As data volumes increase, many applications must resort to offloading data from memory to long term storage media (SSD/NVMe/HDD/NFS), but subsequently suffer a performance hit when analyzing it from those inherently slower media. The introduction of Intel® Optane™ persistent memory (Intel Optane PMem) from Intel provides a solution by introducing a new category that sits between memory and storage. Using the same DDR4 DIMM slots (and memory bus) as DRAM, Intel Optane PMem sits close to the CPU, and allows applications to directly address it as memory.
With the introduction of Intel Optane PMem and its price and capacity advantages over conventional DRAM, including, for example, being able to configure 3TB of memory on 2-socket servers, we decided to investigate the feasibility of keeping more data in memory and quantify how much this new hardware choice would improve analytics performance.
The results of that investigation, carried out in conjunction with a top-tier bank, are outlined below. Please note that all references to “memory” henceforth refer to DRAM mixed with Intel Optane PMem. This is sometimes referred to as “Memory Mode” for Intel Optane PMem, whereby DRAM is used as a cache for Intel Optane PMem. Note also that kdb+ 4.0 additionally supports App Direct Mode, which gives finer-grained control over the use of Intel Optane PMem.
The investigation set out to examine two use cases, to compare behavior of Intel Optane PMem running in “Memory Mode” vs a single NAND-flash NVMe drive:
Use Case 1
Test: execution time for kdb+/q queries running against NVMe vs loading data into memory, which is backed by Intel Optane technology.
Desired outcome: query execution time speed up of at least 60%.
Use Case 2
Test: enable new analytics by allowing in memory access to larger data volumes.
Desired outcome: data heavy and long running queries against NVMe (over 2 minutes), complete within 40 seconds with data in memory.
Preparation
For the purpose of the tests, eleven analytics were identified from a live production system as the most common and best representative of “real-life” use cases:
| Ref | Query |
| 1 | select * by date,col1 from quote where date=2020.01.07, col3 in `val1 |
| 2 | select * by date,col1 from quote where date within (2020.01.03 2020.01.31), col3 in `val1 |
| 3 | select * by date,col1 from quote where date within (2019.11.01 2020.01.31), col3 in `val1 |
| 4 | select * from quote where date=2020.01.07, col3 in `val2`val1`val3 |
| 5 | select * by date,col1,col2 from quote where date=2020.01.07, col3 in `val2`val1`val3 |
| 6 | select * by date,col1,col2 from quote where date within (2020.01.03;2020.01.31), col3 in `val2`val1`val3 |
| 7 | select * by date,col1,col2 from quote where date within (2019.11.01;2020.01.31), col3 in `val2`val1`val3 |
| 8 | select * by col1 from quote where col3 in `val2`val1 |
| 9 | select * by date,col1 from quote where date within (2019.11.01;2020.01.31),col3 in `val2`val1 |
| 10 | select * from quote where date within (2020.01.03 2020.01.31), col3 in `val2`val1`val3 |
| 11 | select * from quote where date within (2019.11.01 2020.01.31), col3 in `val2`val1`val3 |
Table 1: Queries used in the test case
The dataset to run the tests on was taken from a HDB, partitioned by date, spanning across 2019 and 2020. The data was then read into a kdb+ live session, running 4 slave threads, as an in-memory object, flattening all partitions into a single monolithic table in memory, resulting in a total memory usage of 130GB. Below is a meta of the table that was used in our test cases:
c | t f a
---------| -----
date | d
col1 | s
col2 | s
col3 | s
The following shows for each query how many rows were input and resulting output:
queryRef inputRowCnt outputRowCnt
---------------------------------
1 191113021 2
2 191113021 4
3 191113021 4
4 191113021 3064072
5 191113021 4
6 191113021 8
7 191113021 8
8 191113021 3
9 191113021 6
10 191113021 71643220
11 191113021 189941620
Results in kdb+ 3.6
We analysed results with and without the p attribute applied.
Without p attribute
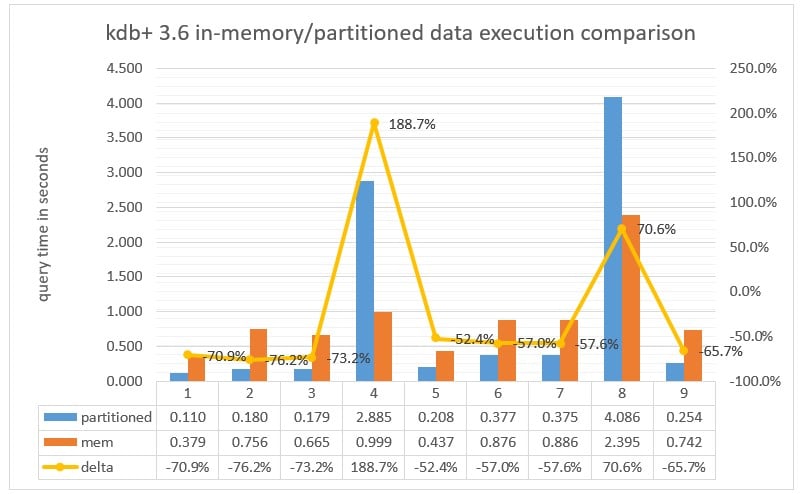
Chart 1: Query execution time measured in milliseconds executed against a partitioned database versus in memory with no parted attribute in kdb+ 3.6.
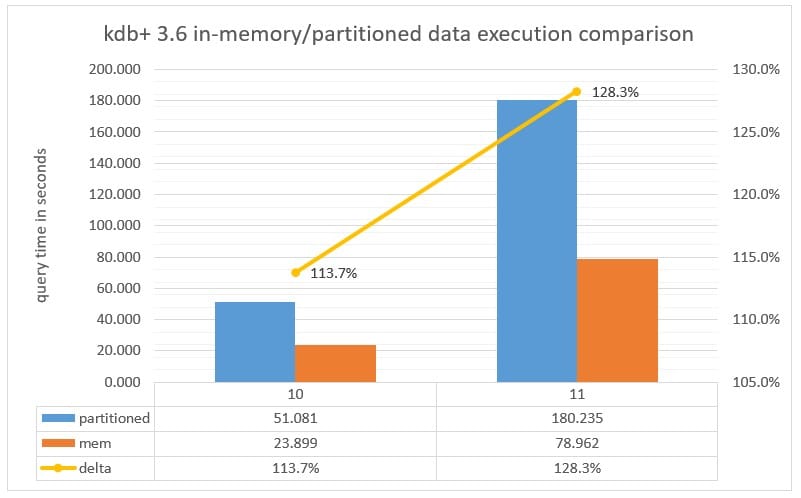
Chart 2: Query execution time measured in seconds executed against a Partitioned database versus the data in-memory with parted attribute applied to the date column running kdb+ 3.6.
With p attribute
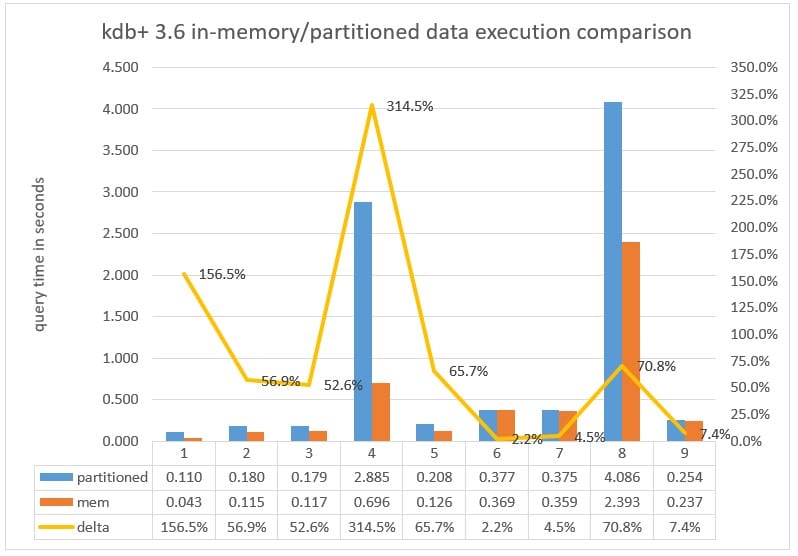
Chart 3: Query execution time measured in milliseconds executed against a Partitioned database versus the data in-memory with parted attribute applied to the date column running kdb+ 3.6.
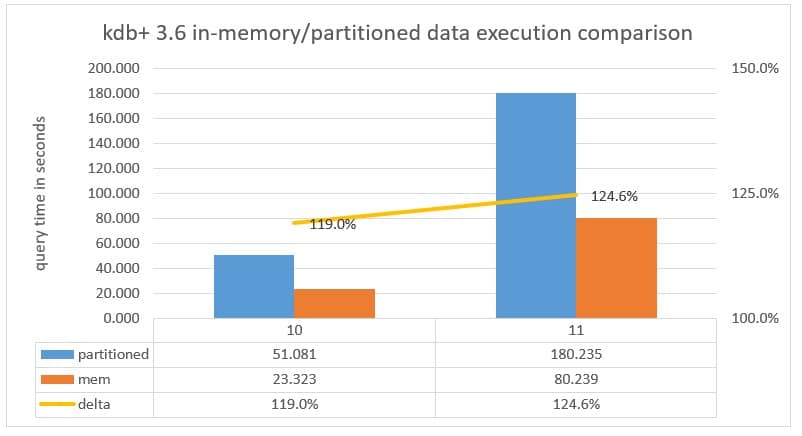
Chart 4: Query execution time measured in seconds executed against a Partitioned database versus the data in-memory with parted attribute applied to the date column running kdb+ 3.6.
Results in kdb+ 4.0
We then ran the tests on kdb+ version 4.0 to avail of the implicit multithreaded feature when using kdb+ primitives like the following:
atomics: abs acos and asin atan ceiling cos div exp floor
log mod neg not null or reciprocal signum sin sqrt
tan within xbar xexp xlog + - * % & | < > = >= <= <>
aggregate: all any avg cor cov dev max min scov sdev sum svar var wavg
lookups: ?(find) aj asof bin binr ij in lj uj
index: @(at) select delete
misc: $(cast) #(take) _(drop) ,(join) deltas differ next prev
sublist til where xprev
Without p attribute
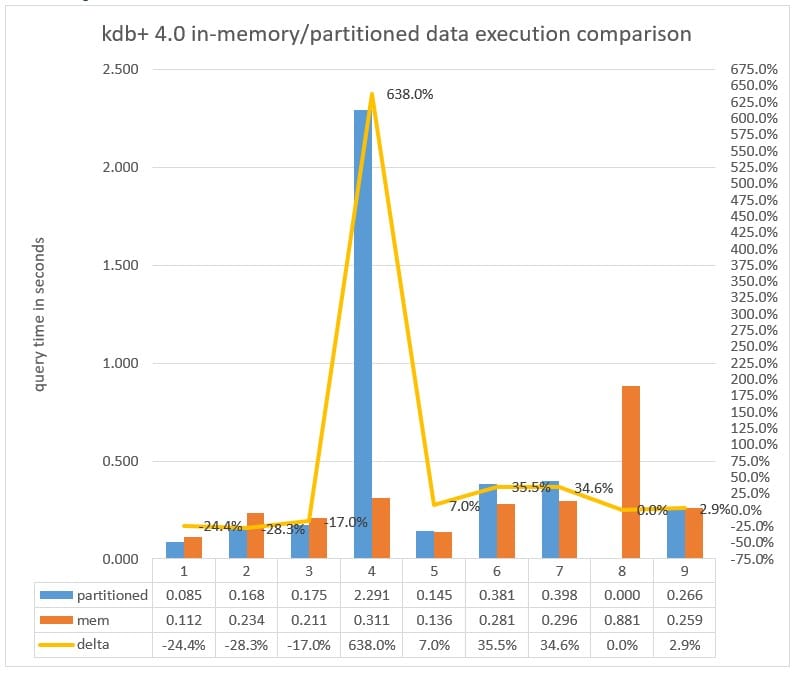
Chart 5: Query execution time measured in milliseconds executed against a partitioned database versus in memory with no parted attribute in kdb+ 4.0
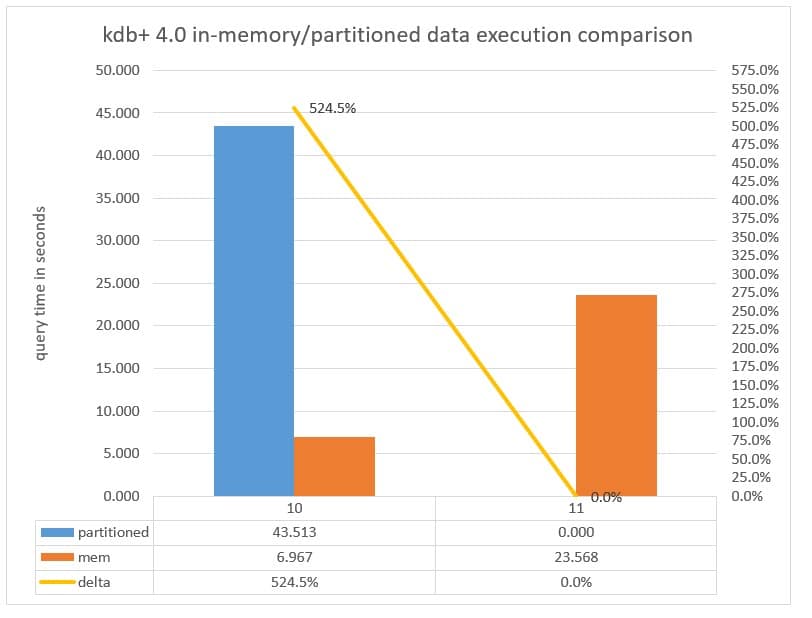
Chart 6: Query execution time measured in seconds executed against a Partitioned database versus the data in-memory with parted attribute applied to the date column running kdb+ 4.0. Note query 11 hit -w limit allocation.
With p attribute
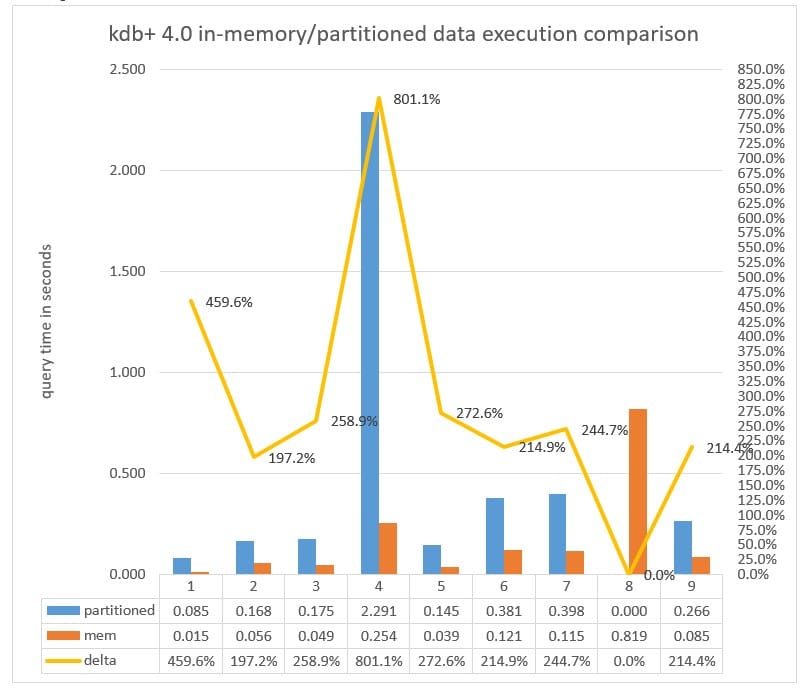
Chart 7: Query execution time measured in milliseconds executed against a Partitioned database versus the data in-memory with parted attribute applied to the date column running kdb+ 4.0
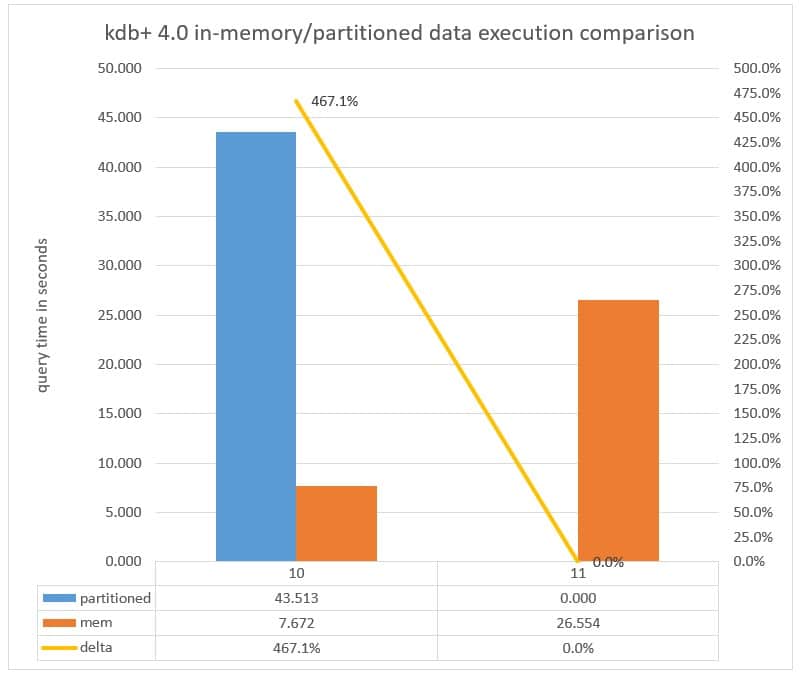
Chart 8: Query execution time measured in seconds executed against a Partitioned database versus the data in-memory with parted attribute applied to the date column running kdb+ 4.0 Note query 11 hit -w limit allocation.
Further analysis was carried out on over 3 years of data which on NVMe spanned across 784 partitions and when brought into memory totalled 1.9TB in kdb+ 4.0 and where, capitalizing on the implicit within-primitive parallelism over 4 slaves threads, we were able to make the query execution time up to 3x faster in memory compared to on NVMe, thereby meeting both the requirements of test case 1 and 2.
The following shows for each query how many rows were input and resulting output:
queryRef inputRowCnt outputRowCnt
---------------------------------
1 2163100445 2
2 2163100445 4
3 2163100445 4
4 2163100445 3064072
5 2163100445 4
6 2163100445 8
7 2163100445 8
8 2163100445 0N // -w abort at 5.5TB
9 2163100445 6
10 2163100445 71643220
11 2163100445 0N // -w abort at 5.5TB
With p attribute
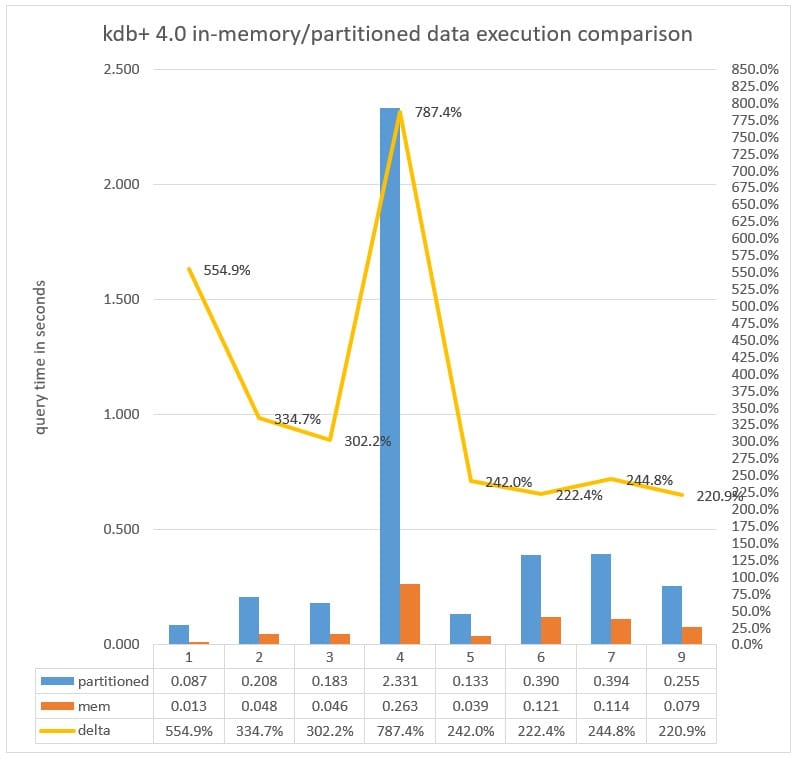
Chart 9: Query execution time measured in milliseconds executed against a Partitioned vs in-memory with parted attribute applied to the date column running kdb+ 4.0
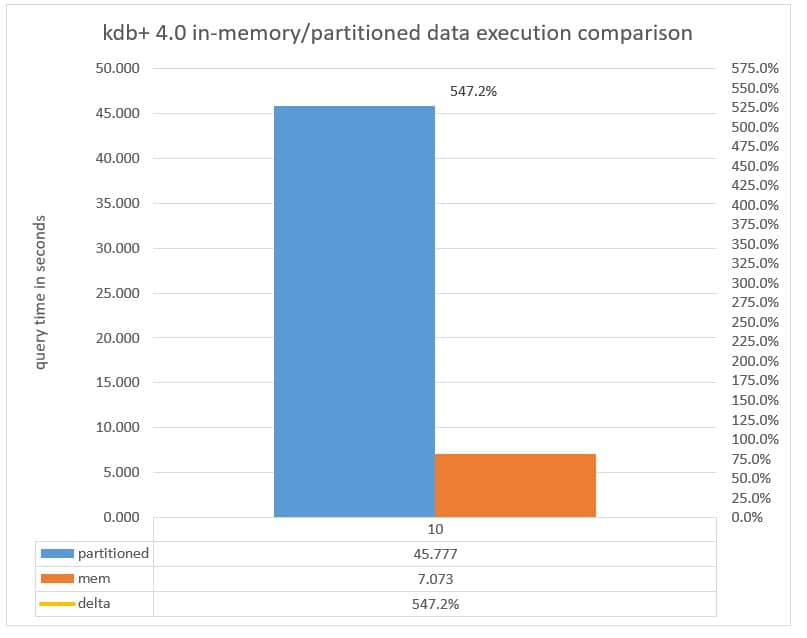
Chart 10: Query execution time measured in seconds executed against a Partitioned vs in-memory with parted attribute applied to the date column running kdb+ 4.0
In chart 6, query 10 is being executed against 784 partitions, and we can see that the execution time of just over 50 seconds when the query is directed against data on NVMe (the partitioned database) decreases to just over 7 seconds when the query is directed to memory. This is twice as fast as the same query executed in kdb+ 3.6 which took over 14 seconds on much less data, showing how multithreaded primitives make kdb+ 4.0 faster.
Conclusion
From this analysis we have shown that a common use-case run on Intel Optane PMem backed memory can perform up to almost 10 times faster than when run against high-performance NVMe. The speed gains observed from moving the data from NVMe into memory highlights the possibility for new analytics to be run significantly faster on systems configured with Intel Optane PMem .
For more information on KX’s support for Intel Optane PMem, including the App Direct Mode, please click on this link