








Many industry observers believe that we’re in the middle of another industrial revolution. We’re seeing the digitalization of business processes and operations, and transformation in how goods and services are designed, produced, and delivered. As part of this transformation, organizations are moving to self-healing systems where automation is used to reconfigure networks, systems, and processes improving availability, reliability and quality of their services and products. Together with the exponential growth of data from sensors and connected devices, organizations have to manage the increasing pace of change in configurations and the relationships between devices, users, and business processes.
In order to be able to gain business insights and make decisions in this rapidly changing environment, organizations have to represent data from their assets and environments across many dimensions of time. This also involves multiple data sources that need to be correlated, analyzed and aggregated. This is necessary in order to able to answer questions such as:
- How are my network and my assets performing and what contributed to this performance?
- How did they perform in the past, and how is it likely to perform in the future?
- What and how many resources were consumed last month based on measurements received on the first day of the following month?
- What data was used two months ago for preparing a report?
It is striking how similar these questions and challenges are to the time-series data management and analytics challenges that the capital markets industry has had to address over the past 20 years. In particular, the ability to go back in history and replay trading activity, stock splits, mergers, and assess whether insider information was used for a particular trade, involving large amount of data has been common. This paper draws on some of these experiences and how KX technology has been applied to address them.
It’s About Time
The reference to time in a system is crucial for identifying and prioritizing what is important, what is changing, and providing context about the objects in an environment, such as assets, sensors, networks, contracts, people and relationships at a particular instant.
How you represent time in a system and its data model is critical to be able to answer the types of questions above. Essentially you need a data model that stores and facilitate analysis of data across two dimensions of time – a bitemporal data model. This model stores more than one timestamp for each property, object, and value, such as:
- Valid Time: Beginning and ending time for the period that the property, object and value was applicable.
- Transaction Time: The time on which the assertion is made or when information is recorded in the database or system.
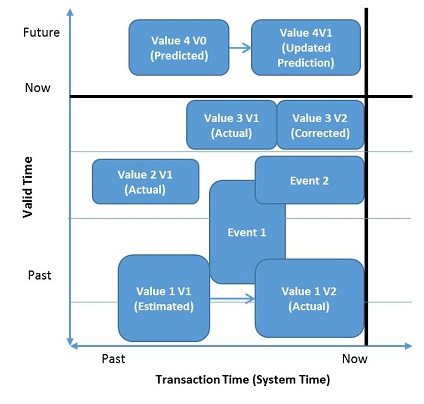
When working in a real-life environment, you may get corrections to previously processed data, resulting in multiple versions of data for a transaction for a “valid time” period. By storing all of the transaction times and their version information it becomes possible to distinguish between different versions of data for better analysis and decision making. With this information it is possible to run reports or analytics on data at different times and to get the same result. This is critical for investigating issues, regulatory reporting, and having a consistent set of information for making decisions.
For example, in order to make a decision as to whether equipment should be maintained, fixed, replaced or updated with new configuration information, you will need to assess what variables contribute to its performance at different points in time – such as configuration, the environment, as well as quality and performance metrics for the same period in time.
Benefits of bitemporal data models
There are some significant business benefits of bitemporal data models. They enable you to easily and quickly navigate through time as follows.
- Analytics: Perform queries that relate to what was known to the system at a particular point in time (not necessarily now)
- Continuous analytics: Avoid the need to pause or stop data processing or take snapshots of databases to perform point-in-time aggregations and calculations
- Integrity and consistency: Deliver consistent reports, aggregations, and queries for a period at a point in time
- Deeper insights and decisions: Support machine learning and predictive models by incorporating accurate state of the system, relationships and time-based events and measurements
- Auditability and traceability: Record and reconstruct the history of changes of an entity across time, providing forensic auditability of updates to data
Implementing bitemporal data models
Organizations that have attempted to implement bitemporal data models with traditional technologies have been faced with some surprises and significant challenges, including:
- Limited analytics. Limited to no support for linking data sets, known as joining tables, made analytics more complex and time-consuming, requiring data to be moved to other systems for analysis; Storing only a single time for properties, objects and values, results in an inability to analyze history;
- Poor performance. Long running queries and aggregations involving filtering and selecting large volumes of data based on time; analysis is performed at the application layer requiring large volumes of data to be transported from the database to the application;
- High storage costs. Additional storage is required to store and index time records, and multiple copies of database required to support point-in-time analysis and reporting;
- Restrictions on updates. Supporting only appends to existing data requiring restrictions or workarounds to work with changes to data.
With KX’s experience in implementing bitemporal data models on high-velocity and high-volume data sets, such as applying complex algorithms to high-volumes of streaming market data to make microsecond trading decisions, we recommend that organizations look at solutions that have the following characteristics:
- Support for time-series operations and joins. For analyzing time-series data, the solution needs to support computations on temporal data, and joining master/reference and multiple data sets. KX’s native support for time-series operations vastly improves both the speed and performance of queries, aggregation, and the analysis of structured and temporal data. Some of the operations include moving window functions, fuzzy temporal joins, and temporal arithmetic.
- Integrated streaming and historical data. A solution that supports both streaming and historical data enabling both data sets. KX provides an integrated platform and query facility for working with both streaming and historical data using the same tools.
- Integrated database and programming language. A solution that enables efficient querying and manipulating of vectors or arrays, and developing new algorithms that operate on any size time-series data sets. KX provides an interpreted, array-based, functional language with an interactive environment suited for processing and analyzing multi-dimensional arrays.
- Columnar database. A solution that stores data in columns (versus rows common in many traditional technologies) to enable very fast data access and high levels of compression. KX stores data as columns on disk, and supports the application of attributes to temporal data to significantly accelerate the retrievals, aggregations and analytics on temporal data.
- In-memory database. A solution that incorporates an in-memory database to support fast data ingestion, event processing, and streaming data analytics. As KX’s kdb+ is both an in‑memory and columnar database with one query and programming language, it simultaneously supports high velocity, high volume and low latency workloads.
Case Study Examples
The following are some examples of organizations who have implemented bitemporal data models using KX technology.
- An energy utility company gained visibility into conditions that contributed to how smart meter data was processed at a point in time, and then took corrective actions to improve data quality. The use of a bitemporal data model together with KX, enabled analytics to be performed on the master and time-series data that were in the system at a point in time.
- A financial services regulator improved market monitoring and investigations by being able to rapidly replay market and stock trading on major exchanges for fraudulent activity, and to trace behaviors over time for subsequent investigations.
- A financial transaction processing service provider enabled high service availability for competitive advantage by enabling processing to continue at same time as ingestion, and accelerating analytics from many hours to a few minutes.
- A high-precision manufacturing solutions provider significantly accelerated ingestion, processing and predictive analytics of sensor data from industrial equipment, while reducing license and infrastructure costs.


