

Developer

Download my latest ebook, and learn the secrets of cutting-edge re-ranking techniques for advanced search.
Key Takeaways
- Add evals early so you can track real progress.
- Use hybrid search to catch both semantic and exact matches.
- Don’t over-optimize advanced RAG or chunking without data to back it up.
- Quantize to keep memory and bills in check.
- Use on-disk indexes if you’re going big, memory is costly.
- Fine-tune embeddings or re-rankers if domain specificity matters.
- Adopt a full vector DB rather than a barebones library.
- Look at your data — and don’t be afraid to manually fix chunk issues.
Vector search looks easy on paper; chuck some embeddings into a database, query them, and get results. But once you leap from hobby projects to real-world apps, you quickly find that ‘magic’ turns into a minefield of exploding cloud bills, hallucinations, and searches that miss the mark entirely. In this blog, I’ll share eight common pitfalls when scaling vector search and give you practical strategies to mitigate these pitfalls, helping you save time, money, and stress.
Pitfall 1: You don’t have a proper evaluation framework.
Establishing a vector search without a proper evaluation framework can lead to inconsistent query performance and a lack of understanding of the underlying issues.
What to do instead:
- Create a small, reliable eval set: Even 50–100 labeled queries are enough to reveal issues
- Use standard metrics: NDCG, MRR, recall, etc. Start with something, then refine it
- Monitor improvements: Rerun the eval each time you tweak chunking or switch embeddings
Many teams focus on advanced chunking techniques, “contextual retrieval,” or even knowledge graphs but have no idea if those changes help. The bottom line is that an evaluation framework removes the guesswork.
Pitfall 2: You ignore hybrid search.
Relying solely on embedding similarity can overlook obvious keyword matches. If your embeddings are not domain-specific or a user queries an uncommon term, the system might fail to recognize it. Conversely, a standard keyword search (such as BM25) would have identified it.
What to do instead:
- Combine embeddings + keyword search: “Hybrid search” merges vector-based and keyword-based results
- Boost recall: This approach is easy to implement in many vector DBs (e.g., KDB.AI can store BM25 and vector indexes in the same table)
- Re-rank the union: Return the top results from both methods and let your re-ranker decide
It’s increasingly common to see teams adopt an embeddings-only model. However, combining with keyword search can massively improve vector search recall without sacrificing latency. Here’s how it may look.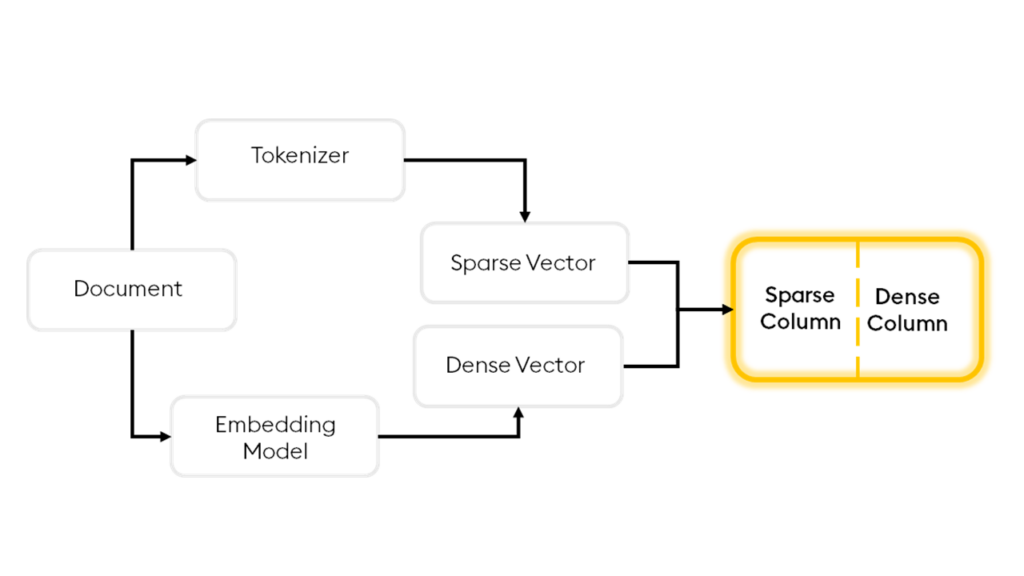
Pitfall 3: You over-optimize.
Adopting a new retrieval technique before establishing a clear baseline is tempting, but if you can’t measure impact, you won’t know if it’s working.
What to do instead:
- Set a baseline: A great place to start is often a hybrid search + a small re-ranker
- Measure: Evaluate it on your labeled set
- Introduce changes gradually: See if performance improves with any implemented changes
If your pipeline is very complex, you may be better off building a simple RAG pipeline from scratch. Remember, even simple techniques like late-chunking, which can often improve performance with little work, can potentially reduce the quality of your results.
The bottom line is always to measure and simplify when in doubt.
You can learn more about late chunking and contextual retrieval by downloading my latest ebook.
Pitfall 4: You don’t quantize your embeddings.
3k-dimensional embeddings can work great until you have tens of millions of them. Then, you’re drowning in escalated costs and performance degradation.
What to do Instead:
- Use quantization: Techniques like Matryoshka Representation Learning (MRL) or binary quantization can reduce embeddings with minimal loss
- Try 64D or 128D: Especially if you have over 2–3M vectors. You might barely notice any drop in recall, but you’ll definitely see a drop in cost
- Lean on re-ranking: The first retrieval step can be “good enough” if you re-rank the top N results with a more accurate method
- Consider binary quantization: Binary quantization often mixes well with other techniques like MRL, but make sure your model works well with it!
I’ve chatted with developers paying $100+ a month for a serverless DB that only had 1M vectors at 1536 dims. I’ve also spoken to engineers who believe they “need” 3000 dimensions for a good search on their PDFs. I promise you, you do not. Switching to 64D or 128D cuts storage and CPU usage so much that it effectively becomes free. If you use binary quantization on top of that, you can reduce the space used up by your embeddings by an additional 32x.
Pitfall 5: You fail to use on-disk indexes at a larger scale.
Once you hit 5–10+ million vectors, storing them all in RAM is often too expensive.
What to do instead:
- On-disk indexing: Indexes like qHNSW in KDB.AI let you store vectors on disk, drastically cutting memory usage
- Check your scale: If you are heading toward 50 million or 100 million vectors, plan for an on-disk solution
- Watch your latency: Modern on-disk indexes are surprisingly fast, so you might barely notice the difference. For example, KDB.AI’s qHNSW index achieves 3x higher throughput than the default HNSW index while keeping latency roughly the same
Pitfall 6: You skip fine-tuning.
Off-the-shelf embeddings (e.g., from OpenAI, Cohere) are great for general queries but might miss domain-specific nuances like medical terms, chemical compounds, or specialized brand references.
What to do instead:
- Fine-tune embeddings: Even 1,000 labeled pairs can make a difference
- Fine-tune re-rankers: Cross-encoders or other re-rankers often need fewer examples than you’d think. Even a few hundred pairs can make a difference, but the more, the better
- Use your eval set: Test before you train, then after. Track how much fine-tuning helps
15–25% improvements in recall are not uncommon with just a small set of domain-specific training samples. If domain matters, ignoring fine-tuning is leaving accuracy on the table.
You can learn more about re-ranking by reading my ebook: The ultimate guide to re-ranking.
Pitfall 7: You confuse vector search with a vector database.
It’s easy to download Faiss or Annoy, configure an approximate nearest neighbor search, and then call it a day. However, production databases such as KDB.AI can do much more than raw vector lookups; they can perform hybrid search, concurrency, metadata filtering, partitioning, and more. In fact, most in-memory vector libraries don’t even support searching while adding new data.
What to do instead:
- Pick a vector database: Solutions like KDB.AI are built from the ground up to solve database-level problems like transactions, scaling, and advanced querying
- Make sure hybrid search is an option: Hybrid search is now the standard for text retrieval and is vital for real-world use cases
- Metadata filtering: Real queries typically say, “Find me all documents near this vector but also created in the last 7 days.” Make sure your DB can do that. KDB.AI also supports partitioning on metadata, so if your data is related to time, you can massively reduce latency!
Rebuilding your index from scratch each time your data changes isn’t fun, yet that’s what you face if you rely only on a raw Faiss index.
You can learn more about these features by signing up for a free trial of KDB.AI.
Pitfall 8: You’re afraid to edit your data.
So many teams treat their chunks or embeddings as a black box, “it’s just the AI’s job to figure it out.” Then, wonder why certain queries fail or produce nonsense.
What to do instead:
- Inspect your chunks: Look at how text is split. Are you cutting sentences in half? Did a keyphrase get truncated?
- Manually fix trouble spots: If a chunk is underperforming, don’t be afraid to add a keyword or refine its description. If a user query doesn’t return what it should, maybe you need to tweak the chunk’s text manually
- Iterate on real feedback: If a query is popular but fails, update so the chunk surfaces the right keywords. Sometimes, the easiest fix is a minor tweak in the raw data
Vector search can supercharge semantic queries but also introduce significant pitfalls. Whether you’re building a recommendation system on 1 million vectors or scaling to 100 million for a big enterprise knowledge base, addressing the above will ensure that it consistently delivers relevant results.
If you enjoyed reading this, why not check out some of my other blogs and KDB.AI examples:
You can also visit the KX Learning Hub to begin your certification journey.
Download my latest ebook, and learn the secrets of cutting-edge re-ranking techniques for advanced search.


