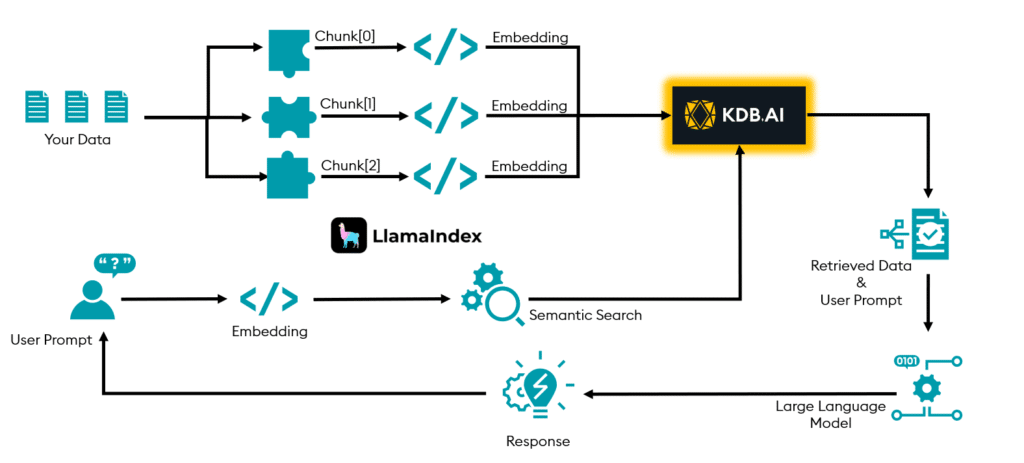
This blog explores how taking a factory-like approach can help your AI program achieve greater outputs and shares how you can assess your organization’s AI readiness.
This is the second part of a series of five “AI factory 101” posts where Mark Palmer describes the elements of an AI Factory and how any organization can implement one to catapult your organization into a fast, agile, innovative, healthy factory of AI algorithms. Read part one here.
“Model T customers can have any color they want, as long as it’s black.” To some, Henry Ford’s take on the Model T production was rigid, uninspired, and boring. Moreover, the Model T was painfully hard to start, slow, and had poor gas mileage.
However, Ford’s innovations were breathtaking to business leaders who looked under the hood. His approach to factory automation produced legendary breakthroughs. Build time was cut from 12 hours to 93 minutes, factory efficiencies helped slash prices by 70% – from $950 to $260, and output increased from 18,000 to 785,000 cars per year in just seven years.
High-performing AI leaders use factory-inspired ideas today to achieve similar results. A 2024 McKinsey & Company report shows that the high-performing firms (that have adopted AI) ascribe up to 20% of their EBIT (earnings before income and tax) to their use of AI and are twice as likely to employ ‘AI Factory’ concepts than laggards, 42% versus 19%.
Let’s explore how AI Factory thinking can help you achieve Ford-like results and how to assess your organization’s AI readiness to find and fill gaps.
Establishing AI readiness
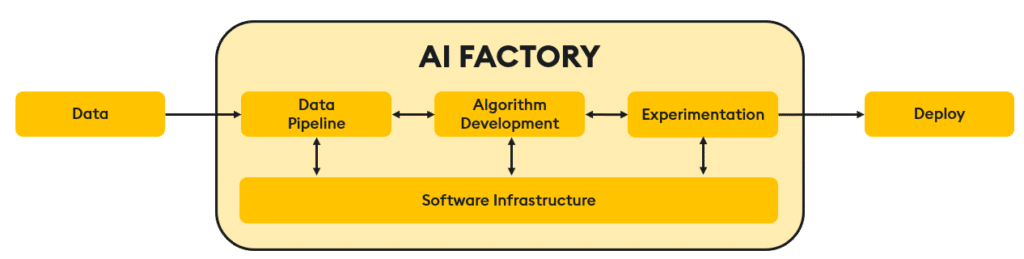
Harvard Business School professors Marco Iansiti and Karim Lakhani coined the term “AI Factory” in their book ‘Competing in the Age of AI‘. Their concept elevates the creation and use of AI like a factory, from data processing, algorithmic development, tools, an “AI Lab,” and production.
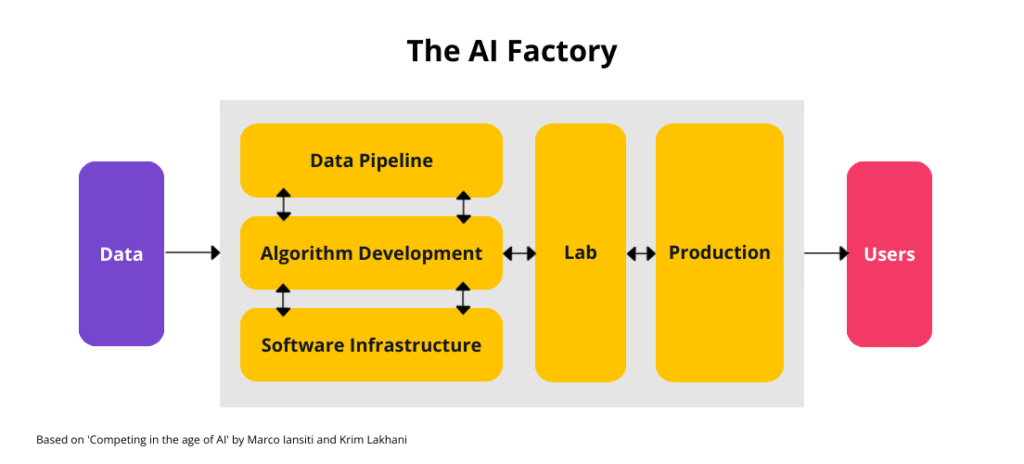
Instead of getting bogged down in a technical quagmire of algorithms, the notion of an AI factory helps leaders think of AI in a systems-thinking way – on the raw materials, experimentation, and the impact of AI on the business.
But how do you know if your organization is ready to adopt an AI factory approach? I would use the following assessment framework focusing on three key areas: Data pipelines, product development, automation and operations.
An AI Factory helps teams navigate an overgrown algorithmic jungle. Most organizations have too many models to choose from. For example, the AI model repository Hugging Face contains over 700,000 AI models with more being released every day. This vast number of options can confuse analysts rather than help them move more quickly.
An AI Factory helps teams automate and simplify the selection and use of the right LLM services for the job at hand. Let’s explore how.
Factory-like AI data pipelines
All factories start with raw materials. For cars, that means steel, sparkplugs, and rubber.
AI Factories start with raw materials too, in the form of data. New types of data. Specifically, unstructured data.
I’d wager a guess that most organizations have pipelines that weren’t designed to process interactions with customers, conversations, notes from salespeople, or social media sentiment. And that most organizations, until recently, have overlooked potential insights in audio, video, and images (safety monitoring based on video, drone footage for applications like crop management in agriculture, or computer-vision-aware automation and safety.)
AI leaders know that GenAI puts new demands on data pipelines. McKinsey found that leaders are 2.5 times more likely (42% versus 17%) to incorporate new data into existing pipelines to power LLMs than other adopters.
Here are five questions to ask to understand AI-readiness of your data pipelines:
- Do you systematically engage business users to discuss what new forms of data could help them build innovative AI-based applications and create a data roadmap to incorporate those new forms of data into existing or refined data pipelines?
- Have you reimagined your data pipeline to fuel AI with new types of data that it can uniquely integrate, clean, label, transform, augment, optimize, and publish unstructured data, including text, audio, streaming video, images, and IoT sensor data?
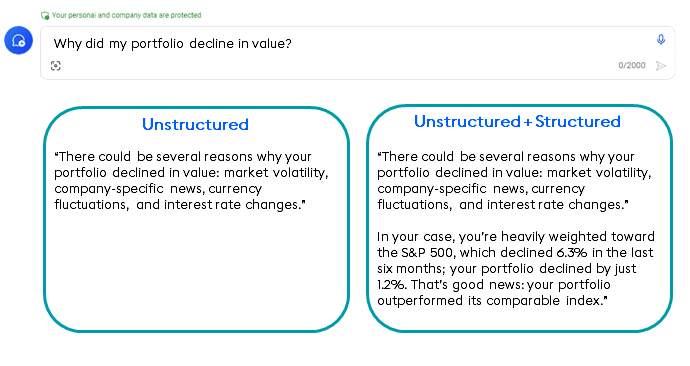
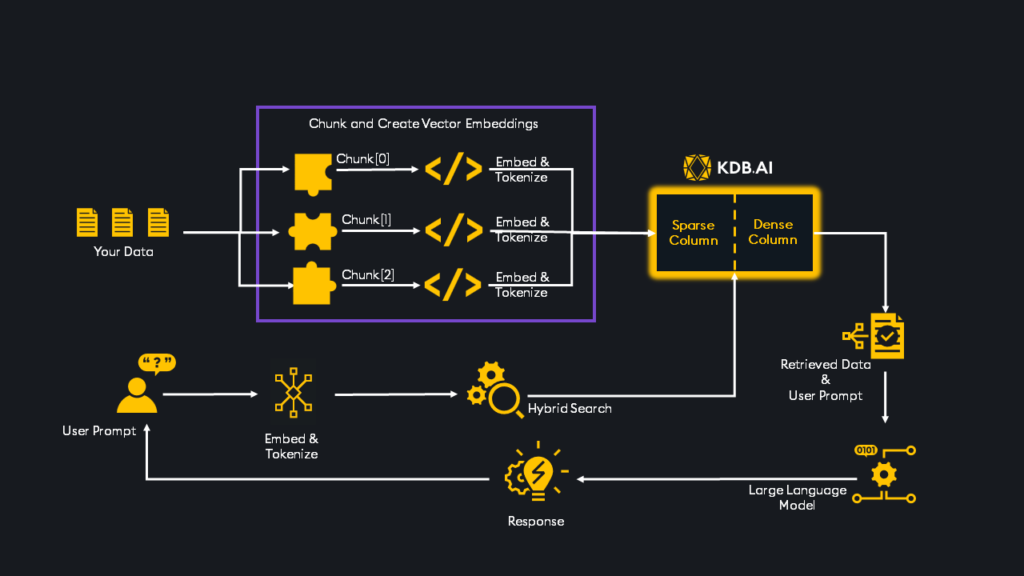
- Do you create vector embeddings in your data pipeline to process unstructured data and use Retrieval-Augmented Generation (RAG) to combine large language models (LLMs) with existing vetted data to enhance the accuracy and relevance of GenAI responses?
- Have you extended your data governance policies to include GenAI, LLMs, and RAG, including checks for accuracy, bias, privacy, hallucinations, and fairness?
- Is the data from these pipelines and the LLM applications that use it under a single version control system?
If you answered “no” or “I don’t know” to any of these questions, ask your Chief Data Officer to understand your data pipeline and how it’s been adapted for AI. Understanding the data you have at hand is the first step toward building an efficient AI Factory.
Factory-like AI development
Factories leaders carefully collaborate with designers, engineers, and product managers whose products they produce.
AI Factories are no different. Research shows that 46% of GenAI leaders focus on systems of AI production using tools, procedures, and training that encourage collaboration, compared to 15% of the general population of adopters. These include quality assurance, documentation, usage policies, rigorous A/B testing, champion/challenger optimization, and a culture of killing models that either don’t work in practice or drift and become ineffective.
Here are five questions to ask about how factory-like your AI development process is:
- Do you have a robust data science and machine learning platform that encourages cross-functional collaboration, automation, and co-pilot style creation of fast-start code?
- Do your processes include regular AI evaluation checkpoints to review AI performance, metrics, drift, efficacy, and cost and continuously refine them?
- Do you have a customer feedback loop that captures feedback about whether AI is producing fair, ethical, and unbiased recommendations, actions, and observations?
- Do you employ “Decision Observers” for AI (a term coined by Nobel Prize-winning behavioral economist Daniel Kahneman) who work with teams to identify ethical concerns and security issues?
- Are your AI monitoring tools available, not only to teams “inside” the factory (data science teams), but also to “customers” (the business users, customers, and teams that use AI’s output)?
Factory-like AI automation
Modern manufacturing operations are automated. They employ robotics to perform tasks that humans are either unable to do or are too dangerous to perform. They automatically monitor production yield and quality to raise exceptions to human operators. This automation helps speed production, improve quality, and spark innovation.
The same is true for AI factories.
In the case of AI, automation augments critical thinking and software development. Agents, co-pilots, and tooling help teams with code development, documentation generation, test coverage, and intelligent debugging. AI assists in data preparation, model optimization, and performance analysis. They can even help augment the user experience design process.
Here are five ways to check out how deeply you’ve embraced AI automation:
- Do you use AI agents to generate code snippets, suggest completions, create test cases, perform unit and integration testing, and help identify and fix bugs faster based on natural language descriptions?
- Do you use AI to fine-tune and optimize models, suggest improvements to architecture, choose hyperparameters, and select training data?
- Do you use AI to clean, preprocess, and augment datasets for training GenAI models?
- Do you use AI agents to generate and maintain documentation for code, APIs, user guides, and check for security vulnerabilities as projects evolve?
- Do you use AI to help design user interface mockups, suggest layouts, and predict user behavior?
By leveraging AI in these ways, developers can focus on high-level design and creative problem-solving. This leads to faster development cycles, higher-quality code, and more innovative applications.
Factory-like AI model operations and monitoring
In manufacturing, increased automation places greater demands on monitoring and exception handling.
Again, the same is true for AI factories, and research reveals that AI high-performers are jaw-droppingly advanced in their emphasis on AI operations and monitoring. McKinsey found that GenAI leaders are almost six times (7% to 41%) as likely to track, measure, and resolve AI model performance, data quality, infrastructure health, financial operations, and more.
Here are five questions to assess the AI-readiness of your operations and monitoring:
- Do you have a team that regularly evaluates the accuracy of your AI model’s predictions against ground truth data, helping identify performance degradation over time?
- Do you monitor for data drift (changes in the input data distribution) and prediction drift (changes in the output distribution), and regularly check data for missing values, anomalies, and inconsistencies that could affect model performance?
- Do you implement alerts for significant changes in key metrics such as accuracy, precision, recall, and F1 score?
- Do you have a regular feedback loop to continuously improve your model, using real-world data and user feedback to retrain and fine-tune it, ensuring it adapts to new patterns and trends?
- Do you schedule regular retraining sessions for your model using updated data to help mitigate the effects of concept drift and ensure that the model remains accurate and relevant?
These monitoring best practices of AI leaders help ensure your AI models remain robust, reliable, and capable of delivering accurate predictions in a dynamic real-world business environment.
AI factories produce innovation, energy, and ROI
To recap: assess your AI readiness by asking questions about your data pipelines, development processes, automation, and operations. By refining these elements, organizations can turn raw data into actionable insights, streamline productions, and ensure accuracy and relevance.
High-performing companies already leveraging AI Factory principles report substantial benefits, such as in 10% to 20% ROI and increased innovation. Keep the frameworks discussed in this blog in mind and, just like Ford, you’ll produce more AI output, drive down costs, and spark growth with AI that helps you lap the field in today’s digital racetrack.
For more information on what it takes to build an AI factory, read the first blog in the AI factory 101 series here. Discover why KDB.AI is a crucial part of the AI factory here.