

Key Takeaways
- Streaming data enables applications to shift from passive, pull-based interactions to proactive, real-time decision-making.
- Intelligent applications mimic human cognition by automating low-risk decisions (System One) while advising humans on high-impact decisions (System Two).
- Balancing automation and human intervention is crucial, as seen in high-frequency trading, industrial automation, and security systems.
- Streaming data science goes beyond traditional machine learning by continuously analyzing live data to detect anomalies and predict future trends.
- To build real-time applications, developers must leverage time-series data, proactive monitoring, and simulation to anticipate and respond to rapid changes.
Traditional applications rely on users to pull information when they need it, but in an always-on world, that’s not enough. Modern applications harness streaming data to continuously monitor, detect changes, and automate decisions in real-time—powering everything from high-frequency trading to predictive maintenance. Instead of waiting for human input, these applications act proactively, adapting to an ever-changing landscape.
Most applications burden their users: nothing happens unless the human asks a question, then the app answers. Occasionally, a notification is sent, which only places more burden on the user to pull a new set of information. Pull-based human-to-computer interaction is a traditional, old-school way of application design. The pull-based model doesn’t cut it for modern, connected, automated applications: it assumes the world stays stable and predictable and is the wrong way to automate anything.
Apps that automate and intelligently advise human operators using streaming data are designed differently. Like the human nervous system, they automate many low-impact decisions. They intelligently monitor our ever-changing world, spotting instantaneous changes, threats, and opportunities like a canary in a coal mine. They prompt human operators to investigate anomalies. These applications are found on Wall Street, in automated manufacturing facilities, and in apps that deal with drones, connected vehicles, real-time social sentiment, or any fast-moving, flowing, ever-changing data.
To build apps with data in motion, developers must think differently in these five ways:
Rule one: Mimic the decision-making balance of the human brain
Design applications to automate low-impact decisions, continuously assess opportunities and threats and push anomalies to human users. In this way, streaming applications participate in decision-making like the human brain. Psychologist Daniel Kahneman explained in his Nobel prize-winning work Thinking, Fast and Slow.
Kahneman’s System One governs what we do autonomically like a swift hummingbird, darting from flower to flower, acting on intuition without a moment’s pause. System One is in charge as we drive a car, hit a tennis ball, or swat a mosquito when it lands on our neck. It’s fast, subconscious, automatic, and often wrong.
System Two is like a wise old owl. It makes decisions that require experience, judgment, or creativity. It makes decisions slowly, consciously, with effort, and deliberately. System Two decisions are more measured and reliable than System One decisions. System Two decisions are what we make when we think things through.

The first rule of building applications that use streaming data is to design them to mimic and complement how humans make decisions: apps make System 1 decisions on their own and advise human operators on System 2 decisions, as shown below.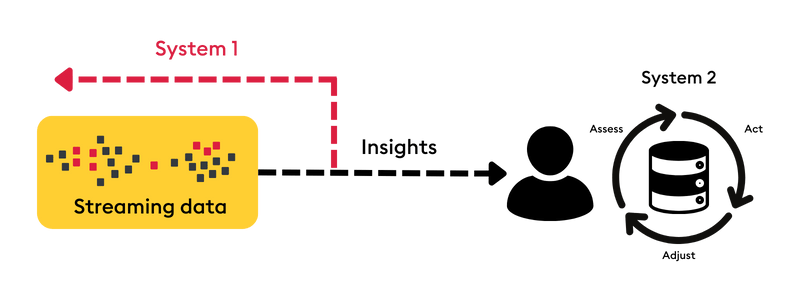
An example of an application that complements is trading on Wall Street, where over 80% of the trading actions taken are automated by System One, and 20% are carefully considered by System Two. Financial market data skips, swings, spikes, and flutters like a hummingbird as prices, news, and trading volumes change moment by moment. Once an order is placed, it’s executed mainly by System One: the right price, partner, and trades are matched, agreed upon, and executed without human intervention in microseconds, billions of times a day. No human “thinking” is needed.
But when the markets are volatile, big news hits and adjustments in trading strategies are on hand, decisions are more measured. Trading software is now in an advisory role, revealing up-to-the-millisecond insights into what competitors are doing, analyzing patterns of momentum and trending, and advising traders on the right call to make.
Modern trading systems are like the hummingbird and the owl; automated trades happen at the speed of a beating wing, and wisdom is required for big decisions, augmented by observations of the now. Analogous systems exist in every industry:
Modern industrial manufacturing machines automate assembly lines and advise human operators when yields aren’t ideal, equipment shows signs of wear, or mistakes are made.
Security systems employ System One to automatically deny access to unauthorized users and System Two to assist human specialists when suspicious patterns are detected.
E-commerce systems process orders automatically but make recommendations to human staff about anticipated low stock and up-to-the-minute buying trends so marketing, buying, or promotional decisions can be optimized.
To design systems that mimic System One and System Two, step back and think about systems that deal with streaming real-time data. Ask yourself: are we automating as many System One decisions as possible? Are we identifying patterns to help power System Two “wise old owl” decisions? What meaningful opportunities are we missing that we could use real-time data to detect and complement each system?
Jot down your answers before exploring rule two.
Rule two: Divide decisions into buckets
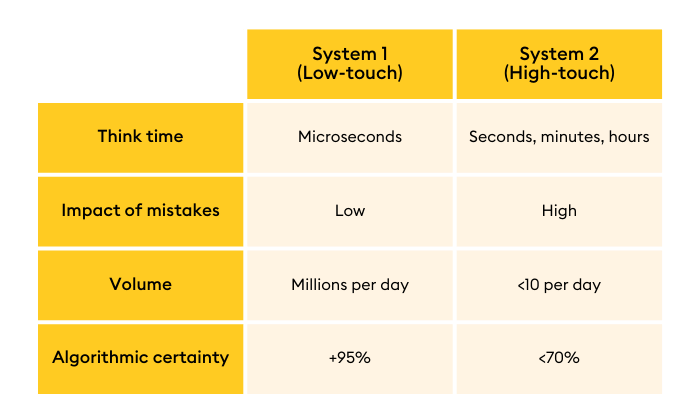
Now that you’re thinking about some apps that “navigate the now,” grab a piece of paper and draw a line down the middle. Label the first column “Low Touch.” Label the other “High Touch.” I learned this terminology from Wall Street traders, and it’s a practical, simple model to frame any high-speed decision-making system.
Low-touch choices require little or no human intervention. They’re System One, hummingbird decisions. On Wall Street, these are small, low-value, low-risk trades made millions or billions of times daily by computers. In an industrial manufacturing environment, low-touch decisions are the autonomic motions of robotic arms. In a security system, low-touch decisions are denial of service. The implications of making a wrong decision are mild.
High-touch decisions are wise old owl decisions that demand and benefit from human creativity and experience. These are portfolio-level decisions in financial services and reactions to news. When a robotic arm shows a sudden pattern of mistakes, it’s a decision that requires an engineer. In a security system, it’s an odd flurry of requests from a suspicious user. The impact of a System Two, high-touch decision can be significant or even existential.
The implications of getting this balance wrong happened in 2012. Knight Capital, a market-maker on Wall Street, lost $440 million in trading in a few hours. The company stock dove by over 70% in two days, emergency funding was arranged to keep it alive, and Knight Capital was acquired less than six months later.
What went wrong? A software glitch caused nearly four hundred million shares to be traded in forty-five minutes. Knight Capital had built for System One decision-making, not System Two. A technical autopsy revealed that a simple trigger to activate human decision-making would have saved investors millions of dollars and saved the company from extinction. Knight Capital app designers didn’t balance System One and System Two thinking.
You can follow rule two by starting with a simple piece of paper: divide decisions into low-touch and high-touch buckets, then design software systems to handle each bucket and balance each carefully.
Rule three: Employ streaming data science to make continuous, proactive predictions
Traditional machine learning and AI train models based on historical data. This approach assumes that the world stays the same — that the patterns, anomalies, and mechanisms observed in the past will happen in the future. So, predictive analytics is looking-to-the-past rather than the future. Apps that must navigate the now apply data science models continuously, detect changes in the state of the world, momentum, trends, and spikes in data, and make proactive recommendations to human operators.
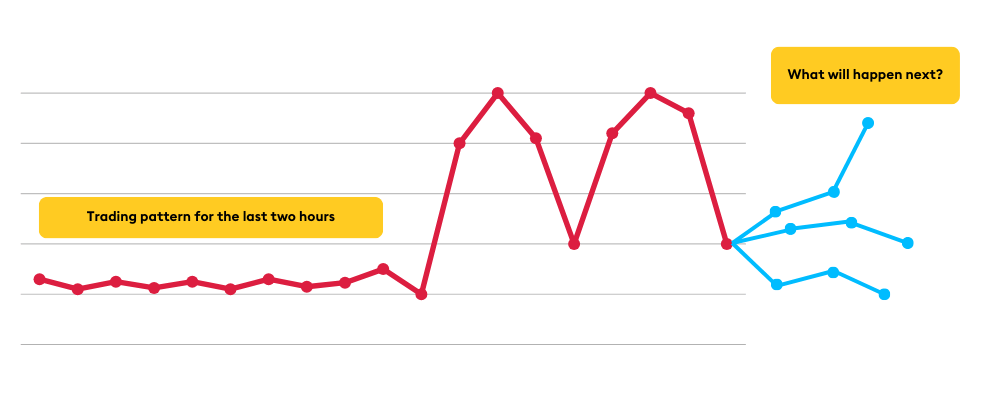
Imagine you’re a trader in the capital markets. You hold a significant position in IBM and it generally fluctuates within its “typical” range according to historical norms. Suddenly, IBM’s price surges outside its normal range, and you get an alert. You watch with great interest as the price drops, but not back to its “expected” price. Then it spikes again, then down, forming the “shape” of an M (see below).
Your portfolio manager calls. “What’s going on?”
”What will happen next?”
Sometimes, volatility is easily explained. Earnings releases, news, or poor performance by a related company are often the underlying cause of market moves.
But usually, there’s more to be understood.
Consider another situation that generates voluminous streaming data in real-time: a Formula One racing team. On race day, humans make the decisions: the driver, race director, and head mechanic. They are the wise old owls. But Formula One teams spend millions on race-day analytics software that empowers teams to make the best decisions based on their knowledge.
But just as critical are the real-time System One analytics applications that silently consume data as the race begins in real-time: lap times of each car, car positions, accidents, sensor readings from the vehicle, and minute-by-minute weather forecast updates. This System One hummingbird uses AI and machine learning models to watch for anomalies and opportunities.
But these applications don’t just make predictions based on history; the most innovative applications make predictions based on up-to-the-moment, real-time data. This is the field of streaming data science.
In contrast to traditional data science, streaming data science evaluates data continuously to make predictions on live data. For example, by assessing trends in sensor data from tires, the weather forecast and correlating that information with lap times, our System One Formula One race advisor can intelligently recommend the optimal time for a pit stop and tire change:
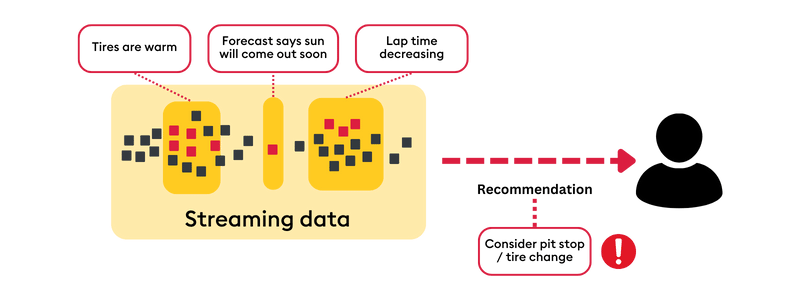
Streaming data science is a technological break from traditional data science, which is generally designed to train on massive amounts of static, historical data. Streaming data employs time series data, in-memory computing, incremental learning, and sophisticated alerting systems. Exploring these technology fields are beyond the scope of this article, but I recommend exploring the idea of temporal similarity search from KX.
No longer bound to look only at the past, the implications of streaming data science are profound. Predictions can be updated on what’s happening now, be used to proactively advise human operators, and augment high-value System Two decision-making. For example:
- Make a trading recommendation based on stock pricing patterns in the last hour
- Recommend maintenance on industrial equipment based on a surge of troubling sensor readings
- Alert flight operations of weather forecast changes that might impact congested routes
- Evaluate doctor’s notes in real-time to predict that a given patient shows signs of kidney failure

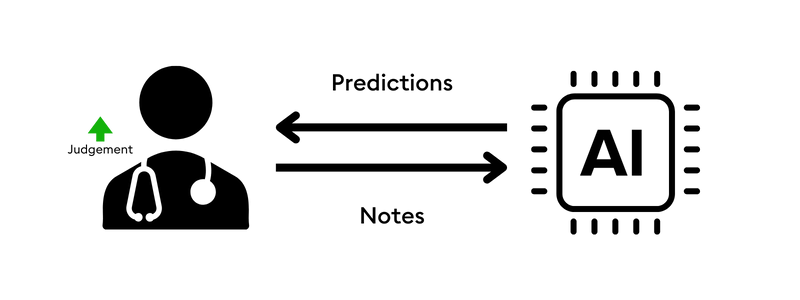
These applications all use machine learning and AI to make predictions based on live data. So rule three is to apply these techniques to your “now” data instead of only looking at the past.
Rule four: Utilize time-series data
It all starts with data. The most important concept to consider is the idea of processing data stored, processed, queried, and presented to users in a time series in nature, in the order it arrived. This typically means using a time series database like KDB from KX Systems or an open-source variation.
Instead of rows, columns, and relationships, time-series databases start with storing relationships between data in temporal order. The “physics” of this design decision makes them lightning fast and expressive when querying data for patterns in time so that real-time conditions can be quickly and easily compared to historical patterns to predict what might happen next.
For example, if a sudden change in weather forecast occurs during a Formula One race, a time-series database can execute a query in milliseconds of all previous races to find one where similar conditions occurred. This ability to find similar scenarios helps analytics teams predict what might happen next.

Time series data can be essential in any industry – even health care. In More, Faster, Cheaper Eureka Moments: Using Time-Series Data to Transform Clinical Trials, Nataraj Dasgupta explained, “Time-series databases are an ideal way to organize trial data. Fundamentally, we need to ask questions based on customer journeys, which happen in sequence, like: what happened in this trial first, then next, then next? Why did patients drop out in this trial versus this other, nearly identical one? Does this kind of protocol create too much of a patient burden? A foundational understanding of time, order, and sequence is essential.”
So, rule four is to build your projects based on time-series data.
Rule five: Monitor, alert, simulate
In traditional applications, monitoring, alerting, and simulation are often afterthoughts. However, when you build applications that navigate the now, managing what happens in real-time becomes essential—arguably job one.
A real-time dashboard, like a racing car’s dashboard, airplane cockpit displays, and trading screens is essential. Operating any system with a traditional historical dashboard would be like driving your car while only looking in the rear-view mirror.
Intelligent alerting has been discussed (Streaming Data Science, rule #3), and every real-time system should have a carefully designed notification system, filtering tools, and human workflow to resolve them.
The most overlooked element of real-time systems is simulation. Pilots, race car drivers, and traders know this. Especially in the early stages of training, pilots spend hundreds of hours in flight simulators as part of their training. Even the world’s best Formula One race car drivers, like Max Verstappen, swear by simulation as a complement to dangerous and expensive racing to keep their skills sharp and to vary their practice scenarios. Traders constantly simulate and update trading strategies based on changes in market conditions. In these professions, nothing happens without deep simulation.
Once again, the Knight Capital incident reveals what can happen without proper monitoring, alerting, and simulation. One account of Knight Capital revealed they violated all three of these requirements:
- They relied entirely on human monitoring
- Their system didn’t generate automated alerts
- Their staff weren’t prepared to deal with millions of aberrant trades
- They had no circuit breakers
- In the face of disaster, their teams didn’t know what to do
To avoid being Knight Capital, prioritize monitoring, alerting, and simulation. For business applications, this means designing monitoring systems for human operators, engineering anomaly detection algorithms, and simulating various financial market scenarios to decide daily trading strategies, how customer service representatives react to customer complaints, problems, or challenging requests, or how oil drilling staff respond to equipment warnings to ensure safe and secure operations.
Pilots, race car drivers, and traders use dashboards, automate alerts, and simulate thousands of scenarios to design and prepare their systems for the unexpected. You should do the same.
Reimagine your world with the hummingbird and the owl
Reimagine your applications as a dynamic duo: the swift hummingbird of System One and the wise old owl of System Two, working in harmony to navigate the ever-changing landscape of information.
Picture your next app as a nimble hummingbird, darting from data point to data point, making split-second decisions with the precision of a Formula One pit crew. Meanwhile, the wise old owl perches nearby, ready to swoop in with its analytical wisdom when the stakes are high, advised by streaming data and data science.
And remember these five rules.
- Design systems to complement the way your brain works
- Divide decisions into buckets to manage them
- Learn about streaming data science and use it
- Remember that time-series data is your new best friend
- Simulate, simulate, simulate
As you build your next groundbreaking application, channel your inner hummingbird-owl hybrid. Be swift, be wise, and most importantly, be ready to navigate the exhilarating world of now. In the realm of streaming data, there’s no time like the present – literally!
Discover how KX enables businesses to process time-critical data at speed, ensuring smarter, faster decisions in financial markets, manufacturing, defense, and beyond.


