
Key Takeaways
- Handling petabyte-scale structured and unstructured data with precision, speed, and reliability requires infrastructure built for production.
- Unlike traditional software, AI agents, powered by large language models (LLMs), complete specific tasks independently, adapting behaviour based on context.
- Agentic frameworks require a carefully integrated stack of high-performance technologies.
- KX, in collaboration with NVIDIA, has developed a GPU-enabled AI lab tailored for high-performance, production-scale use cases.
Co-author: Ryan Siegler
Despite the hype for GenAI and RAG on unstructured data, the financial industry relies heavily on deterministic AI, machine learning (ML), and deep learning (DL) for core quantitative analytics and market strategies. These techniques provide the backbone for processing high-velocity and high-volume market data and extracting precise, structured insights for alpha generation and risk management.
In my previous articles, GPU-accelerated deep learning with kdb+ and GPU-accelerated deep learning: Real-time inference, we explored training, validating, and backtesting a deep-learning trading model with real-time inference. Today, we will take this a step further and explore how to achieve more holistic insights by using agents to complete essential tasks for comprehensive financial research and analysis.
This will include the following agentic tasks:
- Search: Leverage RAG and AI vector search to query multimodal structured/unstructured knowledge bases, documentation, SEC filings, financial reports, internal company data, and analyst reports.
- Calculate: Utilize kdb+ for real-time/historical queries, aggregations, and complex calculations directly on structured market or operational data.
- Predict: Integrate GPU-powered ML/DL models for accelerated predictions and live/historical data forecasting.
- Monitor: Leverage the “always-on” event-driven monitoring agent via kdb+ to scan petabytes of information to flag critical business events, market anomalies, or stoppages with techniques like Temporal IQ and pattern detection.
- Act: Take automated actions on behalf of users.
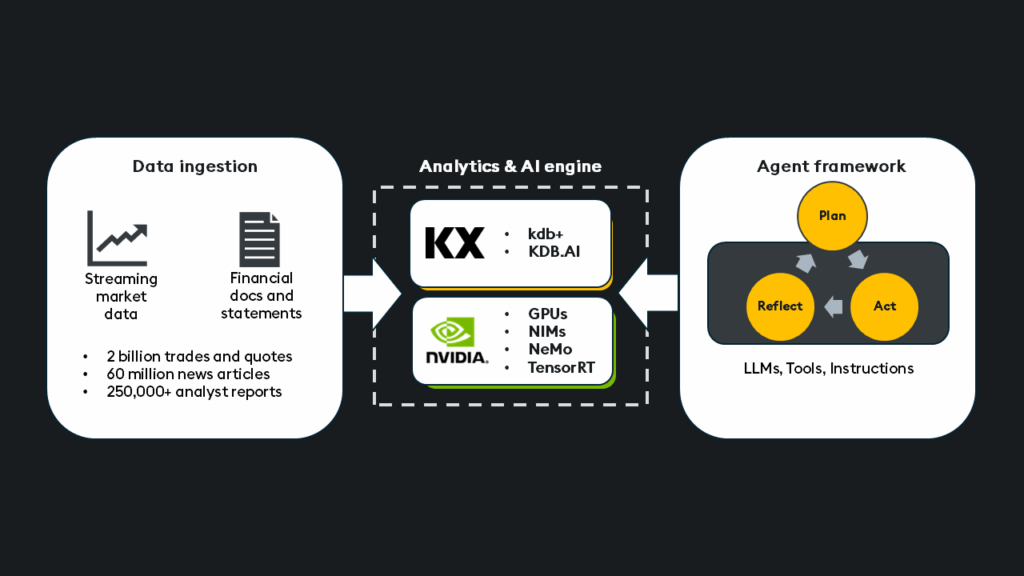
By building AI agents with these capabilities, we move beyond simple unstructured data retrieval towards a system that can reason across, calculate upon, predict from, and take action based on your entire data estate and thousands of external data sources.
From hype to production
AI agents, powered by large language models (LLMs), are designed to complete specific tasks independently. Unlike traditional software, they don’t follow pre-coded logic but reason, make decisions, and adapt their behavior based on context. Their ability to interact with external systems through APIs, search engines, databases, or even other agents means they can gather fresh context, perform tasks, and dynamically respond to events.
Agents can effectively handle complex or ambiguous tasks by selecting which tools to use based on the current state of the workflow and sometimes chaining together multiple steps with a mix of precision and nuance.
At a high level, an agent is composed of three core components:
- Model: (usually a language model) for decisioning and reasoning.
- Tools: The model can call extensions to take action or gather external data.
- Instructions: The prompt, goal, or policy that defines what the agent is trying to accomplish.
Although agents can operate solo, managing multi-step workflows independently, multi-agent systems become valuable as tasks grow in scale and complexity. These systems distribute work across specialized agents, each with their own tools and responsibilities, allowing them to collaborate and achieve broader goals more efficiently.
Types of agentic systems:
While there are many frameworks and orchestration strategies for building agents, we can roughly group them into two functional categories:
- Goal-seeking agents: Once given a specific goal or objective, the agent plans how to accomplish it: selecting tools, analyzing data, and iterating as needed.
- Autonomous agents: Determine which goals to pursue and how to achieve them, revising objectives based on new information without human intervention.
Let’s ground this in a use case.
Equity research assistant
Banks and financial firms must consider all available information when making decisions and trading strategies. Analysts are tasked with researching and developing a comprehensive understanding of all available data, a time-intensive task even with AI assistance.
Market data can span petabytes and requires more in-depth analysis than retrieving relevant documents via RAG; it requires low-latency structured data analytics and forecasting.
Using a multi-agent goal-seeking architecture, the equity research assistant transforms this workflow, condensing information gathering, analysis, and citations from hours to minutes. This enables faster access to more accurate, current, and thorough answers to highly complex questions.
Features include:
- Context-aware understanding: Applies a temporal lens, automatically narrowing analysis to relevant time windows and tracking how events evolve.
- On-demand analytics: Dynamically computes new insights (volatility, moving averages, peer comparisons) using KX’s high-performance time series engine without manual intervention or post-processing.
- Cross-domain intelligence: Connects and analyses SEC filings, transaction data, proprietary research, and real-time market feeds within a single query, breaking down silos between structured and unstructured data.
- Agentic workflow automation: Orchestrates ingestion, analysis, and publishing tasks (Client decks, CRM notes, Slack messages, email).
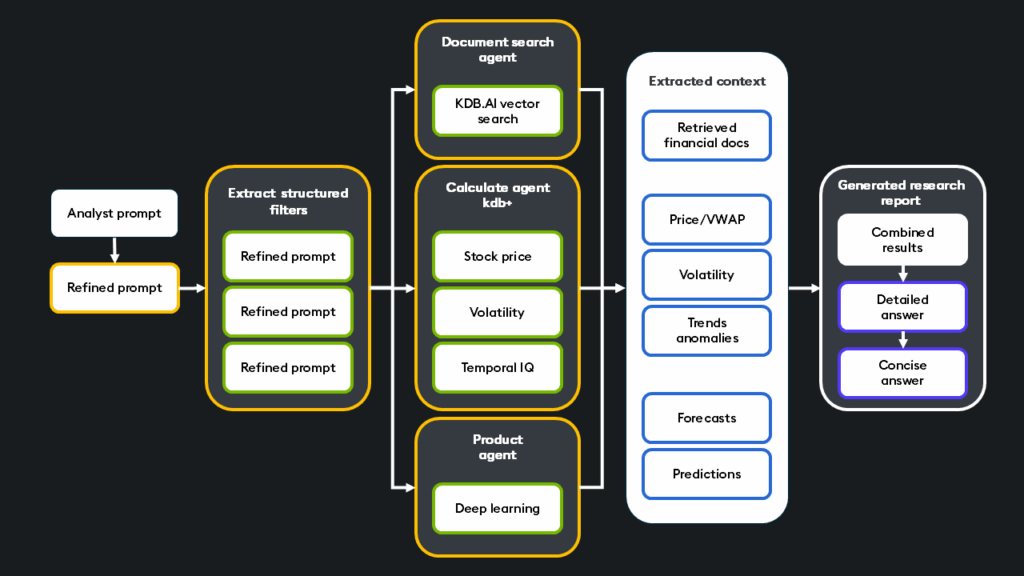
This architecture illustrates how the equity research assistant utilizes multiple agents for search, calculation, and prediction.
Demo
This video demo shows an example workflow of the equity research assistant. Given a complex and multi-part question, it first breaks down the question into sub-questions and extracts relevant structured information from the refined prompt. From here, the framework of agents search for relevant unstructured data and executes various structured queries. Once the contextual information is gathered and calculated, it is combined, and both long and concise answers are generated for the analyst.
Why use agents?
At first glance, one might wonder: Why not just use a single LLM with access to the necessary tools or chain together reasoning steps in a preset flow? While these approaches work for lighter use cases like Q&A, they fall short when questions are highly varied and require specialized reasoning across many data types.
This system’s ability to autonomously break down complex research prompts into specialized subtasks makes this system agentic, delegating each to dedicated agents with their own tools and responsibilities. These agents reason independently, plan collaboratively, and coordinate their actions toward a shared goal: generating a high-quality, accurate research report. This multi-agent framework mirrors the real-world structure of a research team, analysts, quants, and ML engineers, each with distinct roles, working together to deliver comprehensive, context-rich insights.
Unlike static reasoning chains or monolithic LLM implementations, agents have the autonomy to:
- Interpret the intent of its prompt and incoming data from surrounding agents, decide which actions are necessary, and adjust plans dynamically
- Delegate complex sub-tasks (like stock volatility analysis or pattern detection) to specialized agents/tools
- Perform inter-step reasoning. For example, the Predict Agent may decide to adjust its model inputs based on anomalies flagged by the Calculate Agent.
- Adapt to question variety, where some require heavy historical modeling; others call for extracting key sections from a 100-page filing. The system dynamically adapts the workflow to match.
In short, agents allow us to treat equity research not as a transaction but as a process that can flexibly evolve, branch, and optimize in real time, much like the analysts it’s designed to augment.
The agentic stack:
The agentic framework’s ability to address highly complex financial questions stems from a carefully integrated stack of high-performance technologies designed to handle diverse data types at scale and orchestrate sophisticated AI workflows.
Let’s break this down:
Core components:
- High-performance data platform (kdb+/AI): Manages petabyte-scale historical/real-time data, providing the engine for low-latency queries and calculations. It incorporates vector search capabilities for efficient temporal similarity search, ensuring data is immediately available for querying without the need for other systems.
- GPUs: Accelerate the computations involved in deep learning model inference, unified multimodal embedding generation, and large language model processing.
- NVIDIA NIM (NVIDIA Inference Microservices): Provides a suite of optimized microservices for deploying AI models on GPUs, including:
- LLM inference: Nemotron-70B, Llama 3, and Mistral efficiently on GPUs.
- Embedding models: Including NV Embed V2 for generating multimodal embeddings up to 30x faster than CPU-based methods.
- NVIDIA NeMo framework: Provides tools for customizing and deploying generative AI models reliably and securely:
- NeMo curator: Processes and prepares large datasets for training and retrieval.
- NeMo retriever: Services for efficiently retrieving relevant data from vector indexes.
- NeMo re-ranker: Optimizes search results by refining the order of retrieved documents based on relevance.
- NeMo guardrails: Ensures model interactions are safe, secure, and within defined topics.
- Agentic framework: Libraries and frameworks used to build, manage, and orchestrate the agent’s logic, defining how it executes tasks, accesses data, and manages workflows.
- Model deployment framework (NVIDIA TensorRT): Optimizes trained deep learning models for high-performance, low-latency inference, specifically on NVIDIA GPUs.
Operational flow:
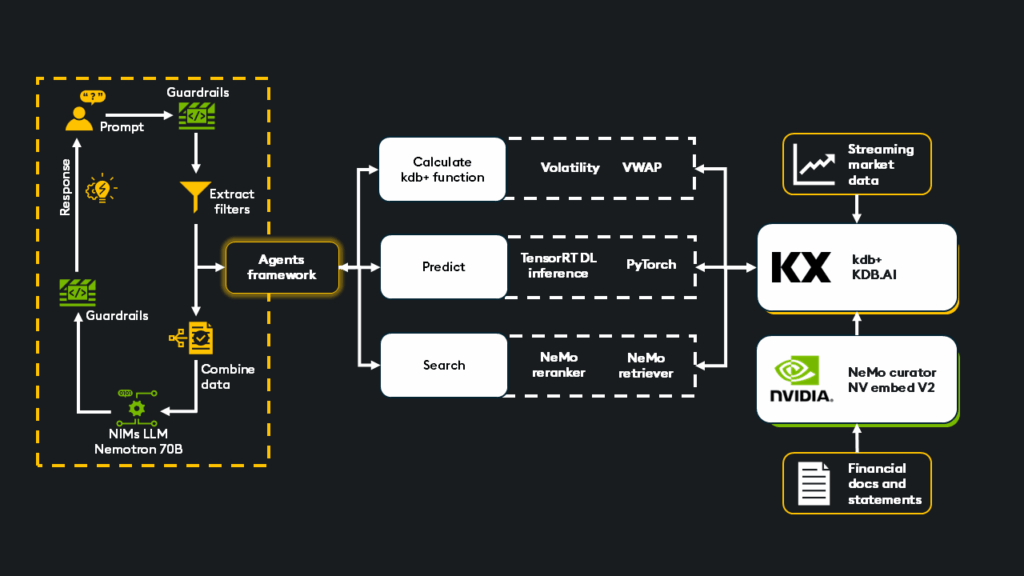
- Unstructured data ingestion: Documents are ingested and processed using NeMo Curator. Embeddings are generated via NIMs for unified multimodal representation and stored in KDB.AI (partitioned across in-memory or on-disk indexes and efficiently memory-mapped as needed).
- Structured data ingestion: Market data feeds (trades, quotes) flow through kdb+ tickerplant architectures into the real-time (RDB) database and RT processor.
- User prompt handling: Incoming user requests are processed, potentially refined, and checked against NeMo Guardrails for safety and topic relevance.
- Agentic framework: Prompt passes to the agent framework, where intelligent reasoning formulates a response strategy. The optimal sequence is determined by selecting the appropriate agents to deliver a high-quality response.
- Unstructured retrieval (search): The NeMo retriever queries the KDB.AI vector index before the NeMo re-ranker refines the results to find the most relevant documents.
- Structured retrieval/analytics (calculate): The agent leverages kdb+/PyKX/q to perform highly optimized queries directly against the structured data in the real-time/historical databases (RDB/HDB). This can include basic queries or more complex calculations like VWAP, volatility, moving average, and slippage.
- Deep learning inference (predict): Optimized TensorRT models, running on GPU infrastructure, are called via kdb+ functions to predict and forecast live/historical data events.
- Combine results: The outputs from each agent converge. Structured and unstructured data, proprietary and public, are unified to create a context-rich repository of information passed onto an LLM.
- LLM response generation: NIMs efficiently run the chosen LLM to generate a synthesized response based on the information gathered from the search, calculation, and prediction steps. The response is then presented back to the user via NeMo guardrails.
Handling petabyte-scale structured and unstructured data with the precision, speed, and reliability demanded by the financial industry requires more than just a clever idea; it requires infrastructure built for production. Every complex user query could trigger dozens of agentic tool invocations and LLM calls, each demanding high-throughput inference. That’s why we strategically deploy GPU acceleration exactly where it matters, accelerating embedding generation, vector retrieval, deep learning inference, and LLM responses. This, in turn, significantly reduces time-to-first-token (TTFT) and ensures fast, accurate, and context-rich responses at scale.
AI lab implementation
Experimenting with production-level generative AI often demands significant upfront investment in infrastructure and specialized expertise. To lower this barrier and accelerate time-to-value, KX, in collaboration with NVIDIA, has developed a GPU-enabled AI lab tailored for high-performance, production-scale use cases.
Everything required, from infrastructure and networking to orchestration and security, is bundled into a single, streamlined solution that enables you to launch a proof-of-concept environment at a production scale.
Participants can access resources, expertise, and the latest cutting-edge software to explore and validate their AI ideas.
Request access here: https://kx.com/nvidia-and-kx-next-gen-analytics-in-capital-markets/
As the financial services industry evolves, the ability to generate real-time, deeply contextual insights from petabyte-scale structured and unstructured data is becoming a competitive necessity. Agentic AI systems represent a transformative leap forward, moving beyond retrieval into a new paradigm where AI can reason, calculate, forecast, monitor, and act on behalf of analysts. By combining the ultra-low latency of kdb+, the intelligent vector search of KDB.AI, and GPU-accelerated inference powered by NVIDIA, firms can operationalize generative AI at production scale, securely, reliably, and with minimal latency.
If you have questions or wish to connect, why not join our Slack channel? You can also check out the other articles in this series below.


