

PyKX is an interface between Python and kdb’s vector programming language q and its underlying data types. By taking a Python-first approach, it makes the power of kdb+’s vector and time-series analytics easily available – indeed almost transparently available – to those of a more Pythonic bias. The result is to enable anyone with Python knowledge to develop and run high-performance real-time analytics against vast amounts of data without necessarily knowing the details of q or kdb yet benefitting from their undisputed power.
PyKX was first released in February 2022 and has evolved significantly in response to user feedback. Below is a summary of highlight changes in 2023 up to the latest version, 2.1.1.
First, we should note its different modes of operation.
PyKX Modes of Operation

PyKX within Python: Unlicensed Mode
The unlicensed mode enables users to make connections to q processes and run remote commands. The example below shows how a table can be created in a remote q process and then queried using the more Pythonic-like q.sql.select syntax for building up the query rather than the standard “select from tab where..” of q itself.
Note that because q is not included within the Python process (as it is the unlicensed version), a pointer rather than the q object representation. The right-hand side shows, however, that users can choose the format they want the data converted to with options including Python, Pandas, PyArrow, or NumPy. Also illustrated is the ability to use the more intuitive context interface – first to include a Python dictionary in an q.upsert command for adding data to a table and then using count to verify its successful commit.

PyKX within Python: PyKX Licensed Mode
Licensed mode provides much greater standalone power as it removes the need for a separate q process. Python is running the main loop and it has effectively all the power of q bar the ability to run timers and to operate as server/client simultaneously. As a simple example, we see below how the response is presented as q object, in this case “2”, rather than simply a pointer as in the unlicensed example above.

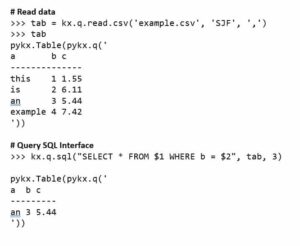
Below is an example of new 2.1 functionality for reading csv files – in this case wrapping the q command in a Python library rather than demanding the use of the “0:” syntax. Similarly, familiar SQL syntax can be used for making queries. SQL syntax can also be used in unlicensed mode if the server-side process enables this feature.
PyKX within q
Entering \l pykx.q within a q process presents an environment very similar to embedPy that this mode replaces. The differences relate to namespace changes required to convert previous embedPy code to PyKX and how strings and symbols are transferred between q and Python. Previously, both strings and symbols were mapped to strings in Python, meaning that round tripping could not be undertaken due to the associated information loss. In the new PyKX implementation, a kdb string becomes a byte list in Python and a symbol becomes a string which, with some refactoring, facilitates round tripping.

Further functionality is illustrated below. In the first case, pykx.set and pykx.get can be used to pass data over and back between q and Python, and in the second case, the ability to extend q code with Python by indexing into a library and calling specific functions as if they were native q functions. Note using the backtick, which triggers the Python result to be converted to a q object. This allows you to chain multiple Python functions and choose when you wish to convert the final result only using `.

PyKX in 2023 – Highlight New Features
Configuration
Changes have been made to make installation and configuration easier. An interactive session guides users through getting a license with an email enabling them to either configure it as a file on a specific path or proceed with the given key within the Python session (particularly convenient if running on a remote server and eliminating the need to get a file transferred to it).
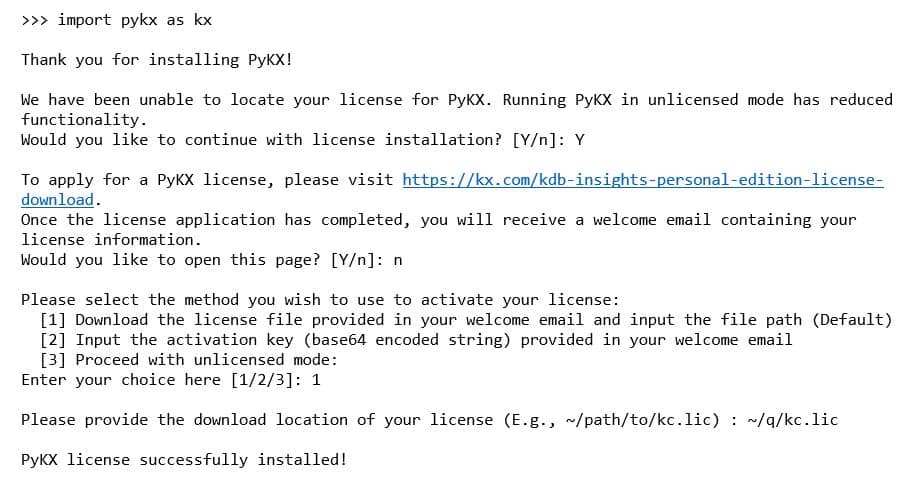
In addition to controlling configurability via environment variables, it’s now possible using a .pykx config file. Moreover, it’s possible to define multiple configurations, for example, one for test and one for staging, and then select the appropriate one at startup. Challenges in detecting LibPython have been made easier by enabling users to specify its location should automatic detection be unsuccessful. Finally, a debug utility has been added to capture environment information to assist problem diagnostics and resolution at installation.
Pandas API additions and Pandas 2.0 Support
As the goal for PyKX is to provide a Python-first experience, we’ve added support for the latest Pandas 2.0 releases. The table below presents what is now available in the PyKX Pandas-like API.
Below is an example of using this functionality.

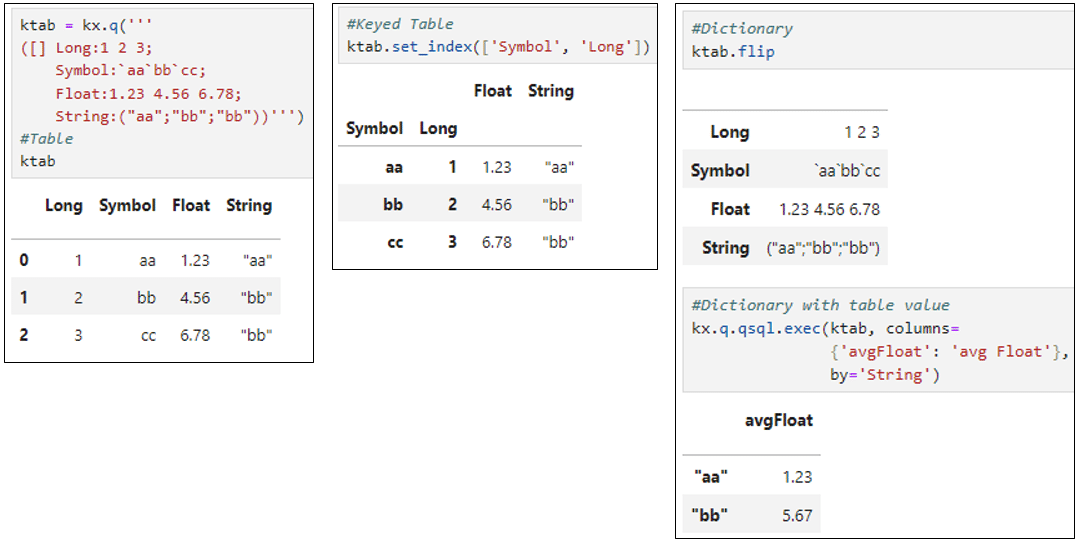
- Starting on the left, we create a table using the table constructor into which we pass our data
- We then call one of the Pandas API functions set_index, which effectively makes it a key table
- Next we call groupby using levels 0 and 1 in Pandas syntax, which in this case are “Animal” and “Type” (in q these would be keys)
- The grouped results are presented in a table showing one entry for “Parrot Wild” and two values, 20 and 25
- Finally, an aggregation is performed, which in this case is .mean, which presents 22.5 as the mid-point
It may be noted that some keywords have been omitted. This is simply because in some cases they may not be appropriate. An example is drop=False for set_index as kdb tables should not include duplicate column names
Printing Improvements within Jupyter Notebooks
Notebooks now support HTML rendering of tables and dictionaries (pykx.Table, pykx.Dictionary, pykx.SplayedTable , pykx.PartitionedTable and pykx.KeyedTable objects) via _repr_html_. Some examples are presented below:
Also included is truncation for long and/or wide tables, including partition and splayed tables, with row and column count and last line display for truncated tables. Previous q style output is still available using print.
Other Changes
- CSV reading and conversions of tables to PyKX objects now allows users to specify the target types of their objects (Licensed mode only)
- Addition of a serialize and deserialize method allows users to convert pykx objects to q IPC format directly – this is particularly convenient for users interacting with KDB.AI or kdb Insights Enterprise.
- License Management improvements included for their validation, tracking and installation/reinstallation
- Random Data Generation similar to NumPy has been added
- A facility for registering custom conversions which makes it easier to pass complex Python objects to q.
- Users can run an apply method on pykx.*Vector objects
- Selective cast of columns available in pykx.toq make it possible to override default mappings
Discover more information on these and other features.
Future Plans
Further enhancements will target the following areas:
- Continued expansion of Pandas-like API
- JupyterQ migration to PyKX
- DB Maintenance functionality
- Performance improvements by expanding use of cython
- Enhancements to type-conversion logic
- Improvements to CSV-reading utilities
- Additional Pythonic options for query
- Python 3.12 support
A Customer Endorsement
Finally, what better endorsement of a product than the words of a customer. Watch Citadel discuss their use of PyKX at this year’s KXCON event.
Try PyKX
The PyKX interface operates on Linux, Mac, and Windows and is now open source and open access from the following locations:
- PyPi: org/project/pykx
- pip install pykx
- Anaconda: https://anaconda.org/kx/pykx
- conda install pykx