








By Steve Wilcockson
Time data is primal. It has always been thus for modern computing, mathematics and, now, artificial intelligence.
From the founding grandparents of modern computing and AI – Ada Lovelace’s “analytical engine,” Alan Turing’s Enigma and Turing Machine-infused work on “Rounding-off Errors in Matrix Processing”, the “Grace Hopper nanosecond,” – elements of time, analytics and data inform modern computing.
For modern AI specifically, the core foundations were expressed through, for example, time and state-infused notions of dynamic programming, mathematical optimization and computing methods popularized by Richard Bellman. In turn, this influenced Geoff Hinton et al’s work on back-propagation which so informed neural networks and, infused by modern compute power and storage, underpins the inordinate scale and scope of the current generative AI epoch.
You, dear reader, are probably like I, neither a computing pioneer nor a neural network genius, just a humble individual bumbling through life wanting to make a difference to our nearest and dearest, make the world a better place. I suspect you, like I, work on real-world use cases, impacting your corporate and/or personal lives. For example:
- Which song will I like even more than the song I just enjoyed, and how can my music provider serve that up?
- How can my doctor diagnose my heart risk from a simple surgery and pharmacy blood test and set in motion a plan to help me live longer?
- Where and why did Sales just increase? Which customers became happy? How can more customers be happy?
- How do we best combine psychological profiling and physical evidence to find and convict the unsolved crime?
- How on earth did my local water utility provider just know that there was a leak in the road in front of my house without even digging up the road?
Or how do we help ourselves, our organizations and communities to mitigate risks, like these worrisome use cases?
- How can hospitals adapt their cybersecurity strategies given recent DDoS attacks amidst spending pressures and a lack of skilled cybersecurity specialists?
- What trading, investment or risk strategy should I deploy amidst a possible credit default despite a recent bullish trading history?
- How will the recent extreme weather impact supply chains and insurance risks?
- What churn trends happened because of unhappy customers in this month’s 2,000,000 customer conversations?
All these use cases use data, often different types of data, sometimes simulated and machine-generated data. All leverage prediction, much automated but mostly requiring human insight and intelligence for optimal action. All center on TIME. How significant is the impact of the water leak and when does the water company schedule the work?; when and how and into what do I adjust my portfolio?; how urgent is it that we implement the cybersecurity update across our hospital network and how does that impact frontline services? Time, time, time, prediction, decide, time, time, time.
And thus, we introduce the data timehouse which brings temporal-infused AI, the defining technology of our time, to the forefront of the data ecosystem.
A data timehouse is a data science-centric environment where the temporal, “time” – orchestrates prediction and information from a “house” of intertwined models and data.
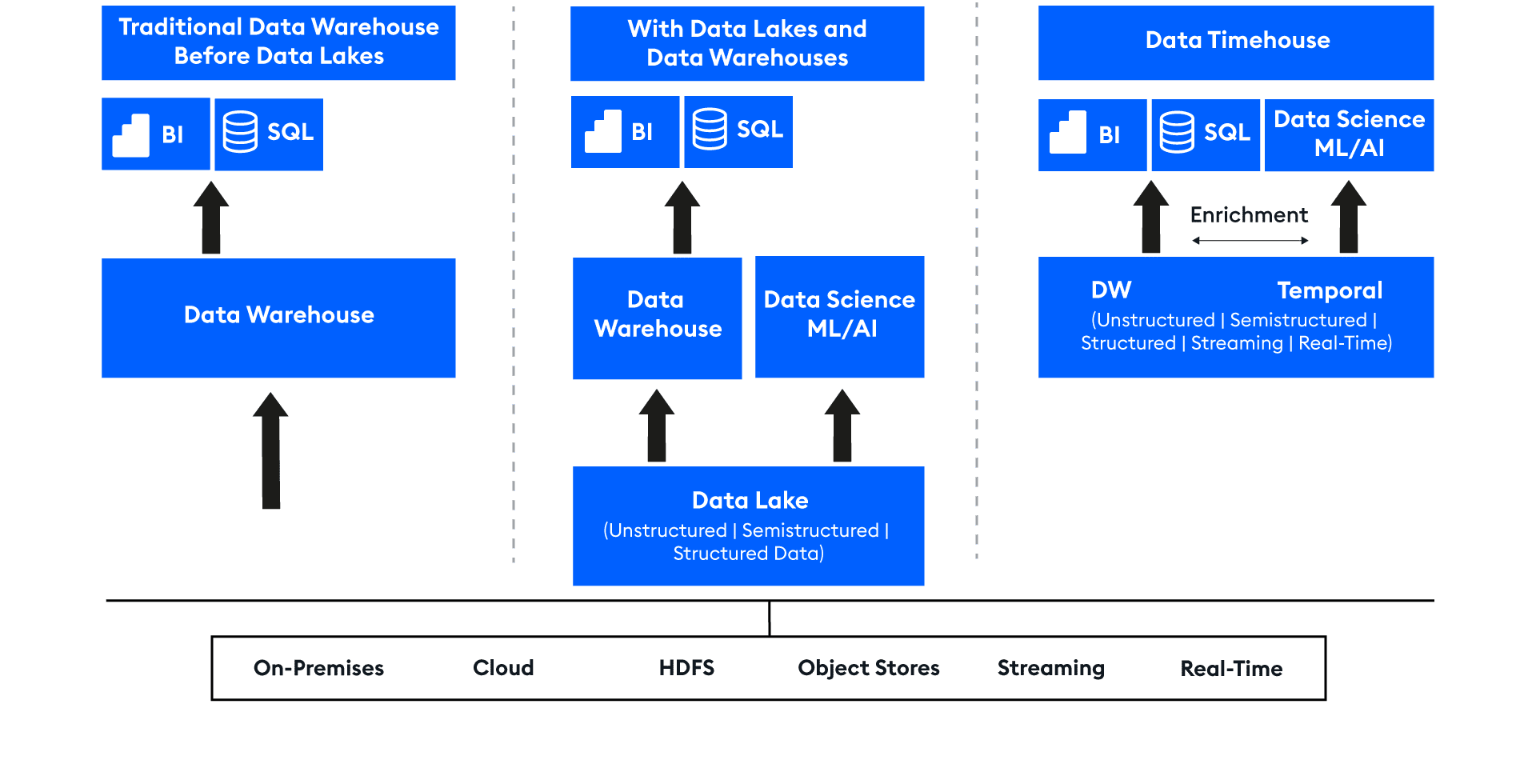
Not that it needs introducing, since many organizations already keep a data timehouse.
For them, the storage provided by a data lake and a data warehouse is only a part of their data story. Their priority is the intelligence, insight and outcome. Anything that prioritizes storage – the lakehouse, mesh, fabric – is insufficient. The data timehouse infuses data fuel with an analytics engine organized around time to create gold. Think of it as a temporal data warehouse, with added analytics able to engage data immediately in an ultra-efficient way.
Paraphrasing a CEO of a major financial exchange who has practised a data timehouse culture for years:
“There are no limits to all conceivable data in the universe that we could capture, in real-time to record a ‘continuous stream of truth, and ask any question of any dataset at any time, and get the answer instantaneously.”
The only limit is our imagination and in the questions we can think of to ask such as why did something happen? Or why did something happen the way it happened? Or what were the small events that led to the big event? And which factors influenced each event? If you know the answer to the question ‘why’, you can do a lot with that information.”
In the following sections of the article, we deconstruct some traditional views around so-called data categories. We then construct the data timehouse from the constituent parts, exploring how time, time-series, models, analytics, and vector mathematics reinforce each other, finally concluding with some real-use cases with particular reference to data science workflows.
Section 1: From Data Warehouse to Data Timehouse: The Traditional Storage-Narrative
Data warehouses have a substantial history in decision support and business intelligence applications. Since their inception in the late 1980s, massively parallel processing (MPP) architectures facilitated the handling of larger data sizes, provided they were structured. Unstructured and semi-structured data were however troublesome, and its core paradigm proved time and cost inefficient for data with high variety, velocity, and volume.
Thus about 15 years ago, architects envisioned the data lake, a single system housing data for many different analytic products – repositories for raw data in a variety of formats. While great for storing data, data lakes neither supported transactions nor enforced data quality. Also, their lack of consistency and isolation made it hard to mix appends and reads, and unwieldy for batch and virtually irrelevant for streaming jobs. It also had the misfortune to be built on top of a bewildering Hadoop ecosystem that has not aged well, a software equivalent of the Star Wars “A Phantom Menace,” a wrong cinematic turn and the ultra-annoying jar jar binks. Yes, I have a Data is the New Bacon T-shirt tucked away in my old t-shirt draw courtesy of my favorite Hadoop services provider, AND I also happened to be at a premiere of the Phantom Menace, both guilty pleasures.
The promises and hype of initial data lakes did not materialize, nor with Hadoop 2.0, nor numerous relaunches, and resulted, some say, in the loss of many warehouse benefits.
While data warehouse versus data lake divided opinions like pineapple on pizza, organizations used the cards they were dealt and got on with their jobs. While the data nerds got their Hadoop t-shirts and geeky tech, businesses continued to expand SQL analytics, real-time monitoring, and add new layers of data science and machine learning technologies to which I will return. Most firms evolved a polyglot of concurrent systems serving a variety of use case and key applications – perhaps a data lake, several data warehouses, SQL Server, MySQL or similar setups, and, depending on focus, specialized streaming systems, graph, and image databases. The result: poor responsiveness, and cost (and carbon footprint) inefficiencies across complex systems and a data stack not in harmony with the emerging analytics and model development universes inspired by the Pythonic movement.
Step forward Databricks, Dremio and others with key Apache projects like Spark and Iceberg. They promoted the useful lakehouse concept, more open and inclusive, allowing for sensible co-existence of lake and warehouse, with low cost cloud storage, object stores, and open formats to enable moderate interoperability. It has also, conveniently, enveloped hyperscaler cloud services into a convenient data lake story.
Yet even a “governed lakehouse” promotes and essentializes cheap storage at the expense of useful analytics, continuing to separate compute and storage, bringing the two together reluctantly, with latency, data transfer costs and inefficient queries in suboptimal localities. Key applications, such as real-time streaming analytics, are very far from front of mind yet a use case dynamic that thousands across the world participate in. The chaotic mesh and centralized lakehouse coexist somewhat, moderated sometimes by process-oriented fabrics. However, analytics is not at their heart. Skeptics might indeed argue that the lakehouse is simply a nice semantic to explain and circumvent the organizational lake-hack gloop the real world has ended up with.
Enter the data timehouse, a temporal data warehouse but with so much more.
Section 2: The Data Timehouse Constituent Parts
2a Temporal Data & Time-Series, The Basics
“It’s really clear that the most precious resource we all have is time.” — Steve Jobs
Okay, I perhaps take Jobs’ quote out of context, but let’s take a step back, get into the mindset of the data scientist and AI domain expert and explore their notion of time.
Most data, particularly machine generated data, has a temporal structure. That’s what data scientists analyse, whether it comes from sensors (machines, in factories) or human events (shopping events, stock markets, criminal activities, etc)
Knowing how to model time series is an essential skill within data science, as there are structures specific to this type of data that can be explored in all situations. Don’t get caught up, yet, in terms of time scales like seconds or months, just think of units of time as periods.
Structure of a Time Series
A time series is a series of data points indexed in time order, like this:
Measurement Time Temp Pressure Wind Speed
____________________ ____ ________ __________
18-Dec-2015 08:03:05 37.3 30.1 13.4
18-Dec-2015 10:03:17 39.1 30.03 6.5
18-Dec-2015 12:03:13 42.3 29.9 7.3
The timestamp represents a focal point of the moment in time when an event – a weather phenomenon – was registered. The other column designates a value delivered by this phenomenon at that moment. More recorded values mean multivariable time-series.
We might want to synchronize the weather data to regular times with an hourly time step, and adjust the data to new terms using an interpolation method. Thus the data has now undergone some simple time-series analysis.
Measurement Time Temp Pressure Wind Speed
____________________ ______ ________ __________
18-Dec-2015 08:00:00 37.254 30.102 13.577
18-Dec-2015 09:00:00 38.152 30.067 10.133
18-Dec-2015 10:00:00 39.051 30.032 6.6885
18-Dec-2015 11:00:00 40.613 29.969 6.8783
18-Dec-2015 12:00:00 42.214 29.903 7.2785
18-Dec-2015 13:00:00 43.815 29.838 7.6788
Time-series can be regular time-series, a record at each uniform moment in time, say a daily series of temperatures, or an hourly series like the modelled data above. Other time-series can be irregular, for example, like the initial dataset above of weather observations, or a log of accesses to a website. It could also be a time when a chess move is made in a match. In capital markets, both types are used interchangeably, for example stock prices. Published stock prices might reflect a given or modelled price over specific time frequencies, every second for example. However, “ticks” can occur at any moment in time, a trade, a quote, etc. At certain occasions, e.g., market open, there are many ticks – a lot happens. Market-makers, for example, watch the individual ticks closely, where as the retail broker systems us amateur traders deploy when we feel like going in the market tend to work with aggregated data-sets, for example 15 second price updates.
In all these cases, understanding the temporal dynamics of the weather data, the sequences of chess moves and the “ticks” on the stock price inform our ability to determine information about future paths – the prediction – of future events.
2b Models & Analytics: An Example
Model-speak alert. If you’re not a modeller, I try to keep this section a high level but salient points appear in the “Why it Matters” section.
I’m going to explore the model concept through the lens of one of the most influential algorithms readers may not have heard of – singular value decomposition (SVD). Obscure, perhaps, but the very essence and foundation of AI as you know it. It is intertwined closely with the dynamic programming and backpropagation techniques discussed at the very start of this paper.
What is Singular Value Decomposition (SVD)?
Singular Value Decomposition (SVD) matrix factorization (or decomposition) is a workhorse of modern numerical computing. Its use is found in statistics, signal processing, econometrics, information retrieval, recommender systems, natural language processing, image processing, computer vision, engineering, control systems theory, machine learning (heavily used in tensor/multi-linear-algebra learning, multi-task learning, and multi-view learning), deep learning (DL), plus more. Most of these mathematical use cases center on time. Indeed, for time-series, SVD is a crucial tool to discover hidden factors in multiple time series data, and it is used in many data mining applications including dimensionality reduction and principal component analysis (PCA) that get used in real-time statistical inference and MLOps workflows, for example in recommender systems or fraud detection use cases.
The factorization of a big matrix with the standard SVD is compute and memory-intensive. Think of a retail dataset matrix of [transactions x products]. A supermarket sales matrix data with, say, a weekly transaction set of 500K for 40K products available, is a sizeable dataset for the standard SVD. This matrix size [500K x 40K] can take hours/days (depending on the computing infrastructure if SVD is parallelized or not) to factorize/decompose if you don’t run into an ‘out of memory’ error already, by using, say, ‘numpy.linalg.svd’ or ‘scipy.linalg.svd’ in Python.
What on earth did you just say? Why does it matter?
Here are four reasons why what I just said above matters, with a little less deep matrix algebra jargon.
- The supermarket data-set is likely a time-series.
- Decomposition makes sense of the data-set and puts it in a form useful for statistical and machine learning, It’s memory – and compute – hungry. The data-set is completely intertwined with the algorithm, and that’s before we’ve even gotten to the “sexy” predictor.
- Its organization is conducted via vectors, or matrixes, with the process of revising loop-based, scalar-oriented code to use vector or matrix operations called vectorization. Vectorizing your code is worthwhile for several reasons:
- Vectorized mathematical code appears more like the mathematical expressions found in textbooks, making the code easier to understand. The SVD process outlined above is a foundational element of matrix algebra or linear algebra. Vectors commonly represent events over time.
- Less Error Prone: Without loops, common to most code conventions, vectorized code is often shorter. Fewer lines of code mean fewer opportunities to introduce programming errors. In big data and compute-intensive processes, this matters.
- Vectorized code often runs much faster than the corresponding code containing loops. In big data and compute-intensive processes, this matters.
- Everything described in the SVD section above involves data and operations on that data. Data on its own is ineffectual
- The programming language alluded to above is Python. It encapsulates a completely different model-centric world to the data store.
So, bringing all this together – core operations – requires the co-existence of Azure blobs (or other data stores) and Python (or similar, e.g., C++, MATLAB, Java) code-sets. That means compute combines with storage for analytics, deep in the data as with SVD, and at the higher level to abstract meaning, e.g. the machine learning algorithm.
Taking the SVD routine a stage further into the AI and key machine learning use cases that it underpins, a common machine learning set of analysis is dimensionality reduction. This matters, as reducing the number of features in a data-set while preserving as much information as possible drives effective model training into a trained model and subsequent live model inference. That helps deliver a live insightful model, for example one that doesn’t just observe supermarket sales in real-time but one that predicts and delivered up-to-the-minute trends, as product purchases scan through the tills.
That workflow commonly centers on the Python programming language as the language of data science model development. That said, as workloads – data and model – go from research to production, attributes like speed, resilience and efficiency matter. Production implementations, likely cloud-centric and MLOps, matter. Python drives, but production tooling downstream looks different.
What Do I Do then with a Data Timehouse?
Stop stuffing temporal data in your data warehouse sock drawer and do as others already do well. Deploy temporal data into your data timehouse, get it used in a convenient form by your Python programmers, data scientists and data analysts. In this way, put data science at the centre of your workflow. Be more productive. Be more useful. Leverage the technology trend that defines our modern age, AI.
As a CEO of one healthcare organization puts it, “we answer questions in minutes that take days at most healthcare companies.”
Their outcome: The data timehouse is 100X faster and 1/10th the cost for their time series data than queries running on the data warehouse and lakehouse platforms like Snowflake and Databricks, because the data timehouse efficiently captures the data and predictor through the common denominator of time series.
On the other hand, compared to data science and machine learning platforms used – for example Dataiku or “pure” Pythonic code running in-memory, the data efficiency of the data timehouse – in-memory in an optimized way – is similarly 100X faster.
For them as others, the data timehouse nicely blends data science with data through the common denominator of time.
The data timehouse most likely interoperates with a warehouse, where storage of a governed golden source data set matters, as it does the model environment. Yet it carries core workloads, running them so much more efficiently. The data timehouse works “natively” with both data and model sides of the house.
Quoting the real-world use case of our CEO’s company, “we stream 400,000 trials and get insights at the speed of thought. Like ‘Which trials ran in two countries?’ ‘How did they perform?’ ‘Which patients should we try next?’” The economic impact to them: they suggest $1m PER DAY of value realised from faster clinical trials and quicker time to market arising from their use of the data timehouse, with $10m-$100m saved per each unsuccessful trial which might otherwise get pursued.
What does a data timehouse look like?
The time series nature of the healthcare company’s business problem entails mapping and aggregating sequences of events & interventions to better understand the pathway patterns to success of their trials. With this, they understand the patterns of referrals to build their optimized map from the temporal sequence of visits to different prescribers.
That means working with a range of data sets, all centered around time, such as:
| Time Data | Update Frequency | Enriched With |
| Daily Operational Data: Enrollment status, daily sales calls | Daily | CRM |
| Successive Trial Observations: Patient diagnosis, site visits | Intraday | Other trials |
| Simulation Data: e.g. Heart-beat simulations | Bursty | Metadata |
| Machine / Sensor Data: Smart manufacturing | Real-Time | Metadata |
In putting the temporal at the center of their architecture, they consolidate and guide their analytical queries and statistical and machine learning models, core to their derived business value – the insight.
They leverage their data timehouse’s ability to perfectly blend data and analytic, memory and compute, to best effect, to deliver blindingly fast queries and analytics at a mere fraction of the cost of alternative paradigms. It looks like this.
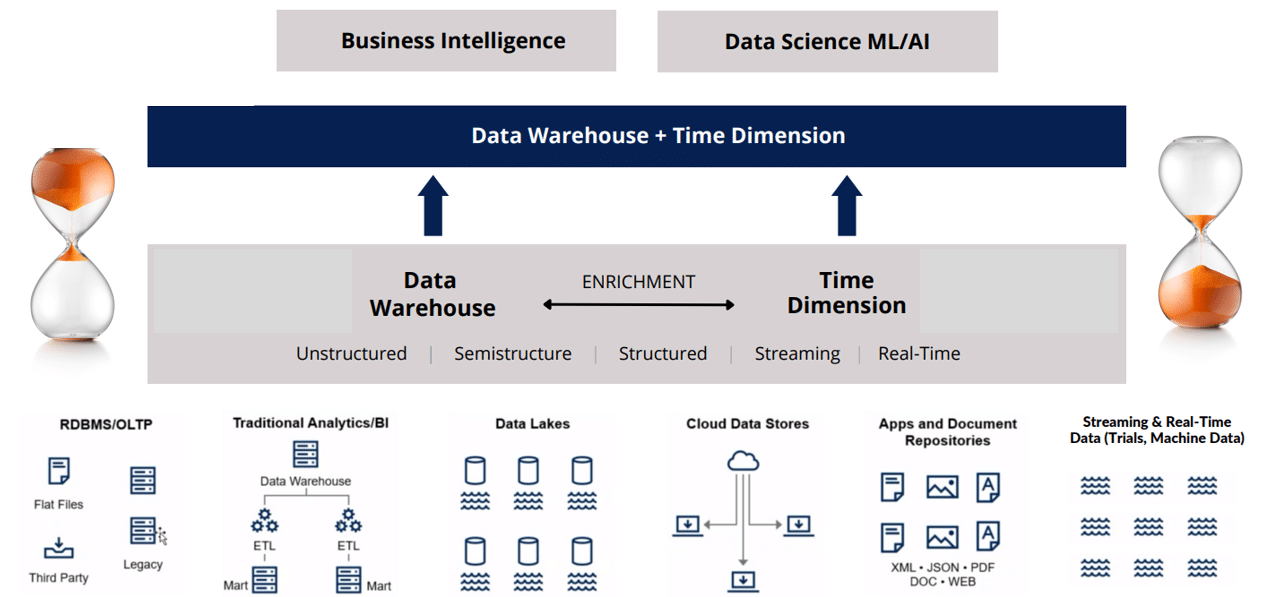
Do you have a data timehouse, but don’t know it? If so, how is yours architected? Email and tell me!
Want to know more about how you could build a data timehouse? Contact KX today!


