
Key Takeaways
- Simultaneous search unifies various AI search methods into a single, cohesive system that enhances the efficiency and accuracy of search results.
- Simultaneous search bridges the gap between structured and unstructured data by orchestrating agents, modular, reasoning-capable LLM wrappers that not only retrieve but also reason, calculate, and synthesize
- Using solutions such as kdb+ and NVIDIA’s GPU-accelerated AI stack, organizations are provided with a streamlined, high-performance foundation to power simultaneous search at an enterprise scale.
The AI banker agent NVIDIA’s Jensen Huang unveiled at GTC Paris wasn’t just a slick demo; it was a glimpse into the future of search, where LLMs don’t just summarize documents or crunch numbers but do both simultaneously.
Developers building AI applications today typically run two different playbooks: one for structured data (SQL queries, time series) and another for unstructured data (docs, PDFs, embeddings, RAG, etc.).
While each stack works well on its own, real-world questions can leave developers struggling to generate results from two entirely different pipelines.
In this blog, I’ll unpack what makes simultaneous search different, how agentic systems make it work, and how you can build one yourself.
What is simultaneous search?
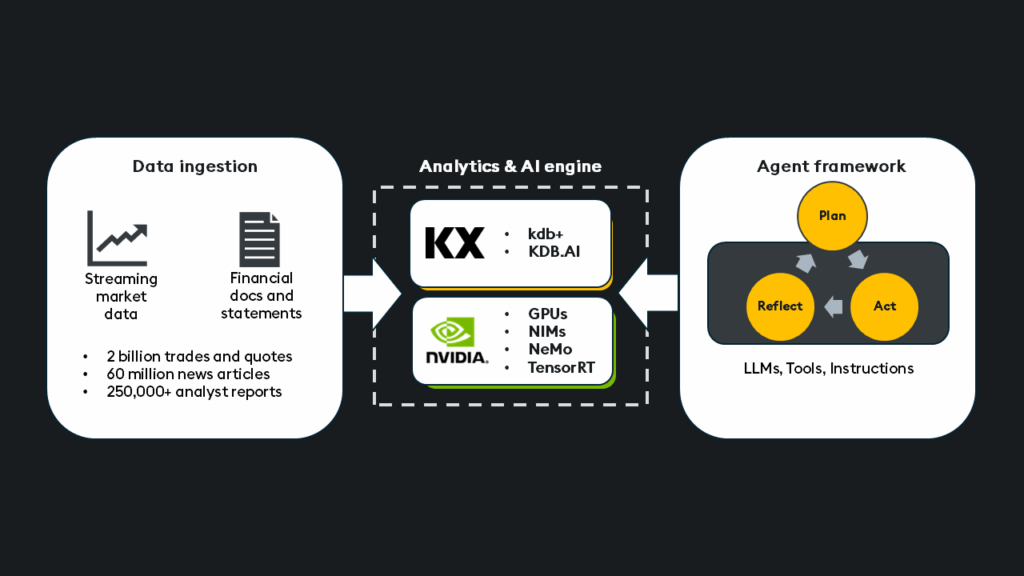
At its core, simultaneous search is exactly what it sounds like: a single query triggering a coordinated search across both structured and unstructured data, formulating results into one coherent, context-rich answer that feels more like an AI assistant and less like an API Frankenstack.
Using solutions such as kdb+, the entire data estate can reside on a single unified platform. Then, when paired with NVIDIA’s GPU-accelerated AI stack, including NIMs, NeMo, and TensorRT, organizations are provided with a streamlined, high-performance foundation to power simultaneous search at an enterprise scale.
Simultaneous search bridges the gap between structured and unstructured data by orchestrating agents, modular, reasoning-capable LLM wrappers that not only retrieve but also reason, calculate, and synthesize. These agents utilize a set of tools to retrieve relevant data from vector databases, real-time analytics engines, and external APIs, enabling them to tackle complex questions within a single unified workflow.
For example, an LLM-powered system understands what information it needs, pulls key sections from a 10-K filing, runs VWAP (volume-weighted average price) comparisons from tick data, flags anomalies in price behavior, and returns a clean, context-aware answer with citations and charts.
This requires three core components:
- A model (the LLM) for reasoning
- A set of tools (APIs, databases, analytics engines)
- A clear goal or instruction (what the agent is trying to achieve)
Now, imagine orchestrating multiple agents, each with a specialized role. This can range from a simple logic-controlled flow, where agents select the proper functions and tools, to a complex, divide-and-conquer multi-agent approach that collaborates like a team of digital analysts.
Each agent operates independently but within a shared workflow context. They can pass context to one another, revise plans based on intermediate results, and coordinate to answer questions that span multiple data modalities.
Financial use case
The AI research assistant, part of AI labs, is a goal-seeking agentic system that streamlines quantitative analysis by combining real-time market data, SEC (Securities and Exchange Commission) filings, and deep learning forecasts to compress hours of research into seconds.
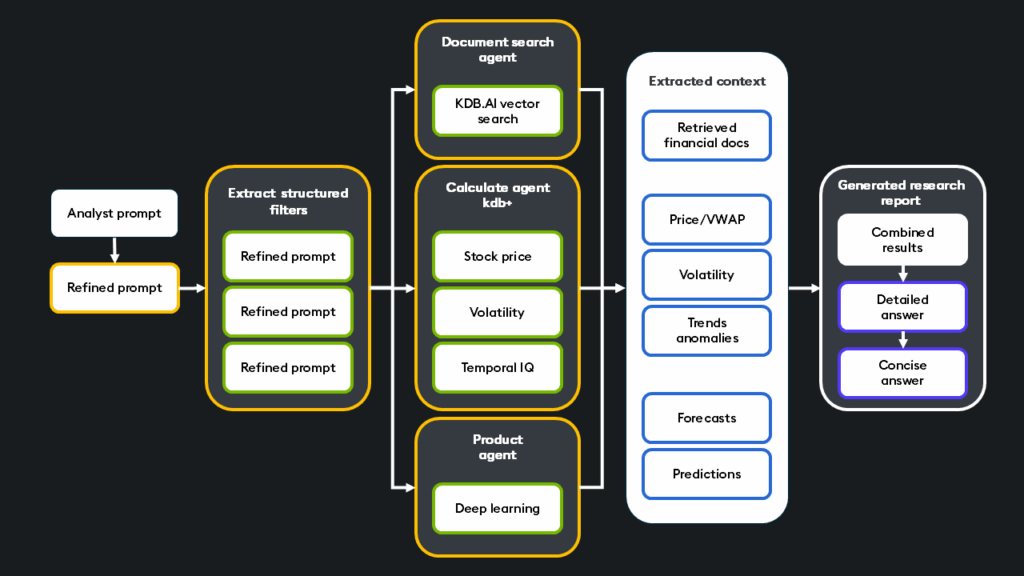
Given a complex and multi-part question, the equity research assistant first breaks down the question into sub-questions and extracts relevant structured information from the refined prompt. From here, the framework of agents search for relevant unstructured data and executes various structured queries. Once the contextual information is gathered and calculated, it is combined, and both long and concise answers are generated.
Let’s create a simplified version of the above using a custom agentic workflow with logic-driven orchestration and tools that leverage OpenAI’s function-calling API. The purpose will be to explore the core tooling and agentic pieces and will not include full functionality.
Step 1: Configuration
First, we will define the parameters, variables, and embedding model that our agents and tools will use.
# ---------------------
# Constants and Config
# ---------------------
import os
os.environ['PYKX_4_1_ENABLED'] = 'True'
import pykx as kx
# Path to your database
DB = '/data/kx/db'
# Embedding and device settings
EMBEDDING = 'nvidia/NV-Embed-v2'
DEVICE = 'cuda:0'
DIMS = 4096
# LLM models (for fast and big completions)
FASTLLM = 'mistral-small'
BIGLLM = 'llama3.3-16k'
_llm = OpenAI(base_url='http://localhost:12345/v1', api_key='foo') # NIMs hosted
# Retrieval parameters
METRIC = 'CS'
K = 10
# Embedding model
def load_embedding():
return SentenceTransformer(EMBEDDING, device=DEVICE, trust_remote_code=True)
embedding_model = load_embedding()Step 2: Database initialization
Next, we will initialize the kdb+ database so that we may perform search functions across our datasets.
# ---------------------
# Initialize kdb database (Preloaded with embeddings via NV Embed V2)
# ---------------------
def load_kdbai():
kx.q.Q.lo('/data/kx/db', False, False)
kdbai = kdbai_client.Session()
db = kdbai.database('default')
if 'docs' in [x.name for x in db.tables]:
table = db.table('docs')
else:
indexes = [dict(name='docsFlat', column='Vectors', type='qFlat', params=dict(dims=DIMS, metric='CS'))]
table = db.create_table('docs',
external_data_references=[dict(provider='kx', path=b'/db')],
indexes=indexes)
table.update_indexes(['docsFlat'])
return table
table = load_kdbai()Step 3: Tool and function definition
Now, we set up the tools to be used by the AI banker agent. These tools range from vector retrieval to financial analytics like VWAP and volatility calculations.
# ---------------------
# Vector Retrieval
# ---------------------
# Used for semantic search, performs vector search on unstructured document chunks
def retrieve_documents(prompt, partitions, types, date_range, keyword):
# Obtain the embedding vector for the prompt
prompt_vector = embedding_model.encode(prompt)
cols = ["__nn_distance", "int", "Symbol", "Type", "Date", "Source", "Chunk", "Text"]
cols = dict(zip(cols, cols))
result = table.search(vectors=dict(docsFlat=[prompt_vector]),
filter=[("in", "int", partitions),
("in", "Type", types),
("within", "Date", date_range),
("like", "Text", f"*{keyword}*")],
aggs=cols,
n=K)[0]
if len(result) == 0:
result = table.search(vectors=dict(docsFlat=[prompt_vector]),
filter=[("in", "int", partitions),
("in", "Type", types),
("within", "Date", date_range)],
aggs=cols,
n=K)[0]
result['Text'] = result['Text'].str.decode('utf-8')
return result
# ---------------------
# Time series tools (kdb+)
# ---------------------
# Used for calculation, gets price, vwap, and volatility
def get_stock_data(symbol:str, start:date=None, end:date=None) -> pd.DataFrame:
if start is not None and end is not None:
if type(start) is str:
start = date.fromisoformat(start)
start -= timedelta(days=365)
if type(end) is str:
end = date.fromisoformat(end)
end += timedelta(days=365)
data = kx.q.qsql.select(tab, columns={'date':'Date', 'open':'Open', 'low':'Low', 'close':'Close', 'volume':'Volume'}, where=kx.Column('Symbol')==symbol & kx.Column('Date').within(start, end)).pd()
else:
data = kx.q('{select date:Date, open:Open, high:High, low:Low, close:Close, volume:Volume from stocks where Symbol=x}', symbol).pd()
data.set_index('date', inplace=True)
return data
def get_stock_price(symbol:str, start:date=None, end:date=None) -> pd.DataFrame:
data = get_stock_data(symbol, start, end)
data['price_volume'] = data['close'] * data['volume']
data['vwap'] = data['price_volume'].rolling(window=30).sum() / data['volume'].rolling(window=30).sum()
price = data[['vwap']]
col = f'{symbol} 30-days VWAP price'
price.columns = [col]
return (price)
def get_stock_volatility(symbol:str, start:date=None, end:date=None) -> pd.DataFrame:
data = get_stock_data(symbol, start, end)
data['log_return'] = np.log(data['close'] / data['close'].shift(1))
data['volatility'] = data['log_return'].rolling(window=14).std().ewm(span=14, adjust=False).mean()
volatility = data[['volatility']].copy()
col = f'{symbol} 14-days EMA volatility'
volatility.columns = [col]
volatility['month'] = volatility.index.year.astype(str) + volatility.index.quarter.astype(str)
dfs = []
for _, month in volatility.groupby('month'):
month['blocked'] = month[col].max()
dfs.append(month)
volatility = pd.concat(dfs)[[col, 'blocked']].sort_index()
return (volatility)
def call_tool(tool, **kwargs):
if tool == 'get_stock_price':
return get_stock_price(**kwargs)
elif tool == 'get_stock_volatility':
return get_stock_volatility(**kwargs)
else:
raise Exception('No such tool!')
TOOLS = [
{
"type": "function",
"function": {
"name": "get_stock_price",
"description": "Get the historical 30-days VWAP price.",
"parameters": {
"type": "object",
"properties": {
"symbol": {"type": "string", "description": "The stock symbol or ticker"},
"start": {"type": "date", "description": "The start date"},
"end": {"type": "date", "description": "The end date"},
},
"required": ["symbol"]
}
}
},
{
"type": "function",
"function": {
"name": "get_stock_volatility",
"description": "Get the historical 14-days EMA volatility.",
"parameters": {
"type": "object",
"properties": {
"symbol": {"type": "string", "description": "The stock symbol or ticker"},
"start": {"type": "date", "description": "The start date"},
"end": {"type": "date", "description": "The end date"},
},
"required": ["symbol"]
}
}
},
]Step 4: LLM functions
Our workflow will leverage several LLMs. A fast LLM using Mistral that is used for prompt refinement and extracting filters. An LLM that determines which tools should be called based on the query. Finally, an LLM to run the final analysis on the aggregated results of the simultaneous search.
# ---------------------
# Define LLM functions
# ---------------------
# LLM used for majority of functions and tools
def fastllm(prompt):
messages = [{'role': 'user', 'content': prompt}]
response = _llm.chat.completions.create(model=FASTLLM, messages=messages, temperature=0, stream=False)
return response.choices[0].message.content
# Let the model decide what tools are needed to answer the refined prompt
def toolllm(prompt):
messages = [{'role': 'user', 'content': prompt}]
response = _llm.chat.completions.create(
model=FASTLLM, messages=messages, tools=TOOLS, temperature=0, stream=False
)
results = []
if response.choices[0].message.tool_calls is not None:
print(response.choices[0].message.tool_calls)
for tool in response.choices[0].message.tool_calls:
name = tool.function.name
args = tool.function.arguments
if type(args) is str:
args = json.loads(args)
results.append((name, call_tool(name, **args)))
return results
# LLM used for generating a detailed final response considering all context
def bigllm(prompt, stream=True):
messages = [{'role': 'user', 'content': prompt}]
if stream:
response = _llm.chat.completions.create(model=BIGLLM, messages=messages, temperature=0, stream=True)
for chunk in response:
token = chunk.choices[0].delta.content.replace('$', '\\$')
if token is not None and token != '':
yield token
else:
response = _llm.chat.completions.create(model=BIGLLM, messages=messages, temperature=0, stream=False)
return response.choices[0].message.contentStep 5: Refine input query and extract filters
From here, the tools and functions used to refine the prompt, extract filters, and identify the correct data retrieval and query tools to use are defined.
# Main agent system prompt
SYSTEM_AGENT = f"""
You are a Financial Analyst working at a big firm with access to
SEC Filings (10-K, 10-Q, 8-K) from the EDGAR database.
Today's date is {date.today()}.
"""
# Refine the prompt
def refine_prompt(prompt):
ctx = f"""{SYSTEM_AGENT}
Analyze the prompt and derive an action plan (with a focus on SEC filings)
without solving it. Clarify the fiscal period to look at to solve
the prompt. Output **only** the final prompt, **ONLY** the final prompt.
"""
refined = fastllm(ctx)
# Append the LLM-augmented prompt to the original
return f'{prompt}\n{refined}'
# Helper function to pass prompts to the LLM and parse output to JSON
def _infer(prompt):
answer = fastllm(prompt)
try:
json.loads(answer)
except json.JSONDecodeError:
m = re.match(r'.*```(json)?\n(.*)\n```.*', answer, flags=re.MULTILINE | re.DOTALL)
if m:
answer = m.groups()[1]
return json.loads(answer)
# Identify what symbols this prompt is referencing
def infer_symbols(prompt):
ctx = f"""{SYSTEM_AGENT}
User prompt: {prompt}
Analyze the prompt in your mind to infer a list of NYSE tickers (symbols).
Output **only** the symbols as a simple JSON list.
"""
return _infer(ctx)
# Identify necessary document types to search for
def infer_types(prompt):
ctx = f"""{SYSTEM_AGENT}
User prompt: {prompt}
Analyze the prompt in your mind to infer a list of relevant SEC filing types
(either 10-K, 10-Q, 8-K). If you are not sure,
include the form type 8-K just in case.
Output **only** the form type labels as a simple JSON list.
"""
return _infer(ctx)
# Identify a date range from the prompt
def infer_date_range(prompt):
ctx = f"""{SYSTEM_AGENT}
User prompt: {prompt}
Analyze the prompt in your mind to infer a matching fiscal period.
Output only the period as a JSON list like: `["2000-01-01", "2001-01-01"]`.
"""
return _infer(ctx)
# Summarize the prompt into a single keyword
def infer_keyword(prompt):
ctx = f"""{SYSTEM_AGENT}
User prompt: {prompt}
Summarize the prompt to a single most specific key word.
Output **only** the key word as a single JSON string.
"""
return _infer(ctx)
# Use tools LLM to decide which tools to use
def use_tools(prompt, date_range):
ctx = f"""{SYSTEM_AGENT}
User prompt: {prompt}
Relevant period:
- start date: {date_range[0].isoformat()}
- end date: {date_range[1].isoformat()}
Use all necessary tools.
Use the relevant period to specify the start and end dates.
"""
return toolllm(ctx)With the necessary components now configured, we will begin implementation and orchestration. For example, you could use an MCP server, allowing agents to access as needed, build a hierarchical agent stack, use a central controller to direct each agent, or design a decentralized system where agents coordinate and make decisions independently.
In our implementation, the flow is intentionally simple and linear: Refine prompt → Extract metadata → Invoke tools → Combine context → Generate answer.
Because all data, queries, and retrieval operations live entirely within the kdb+ ecosystem, we don’t need complex orchestration logic. That said, thanks to the modular design, it’s easy to evolve this into a more dynamic or multi-agent system if the problem space grows in complexity.
user_prompt = "YOUR PROMPT"
# Simple example linear orchestration flow
refined_prompt = refine_prompt(user_prompt)
symbols = infer_symbols(refined_prompt)
partitions = kx.q.cast('long', kx.q.enumerate('sym', symbols))
types = infer_types(refined_prompt)
date_range = infer_date_range(refined_prompt)
date_range = (date_range[0], date_range[1] + timedelta(days=60))
keyword = infer_keyword(refined_prompt)
docs = retrieve_documents(refined_prompt, partitions, types, date_range, keyword)
tool_results = use_tools(refined_prompt, date_range)
# Format the retrieved docs and time series data:
docs_list = docs.to_dict(orient="records")
formatted_docs = "\n\n--\n".join([format_doc(x) for x in docs_list])
formatted_tools = "\n\n".join([x[1].to_markdown() for _, x in tool_results])
# Full Context (Structured & Unstructured)!
CTX = f"""{SYSTEM_AGENT}
Retrieved SEC filings:
{formatted_docs}
Time series tools:
{formatted_tools}
Prompt: {refined_prompt}
Answer the prompt based on the provided context.
Justify your answer with specific references to SEC filings, with page numbers (at the bottom of each chunk), from the context.
Add a table of references to SEC filings with page numbers when possible, but without mentioning chunk numbers.
"""
answer = bigllm(CTX)
CTX += f'''
Long answer: {answer}
Summarize the answer to a **very short conclusion**.
'''
short_answer = bigllm(CTX)As you can see, the output consists of both a long-form analysis and a concise answer.
Simultaneous search isn’t just a concept; it’s a capability made possible by a tightly integrated, high-performance tech stack. Every component plays a role, ensuring that both structured and unstructured data are retrieved, reasoned over, calculated on, and synthesized in real-time.
- It breaks down barriers between structured and unstructured data, unifying them into a single, intelligent query flow that answers questions with depth and precision.
- It’s holistic, bringing together documents, numbers, predictions, and reasoning.
- It’s fast, built on real-time infrastructure that effortlessly scales to even the most demanding workloads.
- And it’s intelligent, powered by agents that know when to search, when to calculate, and how to synthesize.
What to learn more? Request access to the AI labs, a ready-to-use environment designed to prototype production-grade AI systems with KX, NVIDIA, and our partner ecosystem. You can also begin your journey with kdb+ by downloading the personal edition or via one of our many courses on the KX Academy.


