

By Andrew Morrison, Senior Software Engineer at KX and Nathan Crone, Data Scientist at KX.
At a recent meetup in Belfast we had an opportunity to introduce PyKX and demonstrate it in a common financial services use case. In particular, we showed how a Python TCA (Transaction Cost Analysis) workflow can be accelerated by the power of kdb and consume fewer operational resources. In a world where Python is the programming language of choice for most developers and data scientists, it enables them to continue to use those existing skills and libraries while significantly benefiting from the performance enhancement and resource efficiency of kdb.
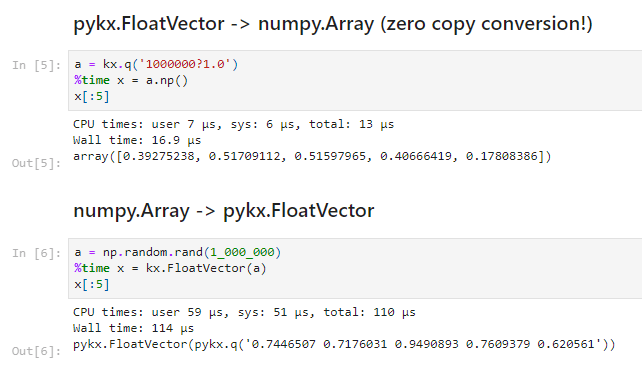
We first showed how easy it is to install PyKX and begin programming immediately with Python – and/or indeed q, if desired. By sharing the memory space between Python and q, data can transfer swiftly between them, often at zero copy. This was illustrated by transferring one million q floats to NumPy in what is effectively a constant time operation – and similarly, in reverse, from NumPy to q.
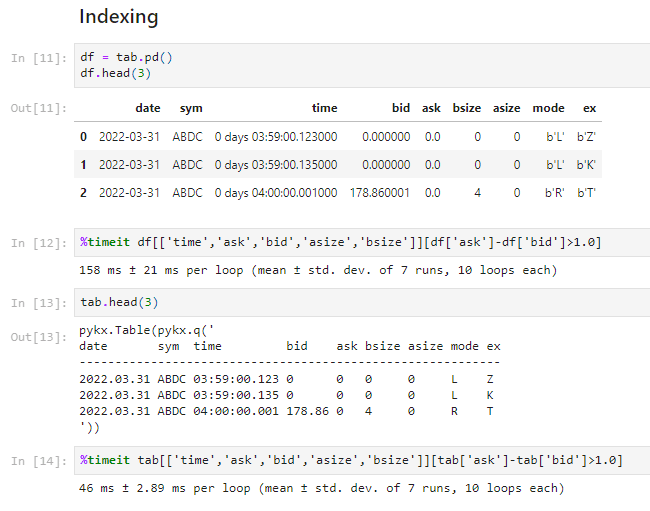
We then showed how developers can interact with PyKX tables. As well as supporting ANSI SQL and an API for qSQL, there is a Pandas API, allowing users to reference the metadata similarly to how they would in Pandas, but also index into the PyKX data using in the same syntax. Moreover, they do it faster as illustrated below, where the same query taking 158 milliseconds when operating on a standard Pandas dataframe took just 46 milliseconds on a PyKX table.
Next we showed how PyKX functionality can be applied to a typical TCA use case required by brokers to ensure regulatory compliance and quantify trade efficiency. To illustrate ease of use and compare execution time we showed how three separate datasets of quotes (9 million), market trades (900K) and broker trades (20K) used in the calculation could be read into Panda dataframes and PyKX tables.
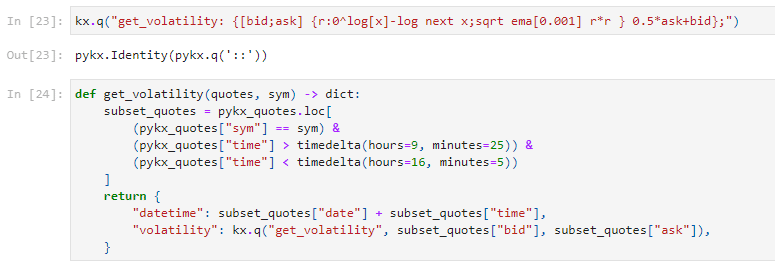
The next step was to quantify slippage, the difference between the execution price and a chosen benchmark, considering the bid-ask spread, its volatility and market impact. For volatility specifically, we re-used an already existing q function within PyKX as below.
We then combined native Python functions with the qSQL API to derive the bid-ask spread. In this case, a moving average calculation was used and the simple step to incorporate this function into PyKX was shown below.


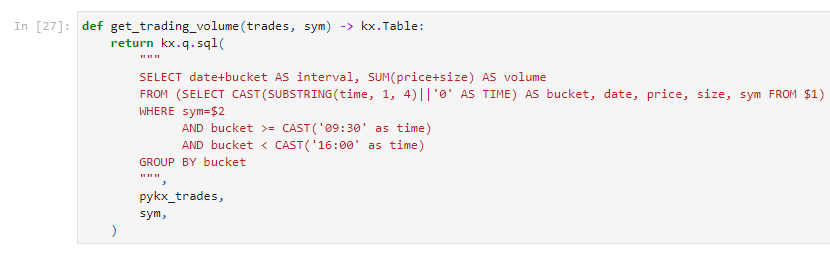
To quantify liquidity we applied a standard SQL query to calculate trading volume of 10-minute intervals during the trading day using PyKX’s SQL API.
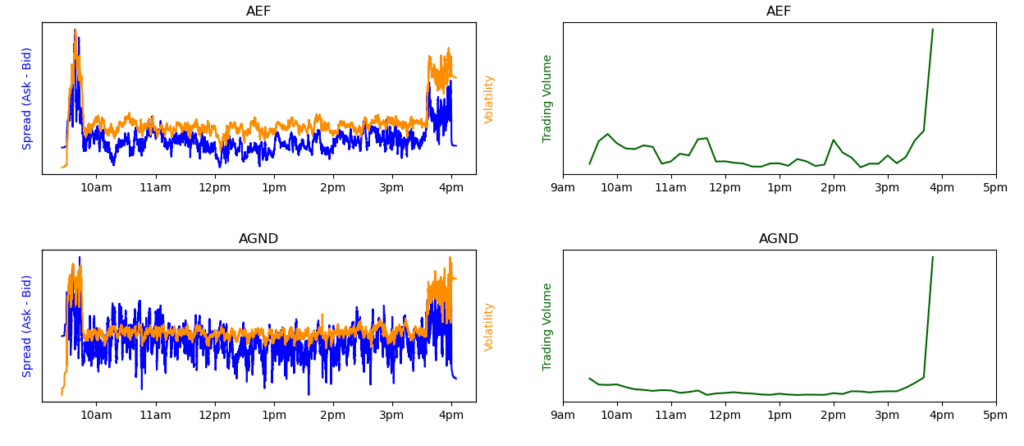
We then showed how these measures could be visualised. The graphs on the left-hand side below show the heightened volatility at start and end of day and how, as the volatility increases, so too does the spread, while the right-hand plots show the corresponding increase in trading volume at the opening and close of the market – both patterns reflecting standard market behaviour.
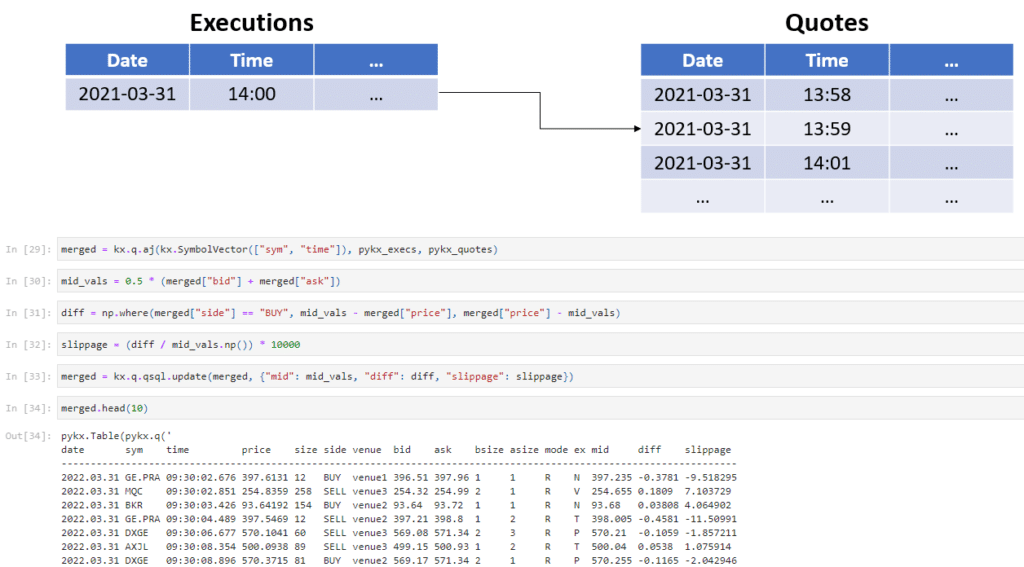
Having run these calculations and better understood the makeup of this slippage factor and the times when it may become elevated, we then made use of the asof join function in q to join the quotes and executions tables together. This merged table would allow us to accurately calculate and plot the slippage factor over time and across different venues
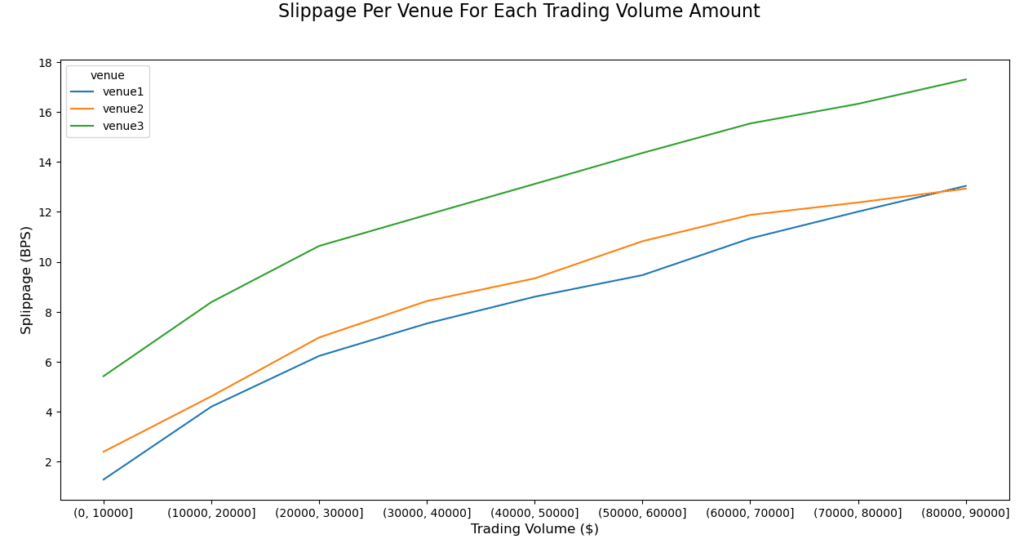
By graphing the results, venue 1 was quickly shown to have higher slippage than the other two venues, a useful insight.
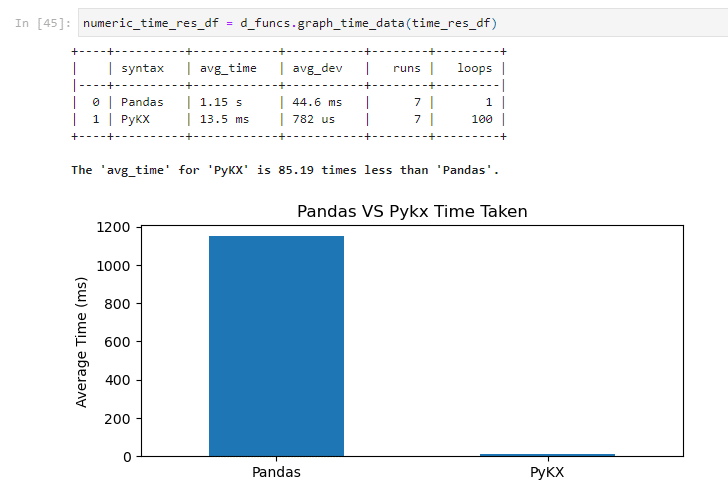
Next, we compared execution times and resource usage in processing the files and performing the calculations. On performance showed an 85x improvement in using PyKX over Pandas directly (1150/13.5 milliseconds)
We then compared the memory usage.
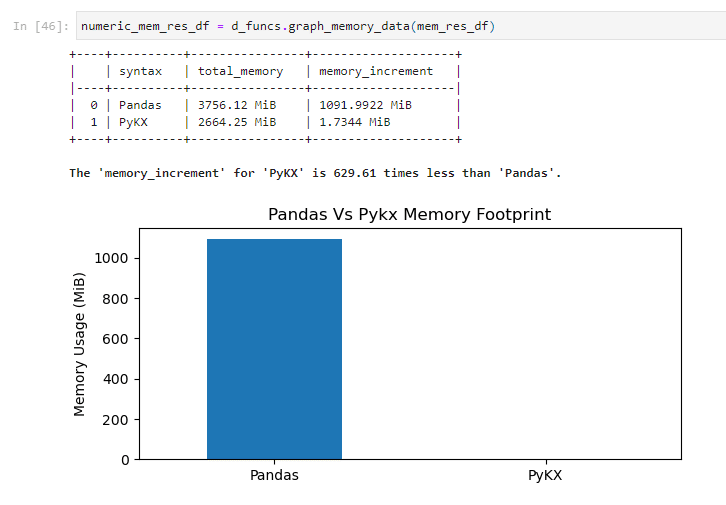
In summary, by providing Python users with access to the optimised processing functions of q, but without necessarily having to learn to language itself, PyKX enables significant improvement in speed of processing and reduction in memory resources. It is now available on PyPI, installation is a simple “pip install pykx” – just follow this helpful guide for getting started.
Click here to watch the presentation in full and for more information, or visit this link on the KX Academy for more detail and to run the notebook yourself.
Andrew Morrison is a Senior Software Engineer and Nathan Crone