- Price changes, news updates or corporate action events that have occurred in the interim
Whatever the class of information, RAG can help fill the gap.
RAG has two primary steps:
- “Retrieval,” where, based on the query, additional related information is extracted from internal sources
- “Generation,” where that additional data is passed, along with the original question, to the LLM for it to use in generating its response
Conceptually, it looks like this.
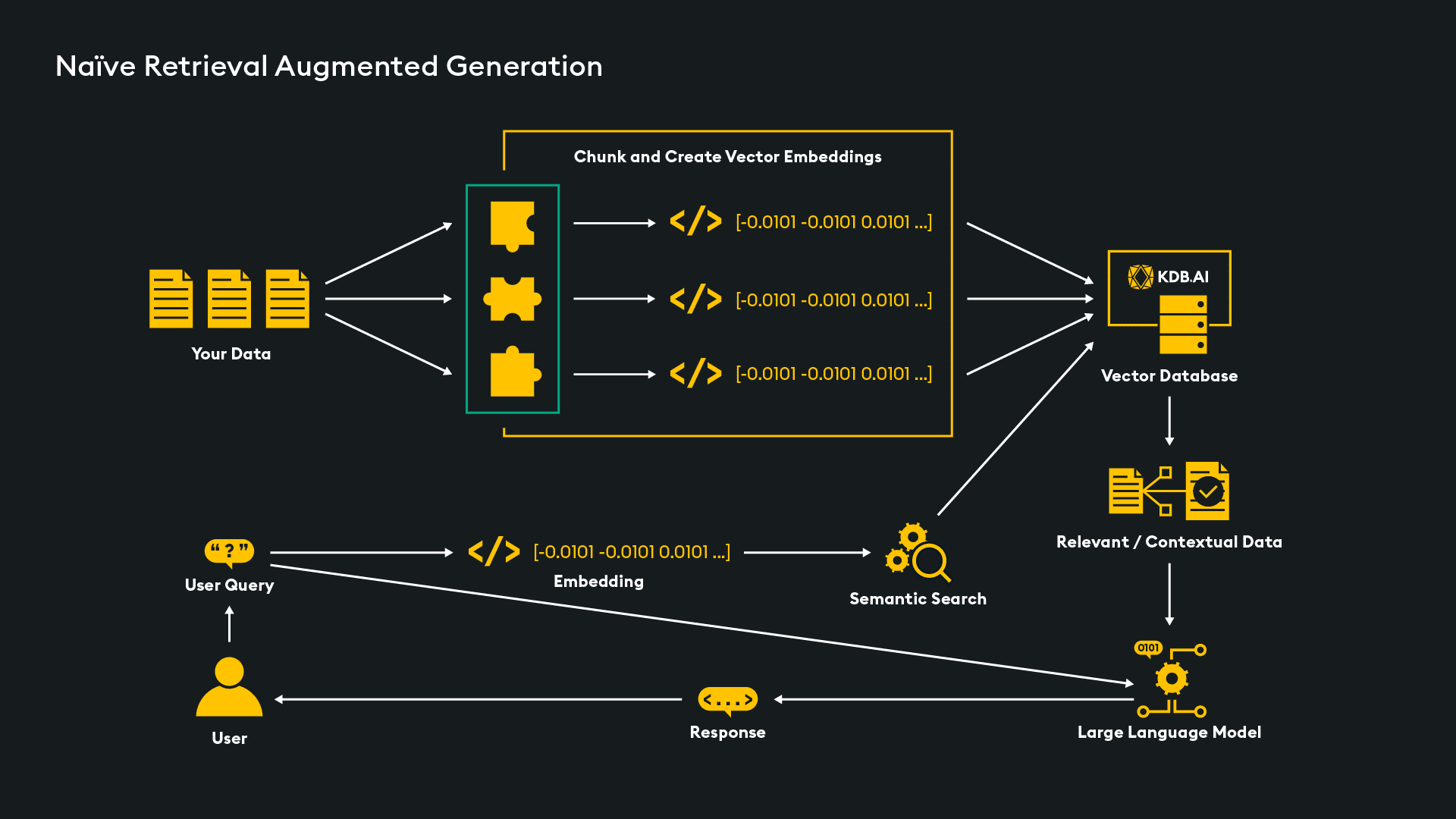
Starting at the top left, data (in our example pdfs, but it could be any other file format) is ingested and pre-processed into “chunks,” then into embeddings that are stored in the KDB.AI vector database. This database forms the augmented knowledge store for responding better to queries. When a user query (or “prompt”) is submitted, it is similarly converted into embeddings and used in a semantic search across the vector store to retrieve similar embeddings that identify additional information relevant to the query. That information is then passed along with the initial prompt to the LLM to augment it in generating its response.
This approach is referred to as “Naïve Rag” and while relatively simple to implement for Proof-of-Concepts or prototype projects, it may be inefficient in production as it operates quite indiscriminately in conducting similarity searches. For example, even when the query may be unrelated to information in the data store, it will still search, wasting resources and potentially providing irrelevant data – the very problem it was seeking to solve. One alternative approach is Agent Assisted RAG, which uses the LLM to preprocess the prompt and decide the best next step which could:
- Pass the query to the LLM directly
- Augment with additional information from the content store
- Or potentially redirect it to a completely different tool for providing the answer
Another approach is Guardrail RAG which can set boundaries on topics or questions it will respond to or give pre-determined canned responses on others.
Seeing RAG In Action
A live demo of RAG was shown, using a Python Notebook invoking both the KDB.AI vector database and LangChain, downloadable from GitHub via the KDB.AI Learning Hub.
The demo explained the installation, package imports, and API-key set-up. It showed how the text of the State of the Union address to the US Congress was imported using TextLoader, one of LangChain’s many different loaders for different source formats. LangChain was shown to include different chunkers (text splitters) to pre-process data, offering controls over chunk sizes and supporting overlapping when required, depending on the source data profile. A follow-up article will discuss this topic in more detail. OpenAI’s embedding model was then used to create the vector representation of each of the chunks. These are consequently stored in KDB.AI where the schema is specified along with details of the chosen search algorithm. Now, the system is able to deliver RAG-based responses to user queries.
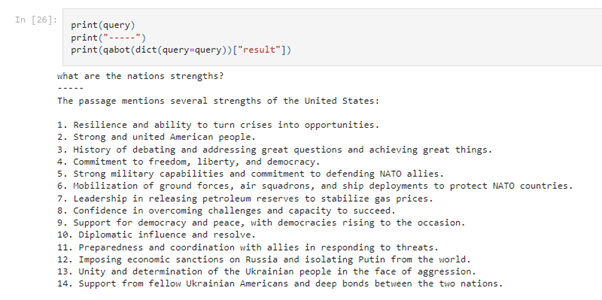
In the demo, Ryan asked “What are the nations strengths?” and the similarity search returned (Retrieved) a subset of the State of the Nation address that it added to (Augmented) the query when submitted to the LLM. To illustrate how LLMs could deliver variable responses, it was sent separately to the OpenAI (GPT3) and Hugging Face LLMs.
The OpenAI response delivered a concise “The American people are strong and capable of turning any crisis into an opportunity.”

The Hugging Face response is a more succinct “Possibilities” reflecting the fact that its model is designed more for short and concise answers as opposed to the more discursive nature of GPT.

The potential for even further variation is illustrated by using a different generation model (GPT 3.5 Turbo) and by selecting a different retrieval algorithm, which in turn provides different augmentation text to the LLM. The example below uses RetrievalQA, which enables augmentation of a configurable number of chunks. In this case, 10 is configured and OpenAI responds with a longer list of characteristics based on that additional information in the prompt.
A valid concern when rolling out AI-driven applications is the risk of invalid, inaccurate responses, or so called “Hallucinations”. The power of KDB.AI coupled with the convenience of LangChain can help organisations quickly and easily use RAG to mitigate those concerns by augmenting their selected LLM with additional, well-defined and curated information.
Watch the webinar in full or follow KX on LinkedIn to follow each new episode in the series.