High-Frequency Data Benchmark Results
These results are based on independent high-frequency data benchmarks designed to reflect real analytical workloads, including trade data, order book analytics, and complex time-series queries.
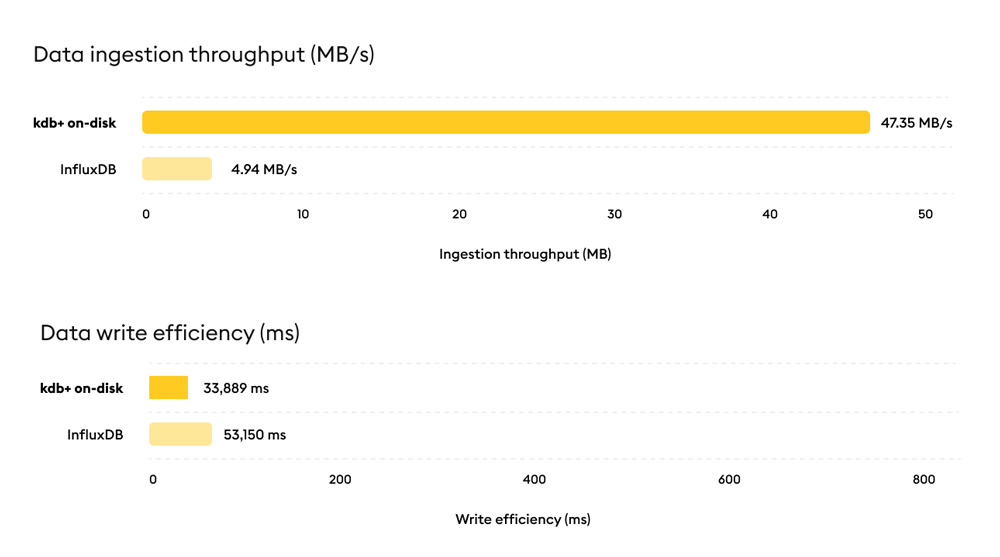
Ingestion and Storage
Disk based benchmarks measured sustained ingestion throughput and write efficiency under realistic production persistence.
Result: kdb+ delivers materially higher ingestion throughput and faster write completion than InfluxDB under equivalent on disk conditions.
Why it matters? Higher sustained ingestion supports symbol dense, high velocity market data without backlog risk.

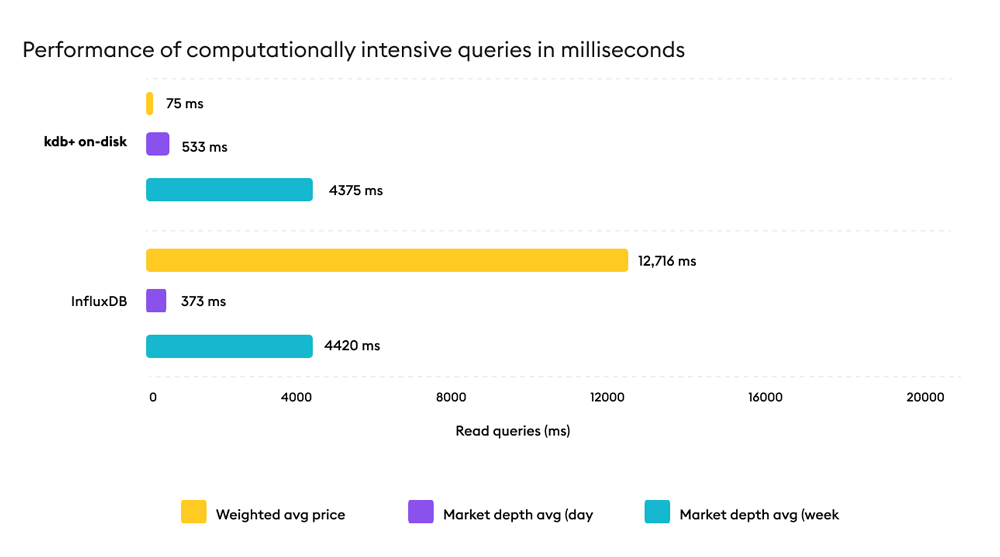
Computationally Intensive Queries
Workloads including weighted average price and market depth stressed CPU and memory efficiency under combined read and compute pressure.
Result: kdb+ maintains significantly lower execution times than InfluxDB as computational complexity increases.
Why it matters? Analytical performance remains stable as models become more sophisticated.
Read Query Performance
Read heavy workloads including trading volume and order book analytics were evaluated under analytical access patterns.
Result: kdb+ demonstrates consistently lower query latency than InfluxDB across read heavy analytical workloads.
Why it matters? Lower latency enables interactive research and faster signal generation.
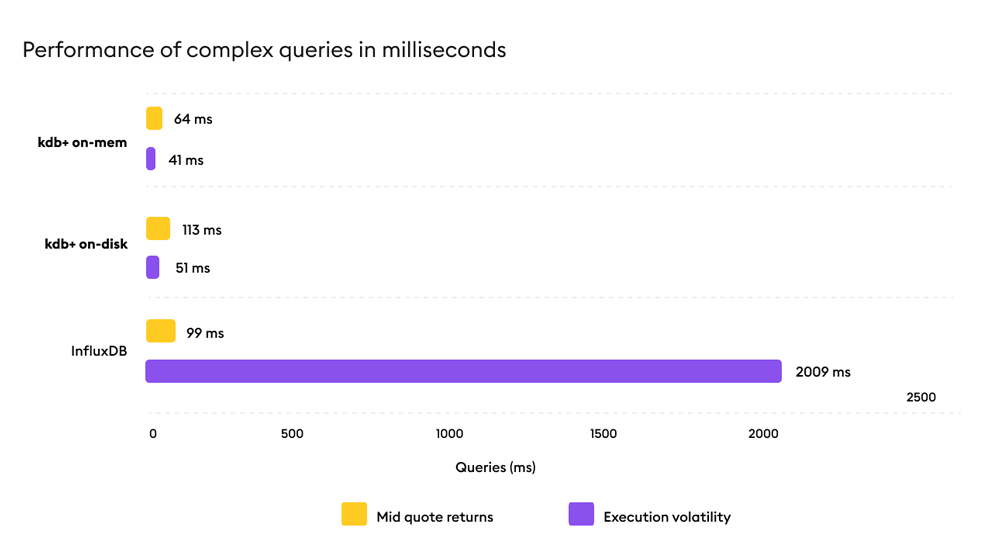
Complex Analytical Queries
Mid quote returns and execution volatility queries combine multiple analytical operations representative of real trading and risk workflows.
Result: kdb+ consistently completes complex analytical queries with lower latency, while InfluxDB exhibits materially higher execution times under identical conditions.
Why it matters? Completion reliability and latency predictability are critical in trading and surveillance environments.
Benchmarks independently conducted by Imperial College London using equivalent datasets, schemas, and test conditions.
Platform Capabilities Comparison
This section compares kdb+ and InfluxDB across core platform capabilities relevant to analytical time series workloads. It focuses on how each platform supports scalability, performance, and operational requirements as analytical use cases grow from development into production.
kdb+ is independently verified as the fastest time-series analytics platform, processing billions of events at microsecond latencies with minimal infrastructure. kdb+ features advanced statistical functions, machine learning integration, and multi-language support that is ideal for sophisticated use cases like risk modeling and predictive analytics. |
A time -series database designed for IoT monitoring and time-stamped data handling. While suitable for straightforward logging and visualization, it experiences performance bottlenecks under heavy analytical workloads and lacks the advanced computational capabilities required for complex enterprise analytics. |
|
| Performance at scale | Unmatched speed with kdb+ engine | Performance bottlenecks under heavy loads |
| Analytics depth | Advanced ML, statistical analysis, event processing | Limited querying and analytics capabilities |
| Enterprise readiness | Built for mission-critical operations | Primarily targets smaller workloads |
| Language support | Python integration, q programming language | Flux query language, limited flexibility |
| System reliability | Comprehensive backup retention, enterprise-grade | Limited high availability in non-enterprise tiers |
| Complex query handling | Optimized for high-cardinality datasets | Struggles with complex queries on large datasets |
Architectural Differences
Performance stability, concurrency behavior, and analytical depth are determined by structural design.
Concurrency Behavior
kdb+ maintains consistent, low latency under high analytical concurrency. InfluxDB performance varies as query complexity and series cardinality increase.
High Cardinality
kdb+ is optimized for symbol-heavy, dimension-rich time series data. InfluxDB is primarily designed for metrics and observability workloads.
Analytical Depth
kdb+ executes advanced time-series analytics directly in the engine. InfluxDB focuses on monitoring, dashboards, and derived metrics.

Predictability
kdb+ sustains stable query completion times under complex workloads. InfluxDB often requires over-provisioning or added scaling layers to maintain performance.
Built for Capital Markets Analytics
kdb+ enables high-performance time-series applications where latency, scale, and analytical depth directly impact trading and risk outcomes.
Real-Time Market Data Analytics
kdb executes advanced calculations including spreads, VWAP, volatility, and signal generation directly within the engine, maintaining low latency as query complexity increases while InfluxDB performance characteristics vary as workloads move beyond aggregation and monitoring patterns.
Intraday Risk and Surveillance
kdb processes symbol rich datasets under high concurrency, supporting exposure calculation, liquidity analysis, and anomaly detection with predictable execution while InfluxDB is primarily designed for telemetry workflows rather than high concurrency analytical processing.


Multi Year Backtesting and Strategy Research
kdb sustains consistent performance across year scale historical simulations, enabling iterative model development without exporting data to external compute layers while InfluxDB is optimized for shorter horizon, metrics oriented workloads where extended analytical depth can introduce variability.
Concurrent Research and Production Workloads
kdb supports simultaneous access from quants, trading systems, and downstream services within a unified execution model while InfluxDB deployments often require additional architectural layers as analytical complexity increases.
Featured Capital Markets Case Study
kdb+ was selected after evaluating multiple platforms, including InfluxDB, for its vectorized analytics, scalability, and predictable performance under analytical load.
A Large Enterprise Capital Markets Company slashes total cost of ownership while unlocking substantial performance gains
After evaluating multiple platforms, including InfluxDB, the organization selected kdb+ for its vectorized analytics, scalability, and predictable performance under analytical load.
The firm now processes 100–500 GB of structured market data daily while maintaining efficient access to 100–500 TB of historical data. Complex predictive models and time-series analytics that previously introduced latency constraints now execute reliably within production SLAs.
This transformation established a scalable analytical foundation across research, trading, and risk workflows.
100%
Increased query performance
75%
Reduction in total cost of ownership
11.0 months
Average time to return on investment (ROI)
Powered by ![]()
**Survey conducted and verified by UserEvidence
*** Source: To see how kdb performed in independent benchmarks that show similar on replicable data see: TSBS 2023, STAC-M3, DBops and Imperial College London Results for High-performance DB benchmarks.
Why teams selected kdb+ over InfluxDB
Independent survey research conducted by UserEvidence highlights the primary factors influencing teams who evaluated or migrated from InfluxDB to kdb+. These responses reflect architectural, performance, and operational priorities observed across real production environments.