

Key Takeaways
- Backtests often fail in production because the research environment does not match the live environment closely enough.
- The gap usually grows through data extracts, rewritten logic, different timestamp rules, and separate production pipelines.
- More model validation does not prove that production will see the same data or run the same assumptions.
- Production-ready research needs a clearer path from notebook work to live workloads.
- KDB-X helps by giving teams a common time-series-native environment for Python, SQL, and q workflows, with fewer handoffs between research and production.
Your team spends three months developing a strategy. The walk-forward windows hold, the Sharpe ratio looks defensible across five years, and the execution assumptions pass review. Then the strategy goes live and loses money in the first two weeks.
The post-mortem usually starts with the model. Was it overfit? Did the regime change? Did the execution assumptions fail under live conditions? Those questions matter.
They can also pull attention away from a more basic issue: your strategy may have been researched in an environment that did not match how it would run in production.
Research often happens in Python notebooks, on curated extracts, with simplified assumptions and data prepared for analysis. Production runs against live or operational systems, with different data access paths, timestamp handling, enrichment rules, and performance constraints. Your strategy may be sound in research and still behave differently when the surrounding environment changes.
Before rebuilding the model, ask whether your research process tested the same data, logic, and assumptions that production used.
What creates the research-to-production gap
The gap rarely comes from one obvious failure. It usually grows through small differences between your research workflow and your production workflow — and those differences almost always trace back to fragmented infrastructure.
Research runs in Python notebooks. Production runs in q or a separate operational system. Streaming data lives in Kafka. Vector workloads go somewhere else. Each tool is reasonable for its purpose. Together, they create a stack where every handoff is a place where timing assumptions, enrichment logic, and data access patterns can diverge silently. If you are running this kind of fragmented infrastructure, you are likely spending 60–80% of your engineering budget just keeping it connected.
Common sources of drift include:
- Research extracts that fall out of sync with production datasets.
- Local transformations that are not reproduced exactly in production.
- Timestamp and ordering rules that differ between research and live systems.
- Reference data or enrichment logic applied differently across environments.
- Models or signals rewritten when they move from notebook code into production code.
- Validation performed on data that is cleaner, narrower, or more static than the live environment.
The result is a backtest that answers a narrower question than you intended. It shows how your strategy performed in the research setup. It does not show how the same strategy will behave when production data, production timing, and production constraints apply. Research into this problem finds that 55% of persistent errors in financial AI trace back to time omissions — timestamp drift, missing temporal context, assumptions about ordering that do not hold in production.
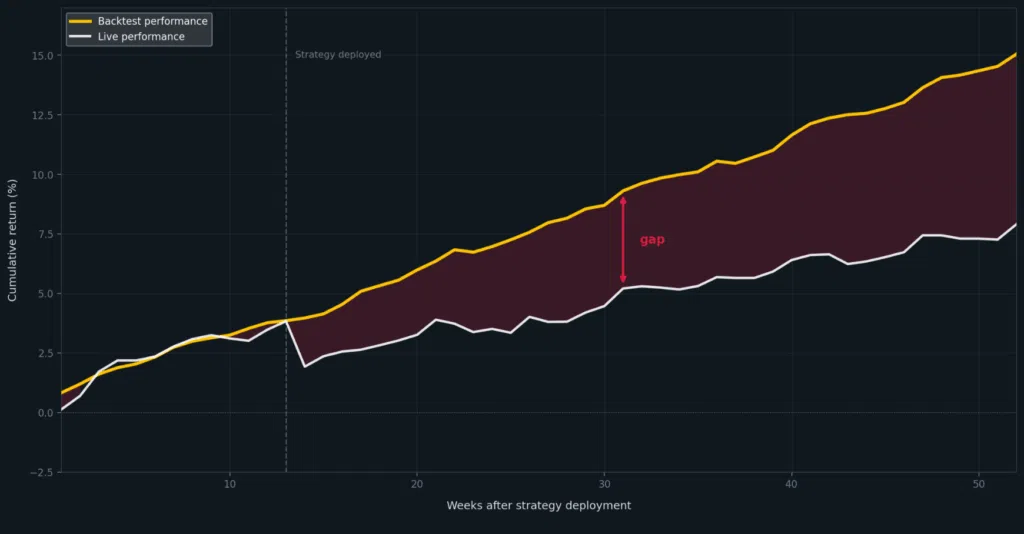
Why more validation does not close the gap
When a backtest fails to replicate, you often tighten the model process: more regularisation, more conservative walk-forward windows, longer holdout periods. Those are good controls for model risk.
They do not prove that your production environment matches your research environment. Regularisation cannot fix a data extract that differs from production. Walk-forward testing does not prove that timestamp logic, enrichment rules, or execution assumptions will be applied the same way live. A longer validation period still tests the strategy inside your research setup.
More validation can make the process feel safer than it is. You extend development cycles, add checkpoints, and still see live divergence — because the test measured the wrong thing: research performance under research conditions.
A stronger process tests your strategy closer to the environment where it will run.
What production-ready research requires
Production-ready research needs more than a good notebook and a clean backtest. It needs a workflow that keeps your research, analytics, and production close enough that assumptions do not change silently along the way.
That requires a few things to be handled consistently:
- Data access, so your research and production work from connected sources rather than disconnected extracts.
- Timing rules, so ordering, joins, and alignment behave the same way during testing and live use.
- Enrichment logic, so reference data, classifications, and derived fields are applied deliberately.
- Code promotion, so your signals do not need to be rewritten before deployment.
- Performance context, so your research tests reflect the latency, scale, and workload constraints that matter in production.
This is where infrastructure matters. When your research, historical analytics, and production use separate stores, languages, and runtime assumptions, every handoff adds release risk. The cost is slower research cycles, duplicated validation work, and less confidence in every model promotion decision.
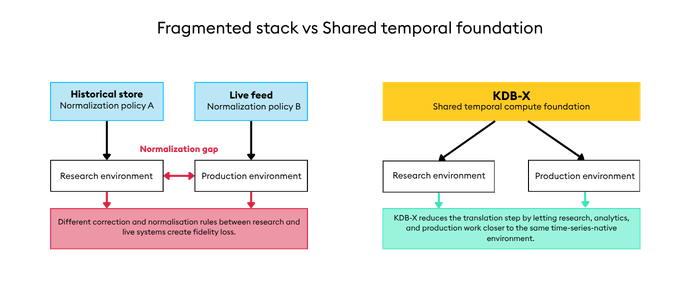
How KDB-X helps
KDB-X gives you a single dual-mode engine — time-series and vector data in one query, one platform — so your research and production share more of the same code path from the start.
That matters because the gap is not a model problem; it is an infrastructure problem. When your research happens in disconnected notebooks and production runs on a separate system, every promotion decision requires a rewrite and a reconciliation step. KDB-X changes where the work happens: Python, SQL, and q all operate against the same engine, so what you test is closer to what you deploy.
| What creates the gap | How KDB-X helps |
|---|---|
| Research uses extracts that drift from production data | You run research and analytics against the same KDB-X environment used for operational workloads |
| Notebook logic has to be rebuilt for production | Python, SQL, and q work against the same system — one code path from your research to production |
| Timestamp and join assumptions differ across tools | Time-series operations are applied consistently in one engine |
| Production data is hard for non-q users to access | Python and SQL are first-class languages; q remains available for performance-critical work |
| Open-format data requires extra pipelines | KDB-X supports Parquet natively — no ETL layer between your data stack and time-series analytics |
For Python-based research workflows, PyKX is especially important. It connects your Jupyter and pandas workflows directly to KDB-X, removing the need to copy data into a separate research environment before testing. You get a more direct path from exploration to production-grade analytics without switching tools or rewriting logic.
KDB-X also handles the broader workflow: historical data, streaming data, vector workloads, and open formats in one engine. Fewer copies. Fewer rewrites. Fewer places where your tested strategy and your deployed strategy become different things.
Closing the gap
When your strategy looks right for five years and breaks in two weeks, the model is only one place to look.
The path from research to production deserves the same scrutiny.
KDB-X helps you close that gap — not by adding more validation, but by reducing the infrastructure distance between where you test strategies and where you run them. One environment. One code path. What you test is what you deploy.
To examine this in your own environment, try KDB-X Community Edition or book a session with one of our experts.


