
Developer

Download our latest ebook, and learn the secrets of cutting-edge re-ranking techniques for advanced search.
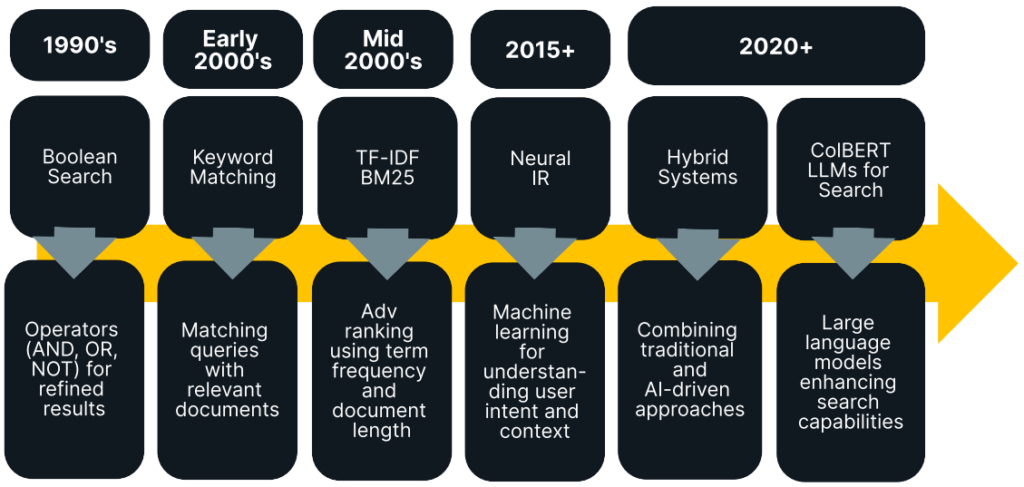
Search engines have evolved significantly over the years, from simple keyword matching to today’s more sophisticated algorithms that deliver the most relevant results. Re-ranking has been critical to this evolution, employing sophisticated techniques like dense embeddings to create smaller vectors and more meaningful values in search results.
In his latest Ebook, “The ultimate guide to re-ranking” developer advocate Michael Ryaboy investigates how search has evolved, highlighting how methods such as “two-stage search” balance the accuracy and efficiency of search mechanics through a division of initial retrieval and re-ranking.
Ranking approaches
Michael also explores pointwise, pairwise, and listwise approaches, citing their advantages and complexities before exploring the market’s various commercial and open-source options and their associated performance/cost trade-offs.
For example,
- How pointwise ranking treats the problem as a regression or classification task, with each query-document pair receiving an independent relevance score
- How pairwise aligns more closely to the fundamental nature of ranking as an ordering task by comparing document pairs and the relative ordering between candidates
- How listwise can capture complex dependencies between documents and optimize ranking metrics by considering the entire candidate set during ranking
Re-ranking applications
In finance, for example, re-ranking applications may include:
- Customer query resolution: By re-ranking search results based on the context of customer queries, support teams can provide more accurate and relevant responses, improving customer satisfaction and reducing response times
- Personalized financial advice: LLMs can analyze a client’s financial history, risk tolerance, and investment goals to provide personalized financial advice. Clients receive tailored recommendations that align with their unique needs by re-ranking investment options based on these factors
- Fraud detection and prevention: The system can re-rank alerts by analyzing transaction patterns and behaviors, allowing investigators to focus on the most suspicious cases first
- Regulatory compliance: By re-ranking search results based on relevance and recency, compliance officers can quickly access the most pertinent regulations, ensuring the organization remains compliant with industry standards
- Market research and analysis: Financial analysts can leverage LLMs to sift through large real-time and historical datasets to highlight market opportunities to generate alpha
With practical examples and a chance to build a cross-encoder search pipeline using KDB.AI, developers new to the space will get an opportunity to:
- Create a vector database with appropriate indexes for efficient search
- Chunk and embed documents using OpenAI’s embedding model
- Store documents and embeddings
- Performs hybrid search with Cohere’s re-ranker
Michael concludes that the best choice will ultimately depend on your domain needs and constraints. Whether dealing with large-scale data, tight latency requirements, or complex domains, understanding and implementing the proper re-ranking techniques can significantly enhance your search system’s performance.
Ready to dive deeper? Download the ultimate guide to re-ranking today and learn more about the vector database designed for AI at kdb.ai.
Download our latest ebook, and learn the secrets of cutting-edge re-ranking techniques for advanced search.


