
Key Takeaways
- Learn how to build RAG pipelines for complex files
- Learn how to transform complex datatypes into markdown
- Learn how to ingest into KDB.AI for efficient retrieval
Retrieval augmented generation (RAG) has long been used to connect data of interest to large language models (LLMs), enabling question-answering and insights based on specific datasets. A common challenge, however, is that important semi-structured data is often stored in complex file types such as PDFs, meaning developers must investigate solutions that can extract this information cleanly and efficiently.
In this blog, I will demonstrate how developers can overcome these challenges and build an advanced PDF parsing solution with KDB.AI and LlamaParse.
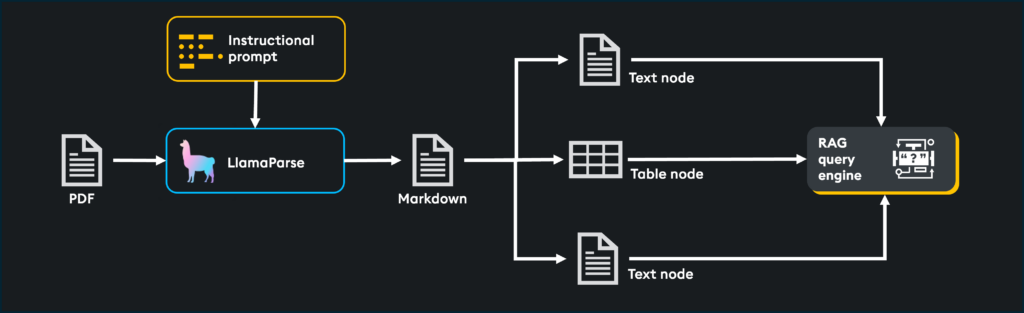
LlamaParse enables the creation of retrieval systems for complex documents. It does so by extracting data from documents and transforming it into easily ingestible formats such as markdown or text. Once transformed, data can be embedded and loaded into a RAG pipeline.
- Supported file types: PDF, .pptx, .docx, .rtf, .pages, .epub, etc
- Transformed output type: Markdown, text
- Extraction capabilities: Text, tables, images, graphs, comic books, mathematics equations
- Customized parsing instructions: Since LlamaParse is LLM enabled, you can pass it instructions as if you were prompting an LLM. This could be used to describe the document, define the output, or preprocess with sentiment analysis, language translation, summarization
- JSON mode: This mode outputs the complete structure of the document, extracts images with size and location metadata, and extracts tables in JSON format for easy analysis. It is perfect for custom RAG applications in which document structure and metadata are used to maximize informational value and cite where document-retrieved nodes originate
Markdown specifies the inherent structure of the document by identifying elements such as titles, headers, subsections, tables, and images. This may seem trivial, but since markdown identifies these elements, we can easily split a document into smaller chunks using specialized parsers such as the MarkdownElementNodeParser().
Guided walkthrough
In the following steps, we will build and test a simple RAG pipeline that ingests PDF files with LlamaParse. If you would like to follow along, sign up for a free trial of KDB.AI. You can also explore the code on GitHub or Colab.
Step 1: Install and import libraries:
We will begin by installing and importing libraries from Llamaindex, Pandas, OpenAI, and KDB.AI.
Install & Import libraries:
!pip install llama-index
!pip install llama-index-core
!pip install llama-index-embeddings-openai
!pip install llama-parse
!pip install llama-index-vector-stores-kdbai
!pip install pandas
!pip install llama-index-postprocessor-cohere-rerank
!pip install kdbai_client
from llama_parse import LlamaParse
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core import VectorStoreIndex
from llama_index.core.node_parser import MarkdownElementNodeParser
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.vector_stores.kdbai import KDBAIVectorStore
from getpass import getpass
import kdbai_client as kdbaiStep 2: Set up API keys for LlamaCloud, OpenAI:
Next, we will configure our API keys.
For help securing your own API key, please refer to the following documentation:
# llama-parse is async-first, running the async code in a notebook requires the use of nest_asyncio
import nest_asyncio
nest_asyncio.apply()
import os
# API access to llama-cloud
os.environ["LLAMA_CLOUD_API_KEY"] = "llx-"
# Using OpenAI API for embeddings/llms
os.environ["OPENAI_API_KEY"] = "sk-"Step 3: Set up KDB.AI
Now, we will set up and configure KDB.AI, a multi-modal vector database that enables scalable, real-time AI applications with advanced capabilities such as search, personalization, and RAG. It integrates temporal and semantic relevance into workflows, helping developers support high-performance, time-based, multi-modal data queries for enterprise workloads.
In the code below, we will connect to the default database, create a schema, define the index, and then create a table.
#Set up KDB.AI endpoing and API key
KDBAI_ENDPOINT = (
os.environ["KDBAI_ENDPOINT"]
if "KDBAI_ENDPOINT" in os.environ
else input("KDB.AI endpoint: ")
)
KDBAI_API_KEY = (
os.environ["KDBAI_API_KEY"]
if "KDBAI_API_KEY" in os.environ
else getpass("KDB.AI API key: ")
)
#connect to KDB.AI
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)
Connect to the ‘default’ database, create a schema for the KDB.AI table, define the index, and create the table:
# Connect with kdbai database
db = session.database("default")
# The schema contains two metadata columns (document_id, text) and one embeddings column
schema = [
dict(name="document_id", type="str"),
dict(name="text", type="str"),
dict(name="embeddings", type="float32s"),
]
# indexflat, define the index name, type, column to apply the index to (embeddings)
# and params which include thesearch metric (Euclidean distance), and dims
indexFlat = {
"name": "flat",
"type": "flat",
"column": "embeddings",
"params": {'dims': 1536, 'metric': 'L2'},
}
KDBAI_TABLE_NAME = "LlamaParse_Table"
# First ensure the table does not already exist
try:
db.table(KDBAI_TABLE_NAME).drop()
except kdbai.KDBAIException:
pass
#Create the table
table = db.create_table(KDBAI_TABLE_NAME, schema, indexes=[indexFlat])Step 4: Download a PDF:
Next, we will download and import a sample PDF file, in this instance ‘LLM In-Context Recall is Prompt Dependent, ’ by Daniel Machlab and Rick Battle.
!wget 'https://arxiv.org/pdf/2404.08865' -O './LLM_recall.pdf'Step 5: Set up LlamaParse, LlamaIndex, & embedding model:
From here, we can define the model type, generation, and settings parameters, specifying the path to our PDF.
EMBEDDING_MODEL = "text-embedding-3-small"
GENERATION_MODEL = "gpt-4o"
llm = OpenAI(model=GENERATION_MODEL)
embed_model = OpenAIEmbedding(model=EMBEDDING_MODEL)
Settings.llm = llm
Settings.embed_model = embed_model
pdf_file_name = './LLM_recall.pdf'
Step 6: Create custom parsing instructions:
Next, we will add the following instructions to our solution.
The document titled “LLM In-Context Recall is Prompt Dependent” is an academic preprint from April 2024, authored by Daniel Machlab and Rick Battle from the VMware NLP Lab. It explores the in-context recall capabilities of Large Language Models (LLMs) using a method called “needle-in-a-haystack,” where a specific factoid is embedded in a block of unrelated text. The study investigates how the recall performance of various LLMs is influenced by the content of prompts and the biases in their training data. The research involves testing multiple LLMs with varying context window sizes to assess their ability to recall information accurately when prompted differently. The paper includes detailed methodologies, results from numerous tests, discussions on the impact of prompt variations and training data, and conclusions on improving LLM utility in practical applications. It contains many tables. Answer questions using the information in this article and be precise.
parsing_instructions = '''The document titled "LLM In-Context Recall is Prompt Dependent" is an academic preprint from April 2024, authored by Daniel Machlab and Rick Battle from the VMware NLP Lab. It explores the in-context recall capabilities of Large Language Models (LLMs) using a method called "needle-in-a-haystack," where a specific factoid is embedded in a block of unrelated text. The study investigates how the recall performance of various LLMs is influenced by the content of prompts and the biases in their training data. The research involves testing multiple LLMs with varying context window sizes to assess their ability to recall information accurately when prompted differently. The paper includes detailed methodologies, results from numerous tests, discussions on the impact of prompt variations and training data, and conclusions on improving LLM utility in practical applications. It contains many tables. Answer questions using the information in this article and be precise.'''Step 7: Run LlamaParse and extract text & tables from markdown:
Next, we will parse the document, retrieve nodes (text) and objects (table), and insert markdown into the text of each table before creating an index in KDB.AI and testing insertion.
documents = LlamaParse(result_type="markdown", parsing_instructions=parsing_instructions).load_data(pdf_file_name)
print(documents[0].text[:1000])
# Parse the documents using MarkdownElementNodeParser
node_parser = MarkdownElementNodeParser(llm=llm, num_workers=8).from_defaults()
# Retrieve nodes (text) and objects (table)
nodes = node_parser.get_nodes_from_documents(documents)
base_nodes, objects = node_parser.get_nodes_and_objects(nodes)
# insert the table markdown into the text of each table object
for i in range(len(objects)):
objects[i].text = objects[i].obj.text[:]
vector_store = KDBAIVectorStore(table)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
#Create the index, inserts base_nodes and objects into KDB.AI
recursive_index = VectorStoreIndex(
nodes= base_nodes + objects, storage_context=storage_context
)
# Query KDB.AI to ensure the nodes were inserted
table.query()Step 8: Helper functions to complete the RAG pipeline:
We will now define the following helper functions:
- embed_query: Takes a user query and embeds it using OpenAI’s ‘text-embedding-3-small’
- retrieve_data: Takes the query, calls the embed_query function to get the query embedding, then executes retrieval on KDB.AI to retrieve the most relevant nodes
- RAG: Takes in the query, calls the retrieve_data function, and then passes the retrieved data to OpenAI’s GPT-4o LLM
from openai import OpenAI
client = OpenAI()
def embed_query(query):
query_embedding = client.embeddings.create(
input=query,
model="text-embedding-3-small"
)
return query_embedding.data[0].embedding
def retrieve_data(query):
query_embedding = embed_query(query)
results = table.search(vectors={'flat':[query_embedding]},n=5,filter=[('<>','document_id','4a9551df-5dec-4410-90bb-43d17d722918')])
retrieved_data_for_RAG = []
for index, row in results[0].iterrows():
retrieved_data_for_RAG.append(row['text'])
return retrieved_data_for_RAG
def RAG(query):
question = "You will answer this question based on the provided reference material: " + query
messages = "Here is the provided context: " + "\n"
results = retrieve_data(query)
if results:
for data in results:
messages += data + "\n"
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": question},
{
"role": "user",
"content": [
{"type": "text", "text": messages},
],
}
],
max_tokens=300,
)
content = response.choices[0].message.content
return contentTest the solution
With our model built, we can test and highlight how our LLM can retrieve content from the ingested PDF.
print(RAG("describe the needle in a haystack method only using the provided information"))>>>The needle-in-a-haystack method involves embedding a factoid (referred to as the “needle”) within a block of filler text (referred to as the “haystack”). The model is then tasked with retrieving this embedded factoid. The recall performance of the model is evaluated across various haystack lengths and with different placements of the needle to identify patterns in performance. This method demonstrates that an LLM’s ability to recall information is influenced not only by the content of the prompt but also by potential biases in its training data. Adjustments to the model’s architecture, training strategy, or fine-tuning can enhance its recall performance, providing insights into LLM behavior for more effective applications.
print(RAG("list the AI models that are evaluated with needle-in-a-haystack testing?"))>>>Llama 2 13B, Llama 2 70B, GPT-4 Turbo, GPT-3.5 Turbo 1106, GPT-3.5 Turbo 0125, Mistral v0.1, Mistral v0.2, WizardLM, and Mixtral are the LLMs evaluated with needle-in-a-haystack testing. (Taken from a table within the PDF document)
| Model Name | Context Window Size |
| Llama 2 13B Chat Llama 2 70B Chat WizardLM 70B GPT-3.5-Turbo-1106 GPT-3.5-Turbo-0125 Minstral 7B Instruct v0.1 Minstral 7B Instruct v0.2 Minstral 8x7B Instruct v0.1 GPT-4 Turbo 0125 |
4,096 Tokens 4,096 Tokens 4,096 Tokens 16,385 Tokens 16,385 Tokens 32,768 Tokens 32,768 Tokens 32,768 Tokens 128,000 Tokens |
print(RAG("what is the best thing to do in San Francisco?"))>>>The best thing to do in San Francisco is to eat a sandwich and sit in Dolores Park on a sunny day. (Taken from a table within the PDF document)
| Test Name | Factoid | Question |
| PistachioAI | PistachioAI received a patent before its Series A | What did PistachioAI receive before its Series A? |
| San Francisco | The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day. | What is the best thing to do in San Francisco? |
| Thornfield Hollow | The best thing to do in Thornfield Hollow is eat a sandwich and sit in Harmony Glen Nature Preserve on a sunny day. | What is the best thing to do in Thornfield Hollow? |
In this blog, we explored building a retrieval-augmented generation pipeline for a complex PDF document. We used LlamaParse to transform the PDF into markdown format, extracted both text and tables, and then ingested the content into KDB.AI for retrieval.
If you enjoyed this blog, why not check out my others or try some of our other sample notebooks from the KDB.AI learning hub:


