
Augmenting LLMs with query-relevant information via RAG will produce high-quality generated responses and is significantly cheaper than ingesting your entire dataset into the context window.
RAG introduces specific and relevant data to an LLM and consists of two key steps:
-
- Retrieval: Based on a user’s query, retrieve relevant data from a vector database.
-
- Generation: Pass the retrieved data and the user’s query to the LLM, which generates a response.
There are many ways to optimize RAG, and in this blog, we will explore the concept of multi-index search. This method optimizes the vector retrieval mechanism by using multiple indexes in parallel to improve the accuracy of retrieved data.
Multi-index search
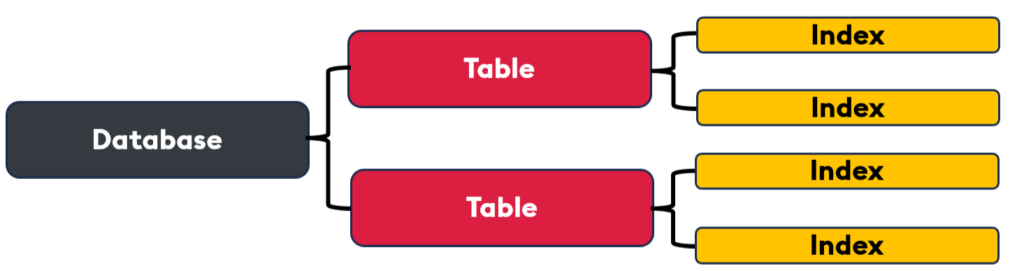
With KDB.AI, you can create and manage multiple indexes on a single table, allowing for several flexible and efficient query strategies. This ensures you can execute searches across different indexes simultaneously, enabling more nuanced and comprehensive results.
Multi-index search is particularly beneficial for several use cases:
- Multimodal retrieval: Search both image and text embeddings simultaneously. This pairs nicely with CLIP embeddings
- Hybrid search: Define separate indexes, one dense for semantic similarity and another sparse for BM25 keyword search
- Multi-layered embeddings: Each index can hold embeddings of different dimensions, allowing users to search across multiple dimensionalities
Implementation
Let’s explore the conceptual foundations and hands-on code implementations of two multi-index use cases: hybrid search and multimodal RAG.
Hybrid search
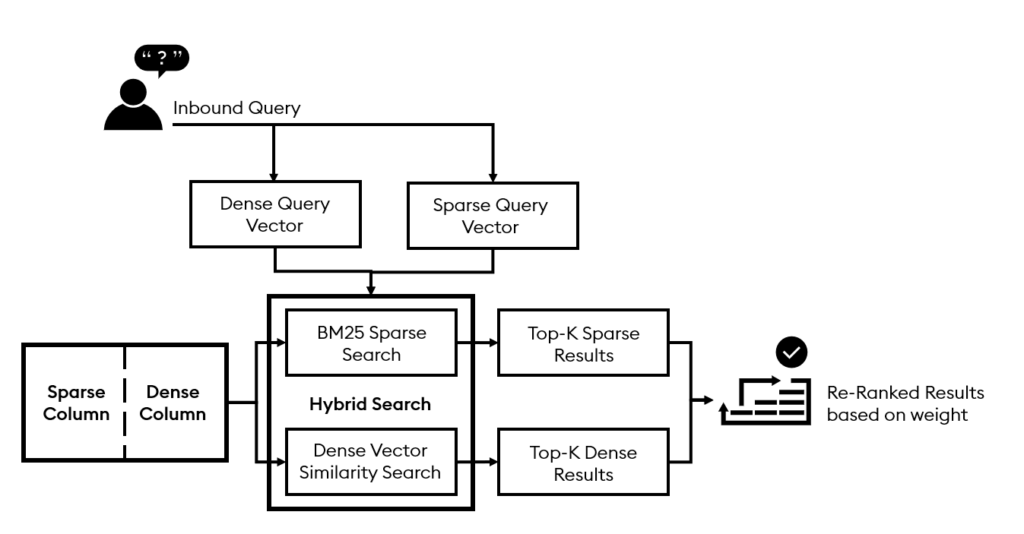
Hybrid search leverages a multi-index approach to enhance result relevance by combining the strengths of two powerful methods: the precision of keyword-based sparse vector search and the contextual depth of semantic dense vector search.
- Sparse vectors: High-dimensional vectors with mostly zero values and a few non-zero elements. They are created by tokenizing a document into words or sub-words, mapping them to numerical tokens, and counting their frequencies
- Dense vectors: High-dimensional vectors with mostly non-zero values, capturing a document’s semantic meaning and relationships. They are created by processing the document through an embedding model, which outputs a numeric data representation
With KDB.AI, developers can create indexes for sparse and dense vectors in the same table, enabling an independent or combined hybrid search. Hybrid search combines and reranks the results based on set weight values that weigh each index’s importance.
How it works
Dense vector searches offer configurable options, including index types (Flat, qFlat, HNSW, qHNSW, IVF, IVFPQ), dimensionality, and search methods (cosine similarity, dot product, Euclidean distance). These searches prioritize finding the most semantically relevant results.
Sparse vector searches leverage the BM25 algorithm to identify the most relevant keyword matches through advanced string matching, considering keyword frequency, rarity, and term saturation. KDB.AI allows developers to dynamically tune BM25’s ‘k’ and ‘b’ parameters at runtime, providing flexibility for specific use cases. Additionally, KDB.AI uniquely updates BM25 statistics whenever new data is added, ensuring relevance scoring reflects the latest sparse data.
1: Let’s explore the code.
!pip install kdbai_client
!pip install sentence-transformers langchain langchain-community
import pandas as pd
import numpy as np
import os
from getpass import getpass
import kdbai_client as kdbai
import time
from transformers import BertTokenizerFast
from collections import Counter
# Ignore Warnings
import warnings
warnings.filterwarnings("ignore")
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
2: Download the Federal Reserve inflation speech.
### This downloads Federal Reserve Inflation speech data
if os.path.exists("./data/inflation.txt") == False:
!mkdir ./data
!wget -P ./data https://raw.githubusercontent.com/KxSystems/kdbai-samples/main/hybrid_search/data/inflation.txt
3: Ingest & chunk the speech.
### Load the documents we want to prompt an LLM about
doc = TextLoader("data/inflation.txt").load()
### Chunk the documents into 500 character chunks using langchain's text splitter "RucursiveCharacterTextSplitter"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
### split_documents produces a list of all the chunks created
pages = [p.page_content for p in text_splitter.split_documents(doc)]
### Create a blank dataframe to store chunks and vectors in before insertion
data = {
'ID':[],
'chunk': [],
'dense': [],
'sparse': []
}
# Create the DataFrame
df = pd.DataFrame(data)Now we have our data chunked and an empty dataframe with the four columns ‘ID’, ‘chunk’, ‘dense’, and ‘sparse’.
4: Create the dense and sparse vectors for each chunk.
### Tokenizer to create sparse vectors
token = BertTokenizerFast.from_pretrained('bert-base-uncased')
### Embedding model to be used to embed user input query
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
### Create sparse and dense vectors of each chunk, append to the dataframe
id = 0
for chunk in pages:
### Create the dense query vector
dense_chunk = [embedding_model.encode(chunk).tolist()]
### Create the sparse query vector
sparse_chunk = [dict(Counter(y)) for y in token([chunk], padding=True,max_length=None)['input_ids']]
sparse_chunk[0].pop(101);sparse_chunk[0].pop(102);
new_row_df = pd.DataFrame([{"ID": str(id), "chunk": chunk, "dense": dense_chunk[0], "sparse": sparse_chunk[0]}])
df = pd.concat([df, new_row_df], ignore_index=True)
id += int(1)
df.head()
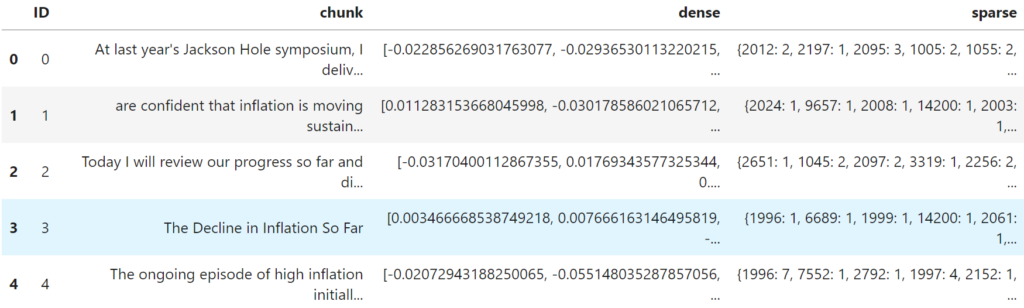
DataFrame loaded with ID, chunk, dense vectors, and sparse vectors
5: Connect to KDB.AI vector database.
#Set up KDB.AI endpoint and API key
KDBAI_ENDPOINT = (
os.environ["KDBAI_ENDPOINT"]
if "KDBAI_ENDPOINT" in os.environ
else input("KDB.AI endpoint: ")
)
KDBAI_API_KEY = (
os.environ["KDBAI_API_KEY"]
if "KDBAI_API_KEY" in os.environ
else getpass("KDB.AI API key: ")
)
### Start Session with KDB.AI Cloud
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
# ensure no database called "myDatabase" exists
try:
session.database("myDatabase").drop()
except kdbai.KDBAIException:
pass
# Create the database
db = session.create_database("myDatabase")
6: Create the schema, indexes, and KDB.AI table.
The schema will contain each column within the dataframe defined above (ID, chunk, sparse, and dense). We also define two indexes, one for dense search and one for sparse search (bm25).
- dense_index: uses a flat index type, with 384 dims, and Euclidean Distance search metric
- sparse_index: uses bm25 search type. We also define the “b” and “k” parameters. These parameters can be adjusted at runtime, enabling the hyperparameter tuning for term saturation and document length impact on relevance
# Define the schema
schema = [
{"name": "ID", "type": "str"},
{"name": "chunk", "type": "str"},
{
"name":"sparse",
"type":"general",
},
{
"name":"dense",
"type":"float64s",
},
]
# Define the index
indexes = [
{
'type': 'flat',
'name': 'dense_index',
'column': 'dense',
'params': {'dims': 384, 'metric': "L2"},
},
{
'type': 'bm25',
'name': 'sparse_index',
'column': 'sparse',
'params': {'k': 1.25, 'b': 0.75},
},
]
# First ensure the table does not already exist
try:
db.table("inflation").drop()
except kdbai.KDBAIException:
pass
# Create the table with the defined schema and indexes from above
table = db.create_table(table="inflation", schema=schema, indexes=indexes)7: Insert the dataframe into the KDB.AI table.
### Insert the dataframe into the KDB.AI table
table.insert(df)8: Create sparse and dense query vectors.
Since we have two indexes (sparse and dense), we also need sparse and dense vectors for the query.
query = '12-month basis'
### Create the dense query vector
dense_query = [embedding_model.encode(query).tolist()]
### Create the sparse query vector
sparse_query = [dict(Counter(y)) for y in token([query], padding=True,max_length=None)['input_ids']]
sparse_query[0].pop(101);sparse_query[0].pop(102);
9: Perform a dense search.
Now, we are ready for retrieval! Let’s first run a dense search independently.
### Type 1 - dense search
table.search(vectors={"dense_index":dense_query}, n=5)[0][['ID','chunk']]

Dense search results
10: Perform a sparse search
### Type 2 - sparse search
table.search(vectors={"sparse_index":sparse_query}, n=5)[0][['ID','chunk']]

Sparse search results
Comparing the sparse and dense search results based on the “12-month basis” query, we see that while both return relevant results, the sparse search returns several chunks that contain specific references to the “12-month basis”. This highlights the advantage of sparse search when interested in specific terms.
Now, let’s run a hybrid (multi-index) search to combine the strengths of sparse and dense searches. In the index parameters, you can adjust the weights of each search to fit your use case.
### Hybrid Search
table.search(
vectors={"sparse_index": sparse_query,"dense_index": dense_query},
index_params={"sparse_index":{'weight':0.5} ,"dense_index":{'weight':0.5}},
n=5
)[0][['ID','chunk']]

Hybrid search results
The results from this hybrid search retrieval can now be sent to the LLM of your choice to complete the RAG pipeline.
Multimodal Search
The ability to define multiple indexes in a single table is excellent for use cases involving multiple modalities such as images and text. We will leverage OpenAI’s CLIP model to generate embeddings for both images of animals and their text descriptions. The image embeddings will be stored in one index, while the text embeddings will be stored in a second index.
An example image:

The corresponding text description: “Bat with outstretched wings hovering over an apple on a leafy branch”
1: Let’s explore the code.
!pip install kdbai_client
# For CPU-only
!pip install torch torchvision
!pip install git+https://github.com/openai/CLIP.git
import clip
import torch
import kdbai_client as kdbai
2: Download images and text descriptions.
import os
import requests
import io
from PIL import Image
!mkdir -p ./data
def get_github_repo_contents(repo_owner, repo_name, branch, folder_path):
# Construct the API URL
api_url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/contents/{folder_path}?ref={branch}"
# Send the request and process the response
contents = requests.get(api_url).json()
# Create the local directory if it doesn't exist
fPath = f"./{folder_path.split('/')[-1]}"
for item in contents:
# Recursively list contents of subfolder
if item['type'] == 'dir':
get_github_repo_contents(repo_owner, repo_name, branch, f"{folder_path}/{item['name']}")
# Download and save file
elif item['type'] == 'file':
file_url = f"https://raw.githubusercontent.com/{repo_owner}/{repo_name}/{branch}/{folder_path}/{item['name']}"
print(file_url)
r = requests.get(file_url, timeout=4.0)
r.raise_for_status() # Raises an exception for HTTP errors
file_path = f"{fPath}/{item['name']}"
if item['name'].lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
# Save image file
with Image.open(io.BytesIO(r.content)) as im:
im.save(file_path)
else:
# Save text file
with open(file_path, 'wb') as f:
f.write(r.content)
# Get images and texts
get_github_repo_contents(
repo_owner='KxSystems',
repo_name='kdbai-samples',
branch='main',
folder_path='multi_index_multimodal_search/data'
)3: Use CLIP to generate multimodal embeddings for the images and text.
def load_clip_model():
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
return model, preprocess, device
def generate_image_embedding(model, preprocess, image_path, device):
image = preprocess(Image.open(image_path)).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
return image_features.cpu().numpy()
def generate_text_embedding(model, text, device):
text_tokens = clip.tokenize([text]).to(device)
with torch.no_grad():
text_features = model.encode_text(text_tokens)
return text_features.cpu().numpy()
def read_text_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return file.read().strip()
def process_images_and_descriptions(data_dir):
model, preprocess, device = load_clip_model()
data = []
# First, collect all image files
image_files = [f for f in os.listdir(data_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif'))]
for image_file in image_files:
image_path = os.path.join(data_dir, image_file)
text_file = os.path.splitext(image_file)[0] + '.txt'
text_path = os.path.join(data_dir, text_file)
image_embedding = generate_image_embedding(model, preprocess, image_path, device)
if os.path.exists(text_path):
text = read_text_file(text_path)
text_embedding = generate_text_embedding(model, text, device)
else:
text = None
text_embedding = None
data.append({
'image_path': image_path,
'text_path': text_path if os.path.exists(text_path) else None,
'text': text,
'image_embedding': image_embedding.flatten(),
'text_embedding': text_embedding.flatten() if text_embedding is not None else None
})
# Create DataFrame
df = pd.DataFrame(data)
return df
# Example usage
data_dir = "./data"
result_df = process_images_and_descriptions(data_dir)
# Display the first few rows of the DataFrame
print(result_df.head())4: Connect to KDB.AI.
from getpass import getpass
KDBAI_ENDPOINT = (
os.environ["KDBAI_ENDPOINT"]
if "KDBAI_ENDPOINT" in os.environ
else input("KDB.AI endpoint: ")
)
KDBAI_API_KEY = (
os.environ["KDBAI_API_KEY"]
if "KDBAI_API_KEY" in os.environ
else getpass("KDB.AI API key: ")
)
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
5: Define the schema and indexes for the KDB.AI table.
We create a column in the schema for each column in the above data frame. We will also create two indexes, as there are two embeddings (image and text).
In this case, we will use the qFlat index (On-disk index = extremely low memory footprint), but you can choose whatever index suits your particular use case. We also select distance Euclidean (L2) for the search metric and specify the dimensions of our CLIP-generated embeddings (512).
#Set up the schema and indexes for KDB.AI table
schema = [
{"name": "image_path", "type": "str"},
{"name": "text_path", "type": "str"},
{"name": "text", "type": "str"},
{"name": "image_embedding", "type": "float32s"},
{"name": "text_embedding", "type": "float32s"}
]
indexes = [
{
"name": "image_index_qFlat",
"type": "qFlat",
"column": "image_embedding",
"params": {"dims": 512, "metric": "L2"},
},
{
"name": "text_index_qFlat",
"type": "qFlat",
"column": "text_embedding",
"params": {"dims": 512, "metric": "L2"},
},
]6: Create the table and insert the dataframe.
# get the database connection. Default database name is 'default'
database = session.database('default')
# First ensure the table does not already exist
try:
database.table("multi_index_search").drop()
except kdbai.KDBAIException:
pass
table = database.create_table("multi_index_search", schema, indexes=indexes)
# Insert the data
table.insert(result_df)7: Execute a multi-index multimodal search.
from IPython.display import display
# Helper functions to embed the user's query and view results
def embed_query(text):
model, preprocess, device = load_clip_model()
# Tokenize the text
text_tokens = clip.tokenize([text]).to(device)
# Generate the embedding
with torch.no_grad():
text_features = model.encode_text(text_tokens)
# Convert to numpy array and return
return text_features.cpu().numpy()
def view_results(results):
for index, row in results.iterrows():
display(Image.open(row.iloc[1]))
print(row.iloc[3])query = 'what are the purpose of antlers?'
query_vector = embed_query(query)
# Multi-Index Search for both texts and images
results = table.search(
vectors={"text_index_qFlat":query_vector, "image_index_qFlat":query_vector},
index_params={"text_index_qFlat":{'weight':0.5} ,"image_index_qFlat":{'weight':0.5}},
n=2
)[0]
view_results(results)

Side view of buck deer with large antlers in forest setting

Buck deer with antlers standing in misty grassland
Let’s try another example:
query = 'flying animal that eats bugs and fruit and hangs upsidedown'
query_vector = embed_query(query)
# Multi-Index Search for both texts and images
results = table.search(
vectors={"text_index_qFlat":query_vector, "image_index_qFlat":query_vector},
index_params={"text_index_qFlat":{'weight':0.5} ,"image_index_qFlat":{'weight':0.5}},
n=2
)[0]
view_results(results)
Bat with outstretched wings hovering over an apple on leafy branch

A bat hanging upside down from a metal bar in an urban setting
Multi-index retrieval is a game-changer for optimizing RAG pipelines, combining flexibility, precision, and scalability. Whether you’re enhancing search with hybrid approaches or diving into multimodal RAG, KDB.AI makes implementing and experimenting with these advanced techniques seamless.
Get started today with KDB.AI — it’s packed with resources to help you unlock the full potential of RAG.


