By Ferenc Bodon PhD.
KX guest blogger Ferenc Bodon is an expert kdb+ programmer and an experienced software developer in several other programming languages, as well as a software architect with an academic background in data mining and statistics. KX has previously re-published another article by Ferenc, A comparison of Python and q for data analysis. Follow Ferenc on LinkedIn, where he writes about programming language comparisons and originally published this article with the title Lists – Python and Q side-by-side .
Python and q are two world-class, dynamic programming languages with many similarities and some interesting differences. Python is a general language with specialized libraries for different fields like web and mobile development or data analysis. Q is primarily used in the financial industry for data analysis and developing trading algorithms. On Wall Street, people often use these tools side-by-side, sporadically with R and Matlab.
The symbioses of Python and q developers demanded new tools to bridge the gap. Q users can import embedPy to call Python functions which opens the world to a rich set of machine learning algorithms. Python fans can experience the performance gain of q by loading PyQ and bringing the Python and q interpreters into the same process so that code written in either of the languages operates on the same data. The embedPy and PyQ libraries reduce integration costs by offering two languages in one interpreter. Still, to become a successful developer, you need to know what expression corresponds to your codeline in the other language. This article helps you with this.
The list is the most fundamental data structure in programming. In this article, I will compare how the two languages handle lists. This comparison is useful for q programmers who would like to pick up Python and play with, for example, built-in machine learning algorithms. Python developers will also benefit from the comparison especially if they are interested in making good money and finding a job in the financial industry where data warehouses are often built on top of q/kdb+.
Here I will not cover Python Numpy library that extends native lists with several useful features. Comparing Numpy to q’s list deserves a separate article.
Similarities
In both languages lists can be heterogeneous, i.e. they can contain values of different types, even lists. Square brackets are used for indexing, indices start from 0. You get an exception and null value if you index out of range. As expected from high-level programming languages, you don’t need to care much about memory management, lists can grow dynamically. You can easily get the length of a list, see if a value is contained and check the equivalence of two lists.

You can reverse a list and get (first/last) part of the list.

Similar functions are available for lists of numbers

to performing aggregations and accumulation (via libraries itertools and operator in Python).

and to concatenate lists of strings with a given delimiter or split a string

The underlying list implementation, i.e. data structure used, is determined by the optimization goal of the designers. The goal was the same for both languages, provide fast indexing, hence variable-length arrays/vectors of pointers were used.
Major differences
Python supports immutable lists, called tuples. In q all arrays are mutable.
Q differentiates between heterogeneous and homogeneous lists (aka. simple list in q terminology). Creating simple lists requires less typing by omitting all separators. This sounds negligible at first, but if you work a lot with lists, then it will boost your productivity.
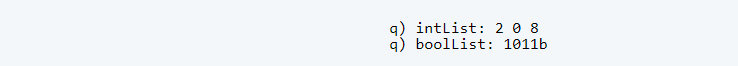
Simple lists are stored in variable-sized arrays instead of a pointer array. Python also supports typed, dynamically growing arrays by the class array but you need to specify the type of the elements at object creation time. The class array is not a widely used data structure.
If you have a heterogeneous list and you modify it so that all elements have the same type then q converts it to a simple list under the hood. This can have unexpected consequences that look alarming at first sight but that payback when it comes to performance.

Creating a list of size one (singleton) requires extra typing and usage of the keyword enlist. This is the result of parentheses being used for list demarcation and also for grouping in mathematical expressions.

Creating immutable singletons also have some extra quirks in Python

Modification
Appending new elements may result in resizing. Inserting into or deleting from the middle is slow, Q tries to discourage developers doing this by not providing an elegant solution for this operation

You cannot use function append to extend the list with multiple elements. There is another function for this called extend. Q does not need any new function for this simple operation. Function extend accepts any data structure that is iterable, for example, a dictionary. A minor difference between Python and q is that Python appends keys of a dictionary, q appends the values.

Indexing
In Python, you can use a negative index to access the elements from the end of the array. So you can use -1 to access the last element, and -2 to access the second to last element, and so on. In q you can’t do this.
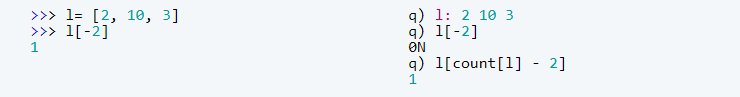
On the other hand, in q it is permissible to leave out the brackets and it accepts lists for indexing. The two features can be combined.

Q also provides some syntactic sugar for accessing the first and last elements. Namely the first and last functions. This is often quite handy, for example, to get the first element of each list of a list and you would like to use the functional programming feature of the language.

Nested lists can be indexed by listing the indices in square brackets. Q helps developers save typing.

Eliding an index in any slot is equivalent to specifying all possible indices for that slot. You will be pleased by this feature if you work a lot with matrices.
![]()
Q accepts lists for indexing, just use the dot. What’s more, you can pass a list of lists. Don’t even try this in Python. There exists no elegant solution.

Operators + * < not
Let us start with operator plus (+). It means list concatenation in Python and element-wise addition in q. This is acceptable… as long as we don’t contemplate on what we expect from operator minus (-). We expect operator minus to be the inverse of operator plus, hence (x + y) – y to be equal to x. This is true for q but not for Python. What do we expect from concatenation (denoted by a comma in q)? Well, we should be able to concatenate list to a list, scalar to a list and list to a scalar. Again, only q meets the expectations.

Operator * means repetition in Python. This is probably not a functionality that any developers would often need. List repetition can also be achieved in q in several simple ways

Comparison operators reflect lexicographic ordering in Python. In q sorting-based functions use lexicographic comparison for a list of list as input. Function iasc with parameter l returns the indices needed to sort list l in ascending order. I leave it to the astute readers to figure out why the two approaches below are equivalent. Bear in mind that operations are evaluated from right to left in q.

Function iasc comes handy in sorting if you would like to use a function to be called on each list element prior to making comparisons. Let’s sort a list of lists by the length of the inner lists.

Unary operator not is used for checking emptiness of a list in Python. If you are disciplined on following the Zen of Python’s that includes “Explicit is better than implicit” then you can employ an extra len function. A similar approach is recommended in q.

Element-wise operations
Q is a vector programming language so we expect the element-wise operations to be well supported. Python also supports this by function map. You just need to type more and the expressions are less intuitive for non-Python developers.
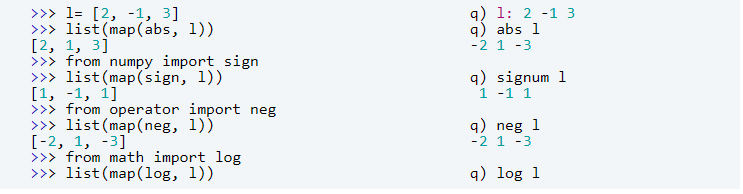
Note that in Python to get absolute, negate, sign and logarithmic of a value you need to use Python core and three additional packages. You definitely need a cheat sheet to remember that.
Adding, subtracting, multiplying, dividing or comparing two lists of the same size should be done element-wise. Also, we should be able to build up arbitrary arithmetic formulas. In Python, you can avoid lambda expression for basic operators if you import the library operator (or using list comprehension with command zip).
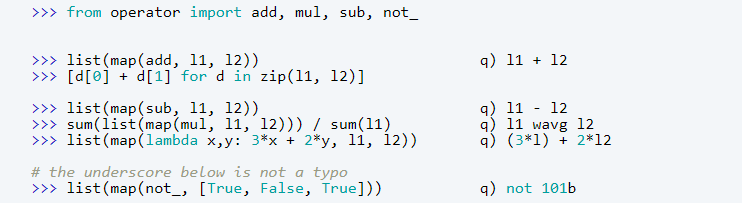
You have multiple choices in Python for operators including a scalar and a list. Beginners and developers from procedural languages will probably use list comprehension. People who enjoy using myriad features of a language will use the map with lambda. Gurus of functional programming will vote for map with a mixture of functions available in modules functools and operator. In q it works out of the box

Python lists are not suitable for arithmetic operations. They are hard to use and laborious to maintain. Python package Numpy was introduced to overcome these barriers.
Memory management
In Python assignment operation on a list creates a reference only. Separate functions exist for copy and deep copy (underlying objects are also copied). In q copy is done on a write operation.

Python bugs are caused by developers forgetting about the fact that pointers are stored in the lists not values. Q’s approach is less prone to error. Let me illustrate this with an example.

Element lookup
We already know that in both languages determining membership is achieved by function in. It requires a scalar and a list as parameters. If two lists are provided then q checks membership of each element of the first list. Python, on the other hand, checks if the list itself is contained as a member in the second list. Both behaviors can be achieved in the other language as well… not necessarily elegantly.

Let us go further and find the index of an element. Again, q handles if a list is provided instead of a scalar.

Both languages support binary search in sorted lists. Python requires package bisect. If the value is not contained in the list then functions return index of the position before (after) which the key can be inserted so that the list remains sorted.

We can look for the number of times a value occurs and can look for the indices of occurrences.

Q function where can also be used to select elements of a list based on a bit vector or a monadic function that returns a bool. In Python, you need to import library itertools for a bit vector and use function filter for a bool function (or use Numpy, in which function where was also introduced). Sad to see that the two very similar tasks require completely different solutions in Python (also observe the confusing parameter orders of functions compress and filter).

Let us further generalize index finding and get all occurrences of all elements into a dictionary. Q provides a simple function called group. In Python, you cannot achieve this with a oneliner. To get a simple solution you need to use dict.setdefault or import collections library’s defaultdict.

Set operations
Determining the intersection and union of elements of two lists are general set operations. Python has a separate class for sets, but developers often need to perform a set operation on lists as well. Let us compare the two languages in this respect.

Attributes
Q may automatically assign metadata called attributes to a list. For example, a list created by function asc gets attribute sorted (`s). You can also stick the attribute to a list manually. Attributes allow performance optimization on several occasions. Calling function asc on the list returns immediately and the linear search is replaced by binary for a few operations like inclusion, equality, find, etc. You can append new elements to your sorted list, q will check if sorting criterion holds and automatically removes the attribute if the assumption is no longer valid.
Attribute unique allows early exit from some operations. Attribute parted and grouped maintains a secondary data structure that is used for performance tuning e.g. in searching.
Matrix operations
Matrices can be implemented by nested lists. Q supports matrix operations like inversion, multiplication, finding the least-squares solution, the dot product of vectors. No external library is needed. The recommended way to handle matrix operations in Python is to use yet another data structure ndarray provided by yet another package Numpy. We don’t cover Numpy in this article, the below code samples are for illustration.

Q freebies
Further functions are available in Q that operates on lists and data scientists find them very useful. Some operate on consecutive items, like functions deltas/ratios to get difference/ratio to the next item or function differ to see if next item differs at all. Q also supports calculating moving aggregate statistics, like count, sum, average, deviation, max, min and exponentially weighted moving average by functions mcount, msum, mavg, mdev, mmax, mmin and ema respectively.
Miscellaneous
Unpacking refers to assigning values to multiple variables in a single expression based on a list. Python’s solution is more intuitive and also works nicely on local variables.

Sometimes we need to flatten a list of lists to create a single list. The most elegant way to do this in Python is to use package itertools. In q we can use raze.

But again, the typical nuisance, Python will not handle properly if any element is a scalar. For q, it is just not an issue.

Cartesian products of two lists are supported natively by q and you need library itertools for Python.

Performance
Q is known for its outstanding performance. It is a widespread tool in the financial industry to analyze big data. Python’s strength is less the performance. In both languages, lists are implemented by pointer arrays so we don’t expect much difference in execution times. My measurements support this theory. Execution times differ significantly only in looking up multiple elements where the simple Python solution has worse run-time complexity.

Let us see the performance of operations on homogeneous lists. Python class array is more similar to q’s homogeneous list than Python’s list, so I included this alternative in the experiments. For completeness, I also measured execution times of Numpy equivalent functions like np.isin and np.union1d. I did not use q attributes to get any performance gain.
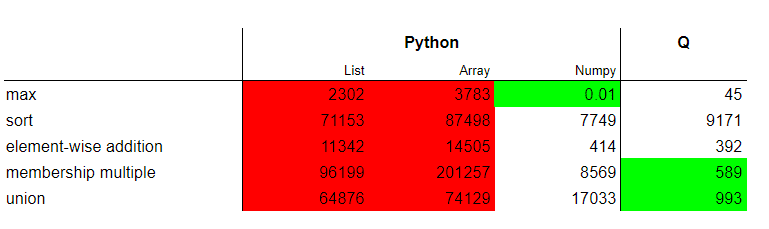
This is a knock-out for Python. Q is often two orders of magnitude faster than Python. This is a show stopper for Python lists when it comes to processing big data and long vectors. Numpy improves performance but using it efficiently is almost like learning a new programming language. Q does the performance optimization behind the scenes and helps the developer focus on the business logic.
Verbosity
I am a big fan of clean code. Every single line of code should be as simple as possible, but not simpler. If you look at the code snippets above you will probably feel that this holds for q in most cases and holds for Python in some rare cases. Code like

is cleaner than

Cleaner code is easier to read, hand over to other team members and debug. Let us compare a few statistics about the code in this article.

Clean code means less noise. Parentheses are noise unless they contribute to the understanding. Although modern IDEs support parentheses handling in most examples above they distract developers and decrease productivity.
Conclusion
Q’s list support is better than Python’s solution in all aspects. It is simpler, faster, easier to use, requires less typing, its API is better designed. You can achieve more with less typing and fewer keywords – its cleanliness and expressiveness are superior to Python’s lists. Q simplifies programmers’ lives by handling lists and scalars exactly as programmers expect. In Python, you often need workarounds as a scalar and a list of size one are not interchangeable. Q makes developers’ productivity and performance the primary goals.