By Bill Pierson
I recently attended the Advanced Semiconductor Manufacturing Conference (ASMC) where machine learning (ML) topics needed for the growth of smart manufacturing took center stage. The two overriding themes were solving specific semiconductor manufacturing problems using ML and incorporating people into the ML methodology. In the smart manufacturing panel discussion, Julie Jacob, a supply chain expert from Ernst and Young, stated that ML requires “smart people, smart process and smart technology.” Further, in a keynote presentation, James Moyne, a research scientist from the University of Michigan specializing in industrial networks and Big Data methods, stressed that subject matter experts (SME) are necessary for the knowledge network needed to build computational process control.
For this discussion, I will be focusing on why the SME is critical for the ML methodology. In a later piece, I will elaborate on examples of applying ML to specific manufacturing problems.
First though, I want to make some comments about ML in general. It is neither a silver bullet nor a black box. It is simply a set of tools to discover insights, understand correlations and solve problems. These problems generally require a toolbox or system to manage large amounts of relevant data that can be trained and used to validate algorithms. These algorithms are rapidly becoming prevalent in many industries; manufacturing is no exception where the supporting volume and velocity of data is enormous. This provides many opportunities and challenges for the manufacturing industry. However, it would be naïve to simply dump all the data into an ML system and expect it to churn out meaningful results. It is neither the tools nor toolbox that are most critical in deriving ML-driven insights; as both speakers above mentioned, it is the SME using them.
Semiconductor manufacturing is an ideal industry example to highlight why subject matter expertise is needed in ML approaches. This industry offers a fast moving, challenging and complex environment with new technology nodes and products every few years. This requires SMEs in design, integration, equipment, process and metrology to stay abreast of developments and constantly solve difficult problems. In addition, they have to address downstream and upstream impacts through the manufacturing line, all of which to improve factory cycle times, costs, and yield.
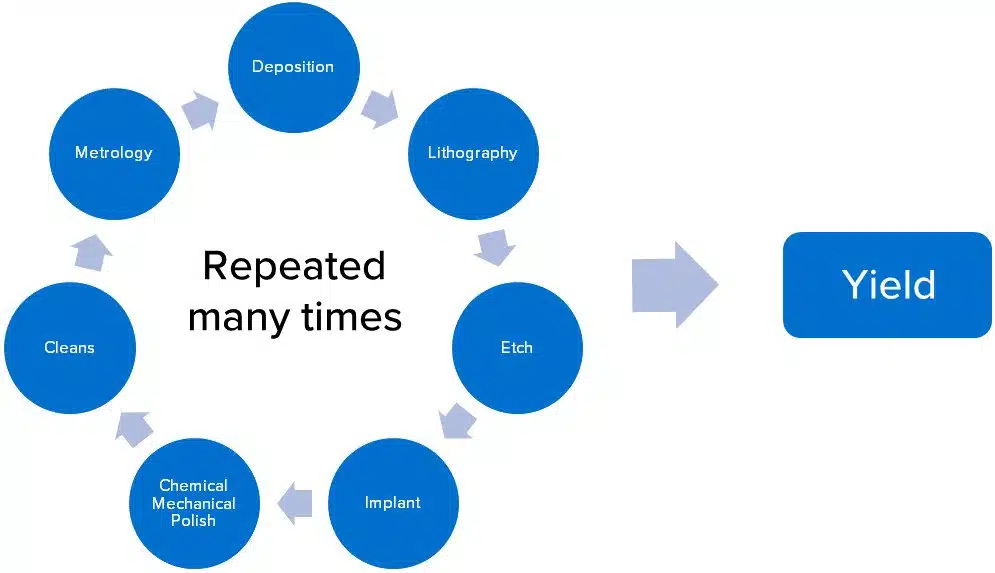
Generalized semiconductor front-end manufacturing process flow
SMEs are needed for ML projects since generalist data scientists cannot be expected to be fully conversant with the context, details, and specifics of problems across all industries. The challenges are often domain-specific and require considerable industry background to fully contextualize and address. For that reason, successful projects are typically those that adopt a teamwork approach bringing together the strengths of data scientists and subject matter experts. Where data scientists bring generic analytics and coding capabilities, SMEs provide specialized insights in three crucial areas: identifying the right problem, using the right data, and getting the right answers.
Identifying the Right Problem
Relevance is crucial in accurately defining and scoping the problem being addressed. Since semiconductor manufacturing is a complex interaction of processes and their variations, it is important to understand the core problem in order to determine the problem to be solved. Only the subject matter expert can simplify the problem and narrow the scope to what is relevant so that an appropriate solution can be quickly identified and pursued. Moreover, the subject matter expert can provide insights into suspected cause-and-effects that can be used to further refine the scope. They can then determine if a problem can be solved using known standard methods or if it requires advanced data mining and/or model selection techniques, aka machine learning.
Using the Right Data
As W. Edwards Deming said, “In God we trust, all others must bring data.” Today’s semiconductor fabs, manufacturing plants in which raw silicon wafers are turned into integrated circuits, have enormous and expanding quantities of sensor and parametric data. Therefore, the phrase, ‘garbage in, garbage out’ becomes equally applicable and directly impacts the performance of feature engineering in the ML methodologies. For that reason, SMEs are crucial in deciding which data to use and how it should be interpreted. For example, the data points need to be relatable to each other and factors such as spatial and temporal labels and filtering need to be reconciled.
To further enhance the performance of ML initiatives, the subject matter experts can identify correlated parameters in advance to help reduce the data sets required to be transformed into features. Feature engineering‘s goal is to transform these millions or billions of data points into hundreds or thousands of manageable features in order to execute the ML models by the data scientist.
Getting the Right Answers
Subject matter expertise is crucial in ensuring that ML projects focus on the right problem to address, the appropriate data to use, the correct interpretation of their results and how they can be used to create solutions for the factory via fault detection, process/tool optimizations, or process control schemes.
As James Moyne highlighted, computational process control requires a cross-functional team of SMEs in analytics, data, equipment, and process to operate efficiently in the first place. Their experience – and sometimes tacit – knowledge is similarly needed to help improve ML models. This applies throughout the project from the initial feature selection and extraction phases where determining relevance is key to finally assess the model accuracy and prediction, specifically in the identification of Type 1 and Type 2 errors and where the model may need to be retrained.
As ML projects become more commonplace, we should remember that it is the caliber of the user of the tools and not the actual tools that will determine their success. There needs to be a combination of subject matter experts’ and data scientists’ skills and experience to develop solutions that add value in relevant areas like lowering cycle times, lowering costs, and/or improving yield.
KX is focused on providing an ML toolbox for the subject matter expert to obtain results accurately and quickly. The high-performance database platform kdb+, open source ML interface EmbedPy, and pool of experienced data scientists at KX provides clients the ability to ingest massive amounts of data, analyze it to create insights, and generate applied solutions for the manufacturing business.
Bill Pierson is VP of Semiconductors and Manufacturing at KX. He has extensive experience in the semiconductor industry and specializes in applications, analytics and control. Bill is based in Austin, Texas.



