By Tim Thornton
Introduction
Testing is a critical part of any project to ensure code meets specification, quickly detect regressions and provide useful examples for future developers to understand. This article examines the testing tools in KX Analyst, and how they may be used to ensure that code is correct, efficient, and resistant to the introduction of defects as it is further developed.
In the previous articles in this series, we have shown how to ingest New York taxi data into a kdb+ database, visualize the data to understand the underlying distributions and relationships, and perform an initial analysis looking for return taxi trips within the data. When identifying return taxi trips, we made use of the haversine function. Since this function could be useful in other projects, we will outline considerations in re-engineering it into a library. In doing this, we will add tests and benchmarks so that we have assured the code works and performs efficiently.
Unit Testing
As we saw in the previous article, the haversine function computes the shortest distance between two points on a sphere. We made use of this function to identify return trips in New York taxi data. We now want to add test coverage for this function to ensure it continues to perform as we expect, even after making additional changes.
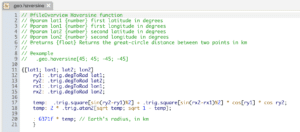
The most basic way of testing a function is with unit tests. A unit test consists of an example input to the function, along with the expected output that can be tested in isolation from the rest of the system. Along with the code to perform the test is a description stating what feature is being tested and what the expected behaviour is. A future reader or developer can interpret the meaning of the test rather than just an explicit input-output example. Behaviour-Driven Development (BDD) practices allow tests to be organized in terms of the behaviours each feature should exhibit, drawing on natural language to describe the tests.
qcumber
KX Analyst includes a BDD test framework called qcumber for declaring and running tests. In the qcumber test file below, we describe the haversine feature, along with some basic behaviours, known input/output pairs, and basic tests for edge cases and extremes. Before any of the tests are run, a simple definition of some known cities is set up (the before block). After the test is run, the definition of cities is removed in order to clean up the side-effect of declaring a new identifier (the after block). A good unit test should leave the environment in the same state as it was before the test was run. Not doing so may have an impact on any other tests being run in sequence by adding or removing definitions, changing behaviours by stubbing functions, and updating global variables.
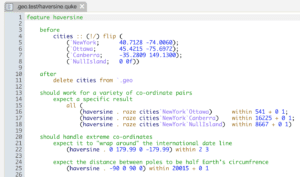
Within a qcumber file, a should block declares that the feature (i.e., haversine) should exhibit some behaviour that we want to test. Each should block contains one or more expect blocks which are assertions relating to the behaviour. If any of these assertions were to fail, either by erroring or returning a value other than true, the test of that feature would fail.
When we run this test file from the IDE (right-click > Test), we are notified that all tests are passing.

If our test coverage is thorough, new bugs introduced in the future would be caught by the test cases.

Property-Based Testing
Going one step beyond unit testing, property-based testing allows developers to assert high-level properties about their code, rather than the explicit input-output behaviour checked by a unit test. A property is a relationship between the input and output.
For example, in the unit tests above, we have a test asserting that the shortest distance between the earth’s poles should be equal to half the circumference of the earth. Since that should be the maximum distance returned, we could encode this idea as a property of our function. If any result were greater than this value, that would be an invalid result.
QuickCheq
KX Analyst includes a property-based testing framework called Quickcheq, which can be run within qcumber test files or as a standalone library. The property test added to the qcumber test file below runs, by default, 100 times on random inputs as specified by the first four arguments to .qch.forall4 (the constructor for a four argument property). Each property constructor takes generators which describe the possible inputs as the first set of arguments, and the property itself as a function as the final argument.

If we run the test file now, we have some confidence that this property holds as qcumber reports “4 tests passed “- i.e. our three unit tests and all 100 runs of our property test have passed. This is, of course, random testing and not exhaustive, but covers a lot of ground quickly. It also concisely encodes the property or idea that the programmer had designed, which would otherwise be obfuscated by the number of individual unit tests it would take to encode the same property. Encoding these properties prior to and during development also forces the programmer to take a step back and think at a high level about the algebraic interaction between the components of their API. To demonstrate, a property on reverse describing the interaction between join (,) and reverse would be as follows:
.qch.forall [.qch.g.list[]; .qch.g.list[]] {reverse[x,y] ~ reverse[y],reverse x }If this property fails to hold after some edits in the future, our tests will alert us and we can run .qch.summary on the failing line to get more information:
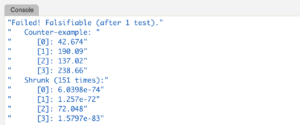
In the above output, the first failing arguments are displayed. In addition, the arguments are reduced to much simpler arguments (here, close to 0 rather than the original random floats that failed) to aid in tracking down the root of the problem. We can see the property failed after the first attempt, indicating it took very little effort to find a set of failing arguments for this property.
The random generators in QuickCheq are quite expressive. In particular, the generators for asserting properties on top of arbitrary table formats (in-memory, splayed, or partitioned), are especially useful for testing q libraries in order to catch any differences in behaviour between these table formats.
Benchmarks
In addition to tests, the qcumber testing framework also enables performance benchmarks to be declared. Since a primary use of our haversine function will be for analytics on tables, we should include a query benchmark in our test suite.
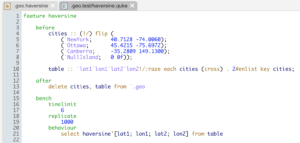
This test runs 1000 times and reports whether the query took less than 6ms (the timelimit declared in the test) on average for the 1000 runs to complete.
We can do better. By taking advantage of the performance behind the vector operations in kdb+, we should be able to remove the each (‘), and run over the raw vectors.
/ from:
select haversine'[lat1; lon1; lat2; lon2] from table
/ to:
select haversine[lat1; lon1; lat2; lon2] from tableAfter making the change above and running the tests again, we are alerted that something didn’t work.
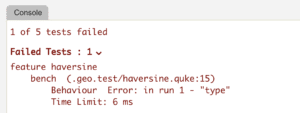
Examining our haversine implementation, the only non-vector code is the use of .trig.atan2, which only accepts scalar arguments. If we wrap the use of atan2 in a conditional and run the tests again, the tests pass and the benchmark is indeed faster.
temp: 2 * $[0>type lat1; .trig.atan2; .trig.atan2'][sqrt temp; sqrt 1 - temp];We can now lower the timelimit in the benchmark to ensure we don’t regress on this performance increase in the future.
Automating
In addition to running the tests from the IDE, qcumber is also available as a standalone library to automate the running of tests outside of KX Analyst. Running the tests using the library provides a host of useful information, including all passing and failing tests, line number in the test file, any error messages, and run time for benchmarks.
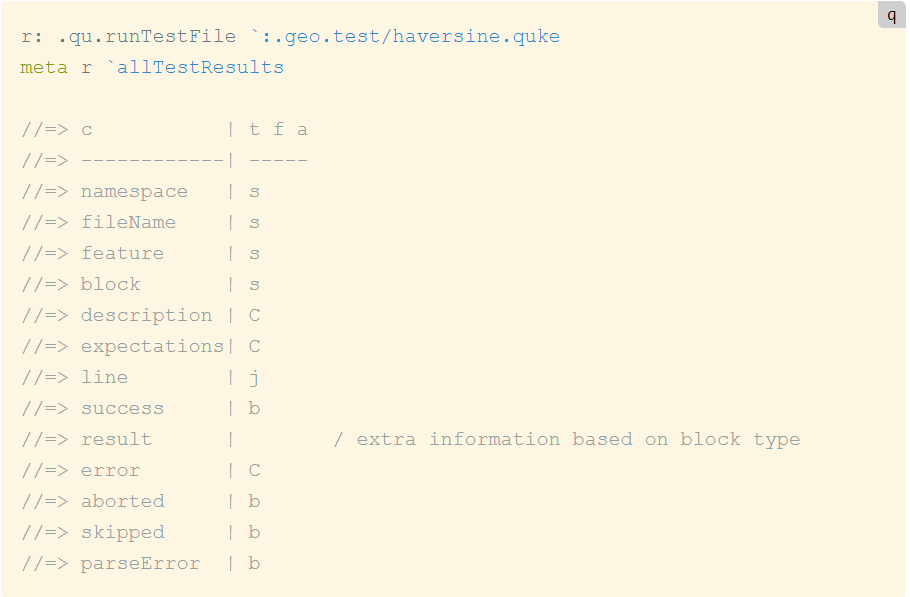
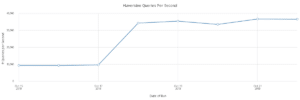
If we were to save these results to a kdb+ table during an automated build job, we would create a history of test and benchmark results which can be inspected in the future. For example, querying for the benchmark times of each qcumber run, we can see the performance impact of the previously discussed change made to haversine to make more efficient use of kdb+ vector operations.
Conclusion
By making use of the unit tests, property tests, and performance benchmark specifications supported by the qcumber framework in KX Analyst, we can be confident that the function will perform as intended and to the required performance levels. With these tests in place, we can guard against defects resulting from future optimizations or changes. Historical benchmark performance data, when combined with the git-based version control system in KX Analyst, allows the performance impact of specific changes to the code to be evaluated by associating git commits with benchmark changes.