








By Bill Pierson
Buzzwords are chosen to impress in the changing technology world. Back in 2014, ‘Big Data’ hit its buzzword peak per Google keyword searches. Today ‘Machine Learning’ keyword searches appear on top. What does this all mean? While buzzwords are too general to mean much to any specific market, the shift from ‘Big Data’ to ‘Machine Learning” reflects the shift from managing Big Data to making decisions with this Big Data. In today’s fast-moving world, a competitive advantage is to make the correct decision faster than somebody else. How fast somebody can use Big Data to make those decisions is the real opportunity. In manufacturing, being fast can be to increase product yield and to reduce equipment costs.
KX has been solving Big Data use cases for over 20 years, long before ‘Big Data’ was a buzzword. KX’s focus is not only on the volume of data, but also on the velocity, or speed, of the data. As evidenced by tick data (successive price and quote changes) in the financial markets, making a decision using advanced algorithms within a few milliseconds enables KX clients to have a competitive edge. Processing sensor data in the IoT world, including the high tech manufacturing industry, is very similar to high-frequency trading. Both are essentially signals and just have different contexts and labels across some dimensions of time. One such example is the semiconductor manufacturing industry dealing with several thousand tools in a single factory, each producing in excess of 500 signals per individual chamber at kHz frequencies. This adds up to many terabytes per day of data from measurements including gas flows, voltage, current and temperature which must be stored and used to establish and update limits for real-time alerts to the engineers and factory. This does not yet include the many other signals being managed in the facilities of these tools and production lines such as pumps and scrubbers.
KX started in the semiconductor manufacturing industry by providing FDC (fault detection and classification) solutions, a critical and relatively simple form of alerts using signal or sensor data. FDC’s foundation is based on SPC (statistical process control) systems that work to identify out-of-control excursions but works instead with high volume and high-velocity streaming and historical sensor data to analyze signals, determine deviations, and diagnose faults, or excursions, to adjust the process or tool. KX works with several leading fault detection providers to help them with the speed their customers need to ultimately improve product yield and lower equipment costs. Each of these fault detection providers starts with the raw signal data with a goal to diagnose the fault that could interlock or hold the product wafer or tool and finally provide corrective action. Some applications from these providers will use business rules, some will develop complex analytical and machine learning algorithms, and others will aggregate the raw signal data into a condensed set of actionable metrics.
The common thread for each of these is the need for speed in managing and making decisions using Big Data. Customers need the speed to interlock the tool or product wafer to minimize the risk in damaging the next product wafer or the tool itself, to characterize variations and decide on immediate next steps using the combined real-time and historical data, and finally to develop models and strategies such as predictive maintenance techniques to improve their yield and lower equipment costs. Previously they may have to wait for the end of lot/run to interlock the tool or product wafers, setup queries to run overnight, or wait many hours to create and validate models using their legacy systems. They all found KX technology to be the best to deliver the required speed performance improvements. The lessons learned using FDC in semiconductor manufacturing are directly applicable to other industries that will later need similar solutions in managing high volume, high-velocity data while making fast real-time decisions. There are a number of articles including independent benchmarks that highlight KX Technology speed performance such as NY Taxi Ride data or a transitive comparison based on competitor benchmarks.
So the obvious question comes up – Why is KX Technology so fast? This should be broken up into two specific questions about the kdb+ database product. 1) Why is kdb+ so fast for data ingestion? 2) Why is kdb+ so fast for calculations and queries?
Why is kdb+ so fast for data ingestion?
Data is first placed in in-memory table(s) using a prescribed schema and protected through an on-disk log. By going to memory first and making data available immediately to query it enables KX to support much higher ingestion rates of many millions of readings per second, which translates to many terabytes per day on a single server. As memory is consumed, data is migrated to a temporary table(s) on disk called Interval Database (IDB) and once a day is organized and sorted into more permanent storage which can utilize tiered stored media. In the KX world, we call these the Real Time Database (RDB), Interval Database (IDB) and Historical Database (HDB). The KX ingestion process exploits the performance advantage of sequential write operations to disk using our library of API calls without the need for transaction overhead and making data immediately available from memory. This architecture is ideal for the various FDC use cases: real-time control using streaming data such as interlocking the product wafer or tool, real-time analytics to characterize variations and control using the combined streaming and historical data, and analytics to develop models and techniques such as predictive maintenance using historical data.
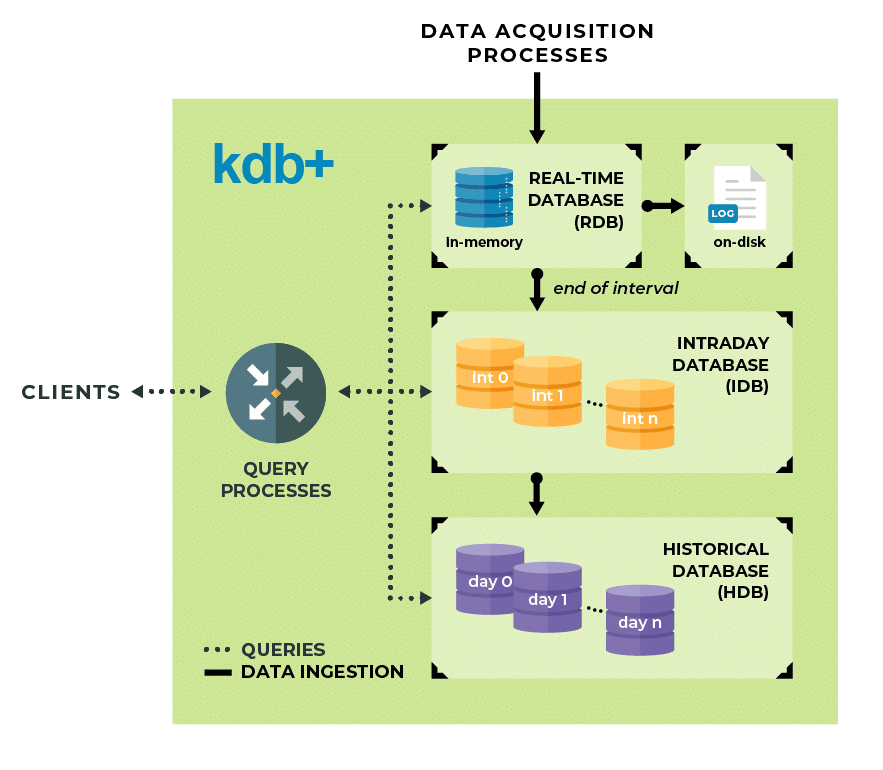
Why is kdb+ so fast for calculations and queries?
Vector programming and a query language in a small footprint (800 KB) are aspects of what makes it fast. Their combination makes it even more powerful together as the small footprint allows the full scope of operations to reside in the fastest area of the CPU (L1/2 cache) so ALL operations exploit its speed inherently. The vector approach allows you to do many more simultaneous operations within a single operation of the CPU, reducing the number of overall operations required to obtain results. For example, one can operate on multiple data points at the same time and eliminate the need for having an operation on each piece of data. These calculations can occur in our Complex Event Processing (CEP) engine prior to ingestion to the in-memory database, consuming only a few milliseconds.
In contrast to other database technologies, we have an optimized data storage which uses a columnar representation of data that is much more efficient for queries as you retrieve the columns and rows of data you need, versus the entire row or object common. You get only what you need from a query, by targeting only the columns required, and not having to scan and retrieve full rows of data with many columns that aren’t required. The storage architecture uses memory-mapped files that are identical to in-memory and on-disk. This eliminates CPU operations required for translating on-disk objects to in-memory objects common with other technologies. The kdb+ analytics architecture is focused on performing all computation operations in the database, without the need to move data over a network or to another computation and analytics layer. KX’s calculation/query design enables FDC systems to analyze streaming data as it comes in for immediate actions, to combine historical data with in-memory data seamlessly for quick characterization and modeling use cases, and perform lightning-fast computations using our vector programming and qsql query language in the CPU cache.
As people continue to use buzzwords moving from Big Data, Age of AI, to Cognitive Computing, I would like to remind us of the quote, ‘The world’s most valuable resource is no longer oil, but data’ from the Economist in 2017. And like oil, the data alone is not what is important – it’s what we do with it that is. I would argue that everyone working with Big Data, AI, or Cognitive Computing is challenged by the need for speed so that they can act on this data quickly. Therefore, the most appropriate buzzword is really ‘Fast Data’. Kdb+ is a proven technology that can be used to manage Big Data and make fast decisions.
Bill Pierson is VP of Semiconductors and Manufacturing at KX, leading the growth of this vertical. He has extensive experience in the semiconductor industry including previous experience at Samsung, ASML and KLA. Bill specializes in applications, analytics, and control. He lives in Austin, Texas, and when not at work can be found on the rock climbing cliffs or at his son’s soccer matches.


