









For developers working in large-scale AI search, high-dimensional embeddings have always been a challenge — demanding massive storage and computational resources. But the game has changed. Matryoshka Representation Learning (MRL), and the new jina-embedding-v3 model, are rewriting the rules.
128D embeddings that perform like 1024D
With the MRL-tuned jina-embedding-v3 model, you get near-full performance of 1024 dimensions packed into just 128. Even more remarkably, you retain most of that performance at just 64 dimensions. Here’s why this matters:
- Single-machine scalability: Imagine searching through hundreds of millions, or even billions of embeddings on a single high-end server—no distributed cluster required. MRL makes this possible
- Storage reduction: Combine MRL with binary quantization, and you get up to 32x memory savings on top of dimensionality reduction. A 1024D float32 vector (4KB) becomes a 128D binary vector (16 bytes) — a staggering 256x reduction
- Faster query speeds: Lower dimensions mean exponentially faster similarity searches. The issues with dimensionality in kNN search? Significantly mitigated. Quantizing vectors is a great strategy for reducing search latency at any scale, not just hundreds of millions of vectors
- Accuracy retention: Retrieve 2-3x more candidates and rerank, all while keeping overall performance ahead. Oversampling and reranking let you balance efficiency with accuracy. We can think of the oversampling rate as a hyperparameter. If we are incorporating a reranker, then the goal is to simply maximize recall!
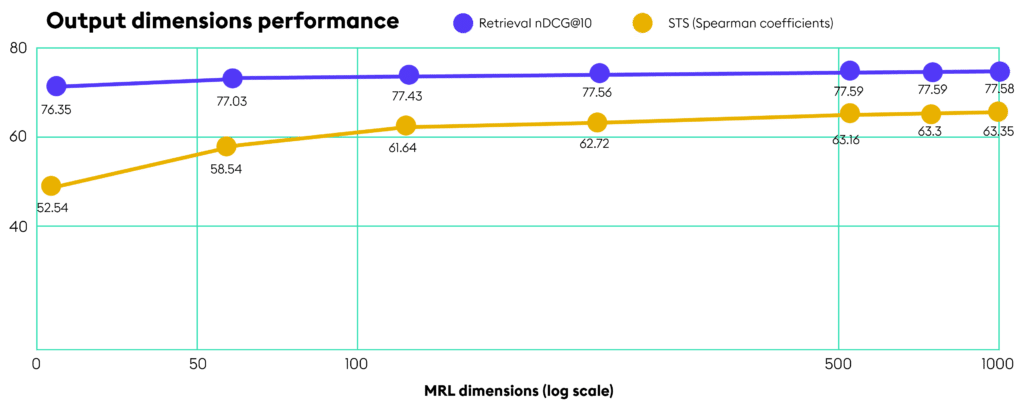
Image adapted from Jina.ai blog
How does MRL work?
The concept is simple but powerful—much like the Russian nesting dolls it’s named after. MRL prioritizes information within the dimensions, storing critical details in the first M dimensions, and gradually less critical details in subsequent ones. This allows for truncation without significant information loss.
Every subset of dimensions (8, 16, 32, 64, 128, etc.) is independently trained to effectively represent the data point, enabling adaptive computation: fewer dimensions for speed, and more for precision.
Real-world efficiency
The original Matryoshka learning paper resulted in the following performance improvements:
- Up to 14x smaller embeddings for ImageNet-1K classification at the same accuracy level
- Up to 14x real-world speedups in large-scale retrieval tasks
- Up to 2% accuracy improvement for long-tail few-shot classification
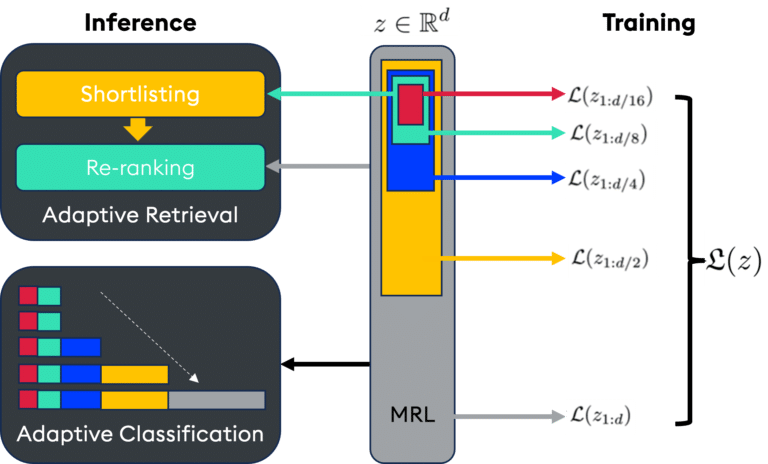
Image adapted from Matryoshka Representation Learning Paper.
MRL works across web-scale datasets and different modalities, from vision (ViT, ResNet) to vision+language (ALIGN) to language (BERT).
But Jina AI went even further:
Their jina-embedding-v3 model is a frontier multilingual embedding model with 570 million parameters and 8192 token-length support, achieving state-of-the-art performance on multilingual data and long-context retrieval tasks. It outperforms the latest proprietary embeddings from OpenAI and Cohere on the MTEB benchmark, showing superior performance across all multilingual tasks compared to multilingual-e5-large-instruct.
jina-embedding-v3 features task-specific Low-Rank Adaptation (LoRA) adapters that enable it to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching. Thanks to the integration of MRL, it allows flexible truncation of embedding dimensions without compromising performance.
jina-embedding-v3 supports 89 languages, making it a powerful choice for multilingual applications. It has a default output dimension of 1024, but users can truncate embedding dimensions down to 64 without sacrificing much performance.
Implementation insights
- Existing index structures like HNSW and IVF work seamlessly with these embeddings
- Vector databases could soon support dynamic dimensionality selection at query time—no reindexing needed
- Search at lower dimensions, then rerank with higher-dimensional embeddings stored on disk—reducing costs and boosting efficiency
- Fine-tuning models with MRL can yield even better performance for specific tasks
- Mix and match quantization methods—you can use int8, binary quantization, or product quantization with a truncated MRL vector for even better performance
Rethinking AI search at scale
For many large-scale applications, those bulky 1000+ dimension embeddings are becoming a thing of the past. This isn’t just a step forward; it’s a fundamental shift in how we approach vector search. Before, to search 100M embeddings you would need an entire machine learning team and tens of thousands to spend a month. Now a single developer can build an effective search system at that scale in just one day!
It’s important to note that not all embedding models are trained with MRL, so you can’t always truncate and expect good results. However, that is the case with OpenAI embeddings for example, which is why truncating OpenAI’s text-embedding-3-large model to the size of the text-embedding-3-small model usually results in better performance than just using the small model!
If you’re not exploring low-dimensional embeddings for your search infrastructure at a certain scale, you’re leaving serious performance gains on the table. I dive deep into this topic, sharing successes and hard-learned lessons in my latest ebook, “The ultimate guide to choosing embedding models for AI applications”. The future of vector search is not just about embedding precision—it’s about efficiency, scalability, and smart adaptation.



