
AI has long been a part of capital markets. In 2022, machine learning in banking, financial services, and insurance represented 18% of the overall AI market. McKinsey research shows that AI adoption has risen steadily, from 50% in 2022 to 72% in 2024, with financial services leading the charge. Many firms are already leveraging AI for predictive modeling, credit risk assessment, and portfolio management.
More recently, Generative AI (GenAI) has seen a surge, with adoption jumping from 22% in 2023 to 65% in 2024. Despite this growth, skepticism persists—especially in financial services, where only 8% of respondents reported using GenAI regularly for work in 2024, unchanged from the previous year.
So, what’s fueling this hesitation?
McKinsey points to key risks: inaccuracy (63%), regulatory compliance (45%), and lack of explainability (40%). An EY report highlights strategic gaps as well—95% of senior executives say their organizations are investing in AI, yet only 36% are fully investing in the necessary data infrastructure, and just 34% are aligning AI strategy with business objectives at scale.
Additionally, a Gartner survey identified ROI as a major hurdle, with 49% of leaders citing difficulties in measuring and demonstrating AI’s value.
This suggests the reluctance to embrace GenAI stems from concerns about risks and a lack of investment in robust, accessible, and governed data. In short: they don’t have AI-ready data.
In this blog, I explore how data leaders in the financial sector can enhance their data infrastructure, culture, and strategy to maximize AI’s ROI.
1. Embrace new data types (e.g. Unstructured, structured, and streaming data)
One of the most significant habits of high-performing AI trading firms is that they process new types of data quicker than laggards. Thanks to the rise of GenAI, new opportunities are at hand to process unstructured data such as market sentiment, news, client interactions, and corporate filings — these are now first-class citizens in the trading data universe.
Making unstructured data available for quantitative trading research helps accelerate trading strategy ideation, simulation of execution scenarios, and risk assessment by using GenAI to incorporate unstructured data with traditional structured data.
Of course, trading data is streaming data, and every capital markets firm must embrace streaming data from market feeds, live client interactions, real-time executions and orders, news, and social media sentiment. This data is best processed live as it changes so that models can react to new data inputs.
Learn how unstructured data creates a new opportunity to gain an analytics edge in my blog: Structured meets unstructured data to win on the GenAI playing field.
2. Shift left: Move data governance upstream
At a recent chief data and analytics officer network session, I asked a roomful of data and analytics leaders from capital markets firms a simple question: “With all the interest and hype around AI, how many of you get risk management teams involved earlier in AI projects?”
80% of the hands in the room shot up.
Getting risk teams involved earlier helps make outcomes more effective.
Research shows they’re right. McKinsey & Company’s study found that high AI performers bring risk management and client services minds into the fold earlier than laggards. They help raise and solve questions about regulations, trading risk, reputational risk, and client concerns as early as possible so that trading teams consider them part of their work.
Like the ‘Pre-Crime’ division from the movie Minority Report, involving these teams earlier helps foresee and stop crimes before they happen.
‘Shifting left’ applies to data pipelines, too. Quant trading leaders process data as it streams into trading operations to generate vector embeddings, build synthetic market trends, and correct errors and smooth outliers before they infect trading algorithms and tick stores.

3. Curate and automate a semantic data layer
Every trading firm has a unique language—syntax and semantics—representing its products, processes, people, assets, customers, partners, and policies. When using GenAI on a trading desk, it’s essential to integrate those semantics into AI prompt engineering.
New research from DataWorld shows that semantic layers can make GenAI answers three times more accurate than direct SQL database queries (16% to 54%). AI high-performers curate, create, and automate this semantic data layer as part of the data pipeline and culture. A semantic layer is the living manifestation of your trading strategies, internal codes, rules, and risk profile, ensuring each data morsel adheres to your trading policies, methods, and risk mandates.
Want a simple test of which kind of semantic layer you have in your organization? Ask your data team for a simple, conceptual diagram that describes the physical structure of your enterprise data in business terms. When you get a picture of your data, see which image it resembles most below. The curated semantic layer at right describes the data an insurance company uses to describe how customers, policies, premiums, and expense reserves relate. You have some work to do if your semantic layer doesn’t look like the one below:
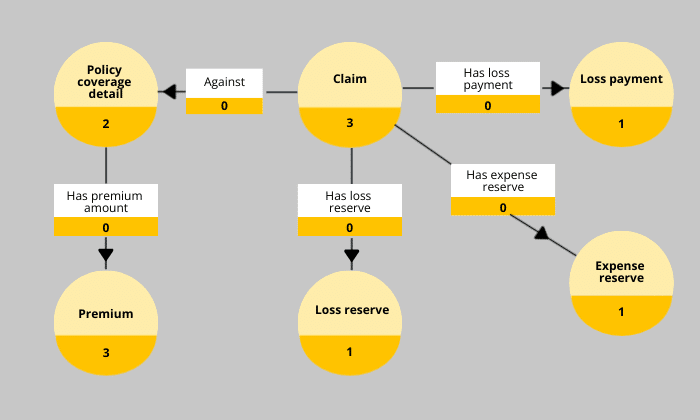
AI high performers establish data semantics librarians, extract semantic meaning in their data pipelines, and maintain a single version of the truth for those data semantics. By automating the semantic extraction process and putting the human in the loop, leaders systematically preserve the language of business through data.
4. Stream vector embeddings in your data pipeline
With the rise of GenAI and its reliance on unstructured data, creating vector embeddings that power similarity search has become essential. AI uses these embeddings to predict the correct response to natural language questions. Trading innovators apply vector databases to create GenAI trading co-pilots to allow traders to explore new trading ideas, review trade signals independently, and better understand the fundamental factors that affect a strategy’s risk. To do this, AI leaders incorporate the creation of vector embeddings in their data pipelines.
Creating vector embeddings on market data introduces two challenges most mainstream GenAI applications do not face. First, embeddings must be made using streaming data, which, for some applications, can change tens of thousands of times a second. Many open-source models are designed for batch operations and are inappropriate for trading. Pipelines must be modified to parse and chunk data into manageable, effectively embedded pieces. This is crucial for fitting data into the model’s context window and ensuring accurate embeddings.
Second, standard AI embedding models like BERT or Word2Vec suit NLP (Natural Language Processing) tasks. However, the newest innovations in the GenAI space help encode structured time series data to help traders find similar time-series patterns in market data.
Finally, trading leaders monitor their data pipelines more aggressively than laggards. Just 7% of the general population monitors their AI pipelines, while 41% of leaders track data quality, measure AI model performance, and monitor AI infrastructure health and the cost of AI operations. This includes fine-tuning hyperparameters, updating models with new data, and ensuring that embeddings remain relevant and accurate over time.
By carefully planning the integration of AI into your pipeline, you can enhance your firm’s ability to introduce new data quickly, safely, and securely to drive better business outcomes.
5. Expand your learning and development programs for AI dojo
Once you have a solid data pipeline, train quant trading analysts to use it effectively. Research shows that AI high performers promote a curated learning journey more than twice as much as laggards, 43% to 18%. The style of training matters, too. Research shows that project-based learning is 2-3X more effective than conventional, classroom-style learning. This is because you must use AI to learn AI.
‘The effectiveness of the project-based learning (PBL) approach as a way to engage students in learning’ identified core elements of learning that can be applied to optimize the impact of your upskilling initiatives. They found that effective programs are:
- Collaborative: Where teachers negotiate knowledge in dialogue and focus learning on specific use cases
- Iterative: Involving repetitive questioning, meaning-making, reflection, and sharing
- Interactive: Encouraging students to actively generate new ideas, share them, develop each other’s thinking, and assess their own and their peers’ academic thoughts
Leaders prioritize L&D more than laggards; their programs are collaborative, project-based, iterative, and interactive. However, one training program only fits some, so leaders carefully design learning journeys based on specific needs.
To be an AI high performer, design L&D programs with care, emphasizing an interactive, immersive style, and extend literacy opportunities to everyone.
Conclusion
Data pipelines and culture form the bedrock of data-informed trading innovation. However, the AI era presents new challenges in maintaining that foundation. By embracing GenAI, incorporating new types of unstructured and streaming data into data pipelines, optimizing AI for streaming data, shifting left to consider risk earlier, utilizing vector embeddings, creating a semantic data layer, and reimagining your L&D programs, you’ll ensure your trading teams are ready to capitalize on the emerging GenAI opportunity.
For more information on what it takes to build a successful AI program, read our AI factory 101 series. Discover why KDB.AI is a crucial part of the AI factory here. Learn more about how KX is powering the future of real-time analytics in financial services here.