
In 2023, KX launched KDB.AI, a groundbreaking vector database and search engine to empower developers to build the next generation of AI applications for high-speed, time-based, multi-modal workloads. Used in industries such as Financial Services, Telecommunications, Manufacturing and more, KDB.AI is today recognized as the world’s leading vector database solution for enterprise customers.
In our latest update, we’re introducing several new features that will significantly improve vector performance, search reliability, and semantic relevance.
Let’s explore.
Hybrid Search
The first is Hybrid Search, an advanced tool that merges the accuracy of keyword-focused sparse vector search with the contextual comprehension provided by semantic dense vector search.
Sparse vectors predominantly contain zero values. They are created by passing a document through a tokenizer and associating each word with a numerical token. The tokens, along with a tally of their occurrences, are then used to construct a sparse vector for that document. This is incredibly useful for information retrieval and Natural Language Processing Scenarios where specific keyword matching must be highly precise.
Dense vectors in contrast predominantly contain non-zero values and are used to encapsulate the semantic significance, relationships and attributes present within the document. They are often used with deep learning models where the semantic meaning of words is important.
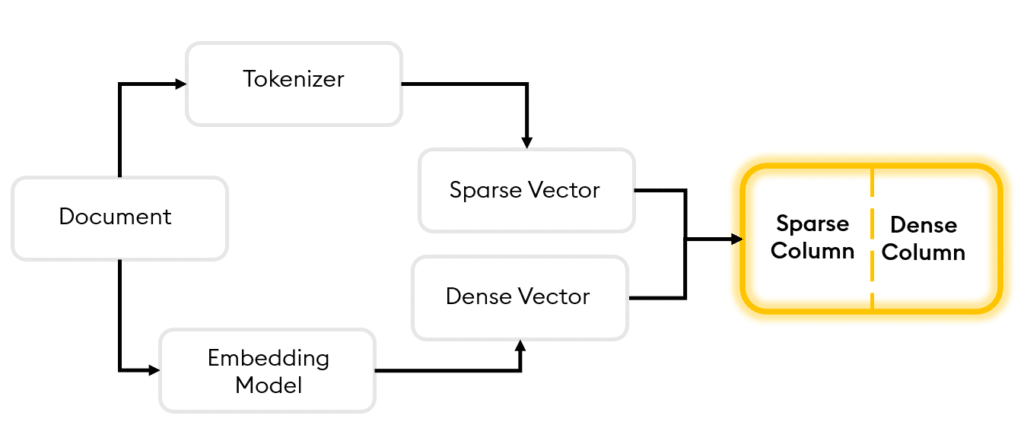
With KDB.AI 1.1, analysts can tweak the relative importance of sparse and dense search results via an alpha parameter, ensuring highly pertinent data retrieval and efficient discovery of unparalleled insight.
Example Use Case
Consider a financial analyst looking for specific information on a company’s performance in order to assess investment risk. The analyst might search for “Company X’s Q3 earnings report” in which a sparse vector search would excel.
However, the analyst might also be interested in the broader context, such as market trends, competitor performance, and economic indicators that could impact Company X’s performance. Dense vector search could be used to find documents that may not contain the exact keywords but are semantically related to the query.
For example, it might find articles discussing a new product launched by a competitor or changes in trade policies affecting Company X’s industry.
With Hybrid Search the analyst is afforded the best of both worlds, and ultimately retrieves a comprehensive set of information to assist with the development of their investment strategy.
Temporal Similarity Search
The second key feature is the introduction of Temporal Similarity Search (TSS), a comprehensive suite of tools for analyzing patterns, trends, and anomalies within time series datasets.
Comprising of two key components, Transformed TSS for highly efficient vector searches across massive time series datasets and Non-Transformed TSS, a solution for near real-time similarity search of fast-moving data, TSS enables developers to extract insights faster than ever before.
Transformed Temporal Similarity Search
Transformed Temporal Similarity Search is our patent-pending compression model designed to dimensionally reduce time-series windows by more than 99%. With Transformed TSS, KDB.AI can compress data points into significantly smaller dimensions whilst maintaining the integrity of the original data’s shape.
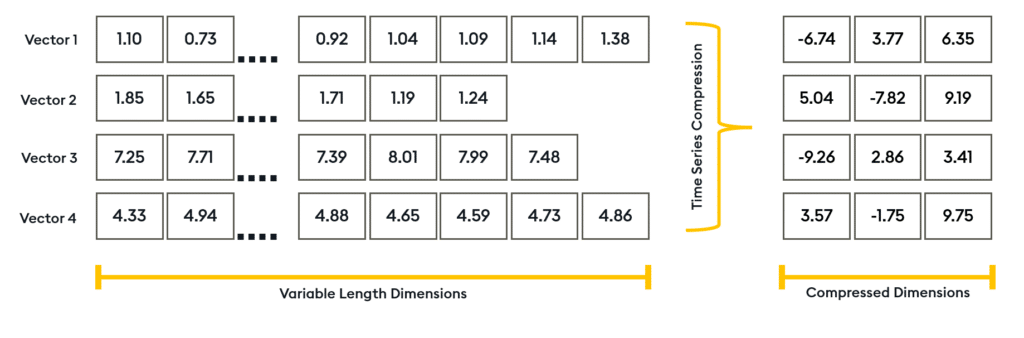
It also enables the compression of varying sized windows into a uniform dimensionality, in valuable when working with time series data of different sample rates and window sizes.
By doing so, Transformed TSS significantly reduces memory usage and disk space requirements to minimize computational burden. And with the ability to attach compressed embeddings to prebuilt Approximate Nearest Neighbor (ANN) indexes, developers can expect significant optimization of retrieval operations in large scale embeddings.
Example Use Case
Consider a multinational retail corporation that has been experiencing stagnant growth and is now looking for ways to improve their business strategies.
With Transformed TSS, they can perform detailed analysis of their time series user interaction data, including clicks, views, and engagement times. This allows them to uncover hidden patterns and trends, revealing optimal times and contexts for ad placement.
Applying a similar concept to their retail operations, they can segment purchase history data into time windows, resulting in advanced similarity searches that unveil subtle purchase patterns, seasonal variations, and evolving consumer preferences.
Armed with these insights, the corporation can fine-tune their marketing strategies, optimize stock levels, and predict future buying trends.
Non-Transformed Temporal Similarity Search
Non-Transformed Temporal Similarity Search is a revolutionary algorithm designed for conducting near real-time similarity search with extreme memory efficiency across fast moving time-series data. It provides a precise and efficient method to analyze patterns and trends with no need to embed, extract, or store vectors in the database.
Non-Transformed TSS enables direct similarity search on columnar time-series data without the need to define an Approximate Nearest Neighbor (ANN) search index. Tested on one million vectors, it was able to achieve a memory footprint reduction of 99% percent, and a 17x performance boost over 1K queries.
| Non-Transformed TSS | Hierarchical Navigable Small Worlds Index | |
| Memory Footprint | 18.8MB | 2.4GB |
| Time to Build Index | 0s | 138s |
| Time for Single Similarity Search | 23ms | 1ms (on prebuilt index) |
| Total Time for Single Search (5 neighbors) | 23ms | 138s+1ms |
| Total Time for 1000 searches (5 neighbors) | 8s | 139s |
Example Use Case
Consider a financial organization looking to enhance its fraud detection capabilities and better respond to the increased cadenced and sophistication of attacks. With millions of customers and billions of transaction records, the organization requires a computationally efficient solution that will scale on demand.
With Non-Transformed Temporal Similarity Search the organization can analyze transactions in near real-time, without the need to embed, extract or store incoming records into a database prior to analysis. Inbound transactions are compared against historical patterns in the same account, and those exhibiting a high degree of dissimilarity can be flagged for further investigation.
We hope that you are as excited as we are about the possibilities these enhancements bring to your AI toolkit. You can learn more by checking out our feature articles over on the KDB.AI Learning Hub then try them yourself by signing up for free at KDB.AI