
Large Language Models (LLMs) have transformed natural language understanding, powering applications like chatbots, question answering, and summarization. However, their static datasets can limit relevance and accuracy. Retrieval-Augmented Generation (RAG) addresses this by enriching LLMs with up-to-date external data, enhancing response quality and contextual relevance. RAG is a powerful workflow, but building RAG-enabled applications is complex, requiring multiple steps and a scalable infrastructure.
To simplify this process, we’re excited to introduce the integration of KDB.AI with LlamaIndex, an open-source framework that streamlines the ingestion, storage, and retrieval of datasets for RAG applications. This integration enables developers to create sophisticated RAG-enabled applications with ease and efficiency.
In this blog post, we will explain how LlamaIndex and KDB.AI work together to enable RAG solutions and showcase some potential enterprise use cases that can benefit from this integration.
How Does LlamaIndex Enable RAG Solutions?
LlamaIndex is a data framework for building LLM-based applications, it specializes in augmenting LLMs with private or domain-specific data. LlamaIndex offers several types of tools and integrations to help users quickly develop and optimize RAG pipelines:
- Data Loaders: Ingest your data from its native format. There are many connectors available including for .csv, .docx, HTML, .txt, PDF, PPTX, Pandas DataFrames, and more.
- Parsing: Chunking data into smaller and more context specific nodes can greatly improve the results of your RAG application.
- Embeddings: Transforming your data into vector embeddings is a key step in the RAG process. LlamaIndex integrates with many embedding models including OpenAI embedding models, Hugging Face Embeddings, LangChain Embeddings, Gemini Embeddings, Clip Embeddings, and many more.
- Vector Stores / Index: Store embeddings within vector databases like KDB.AI to perform fast and accurate retrieval of relevant data to augment the LLM.
- Hyperparameter Tuning: Optimize both chunk size and the number of top-k retrieved chunks to ensure your RAG pipeline generates the best possible results.
- Retrievers: LlamaIndex offers a variety of retrievers to get the most relevant data from the index. Some examples are, Auto-Retrieval, Knowledge Graph retriever, hybrid retriever (BM25), Reciprocal Rerank Fusion retriever, Recursive Retriever, Ensemble Retriever, etc.
- Postprocessors: LlamaIndex has many options for postprocessing retrieved data ranging from keyword matching, reranking, recency filtering, time-weighted reranking, sentence windows, long context reordering (fixes lost in the middle problem), prompt compression, retrieve surrounding nodes and others.
- Data Agents: Agents are LLM-powered knowledge workers that use tools and functions to complete specific tasks. LlamaIndex supports and integrates with several agent frameworks such as “OpenAIAgent”.
- Evaluation: Evaluate both the retrieval and generation phases of RAG with modules to test retrieval precision, augmentation precision, answer consistency, answer accuracy and more.
- Llama Packs: Llama Packs are prepackaged modules to help users quickly compose an LLM application. Llama Packs can be initialized and run out-of-the-box or used as templates to modify to your use-case. You can see available Llama Packs on the Llama Hub. Examples include RAG pipelines, resume screener, and moderation packages.
KDB.AI Integration with LlamaIndex
KDB.AI is a high-performance vector database optimized for machine learning, natural language processing, and semantic search at scale. It stores and queries vector embeddings, with the ability to attach embeddings to a variety of indexes to facilitate rapid vector search and retrieval.
LlamaIndex can be used orchestrate ingestion, preprocessing, metadata tagging, and embedding for incoming data or the user’s query. Its integration with KDB.AI enables a variety of retrieval methods to find contextually relevant information from the KDB.AI vector store. The retrieved information can then be postprocessed and used to augment the LLM’s generated output, resulting in a more precise and contextually relevant response to the user’s question.
The following diagram illustrates the workflow of LlamaIndex and KDB.AI for RAG solutions:
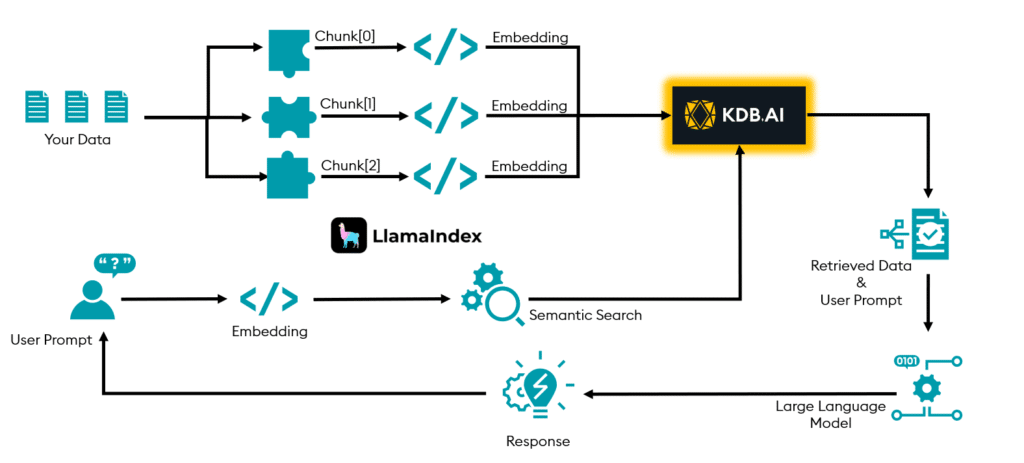
LlamaIndex has functionality to help orchestrate each phase in the above diagram while still giving the user the flexibility to implement the RAG workflow in the best interest of the use-case.
Potential Use Cases
By combining LlamaIndex and KDB.AI, developers can leverage the power of RAG solutions for a variety of applications, such as:
- Document Q&A: You can use LlamaIndex to ingest and index your unstructured data sources, such as manuals, reports, contracts, etc., and convert to vector embeddings. Then, you can use KDB.AI to store and query the vector embeddings at scale, using natural language queries. This way, you can provide fast and accurate answers to your users’ questions, without requiring them to read through lengthy documents.
- Data Augmented Chatbots: You can use LlamaIndex to connect and structure your semi-structured data sources, such as APIs, databases, etc. Then, you can use KDB.AI to search and rank the relevant data items based on the user’s input and the chatbot’s context. This way, you can enhance your chatbot’s capabilities and provide more personalized and engaging conversations to your users.
- Knowledge Agents: You can use LlamaIndex to index your knowledge base and tasks, such as FAQs, workflows, procedures, etc. Then, you can use KDB.AI to store and query the vector embeddings, using natural language commands. This way, you can create automated decision machines that can perform tasks based on the user’s input, such as booking appointments, ordering products, resolving issues, etc.
- Structured Analytics: You can use LlamaIndex to ingest and index your structured data sources, such as spreadsheets, tables, charts, etc. Then, you can use KDB.AI to search and rank the relevant data rows or columns based on the user’s natural language query. This way, you can provide easy and intuitive access to your data analytics, without requiring the user to learn complex syntax or tools.
- Content Generation: You can use LlamaIndex to ingest and index your existing content sources, such as blogs, articles, books, etc. Then, you can use KDB.AI to search and rank the most similar or relevant content items based on the user’s input or topic. This way, you can generate new and original content, such as summaries, headlines, captions, etc., using the LLM’s generation capabilities.
In this blog we have discussed how LlamaIndex and KDB.AI work together to empower developers to build RAG-enabled applications quickly and at scale. By integrating LlamaIndex and KDB.AI, developers can augment LLMs with contextually accurate information, and in turn, provide more precise and contextually relevant response to end user questions.
To find out more check out our documentation today!